Dernière modification : 8.1.2025
Introduction
J’ai commencé le nouvel an 2024 avec la création d’un livre illustré, dédié à mes petits-enfants.

Depuis le 28 janvier 2024, le livre est en vente sur les librairies en ligne, par exemple sur la librairie de Books on Demand (BoD).
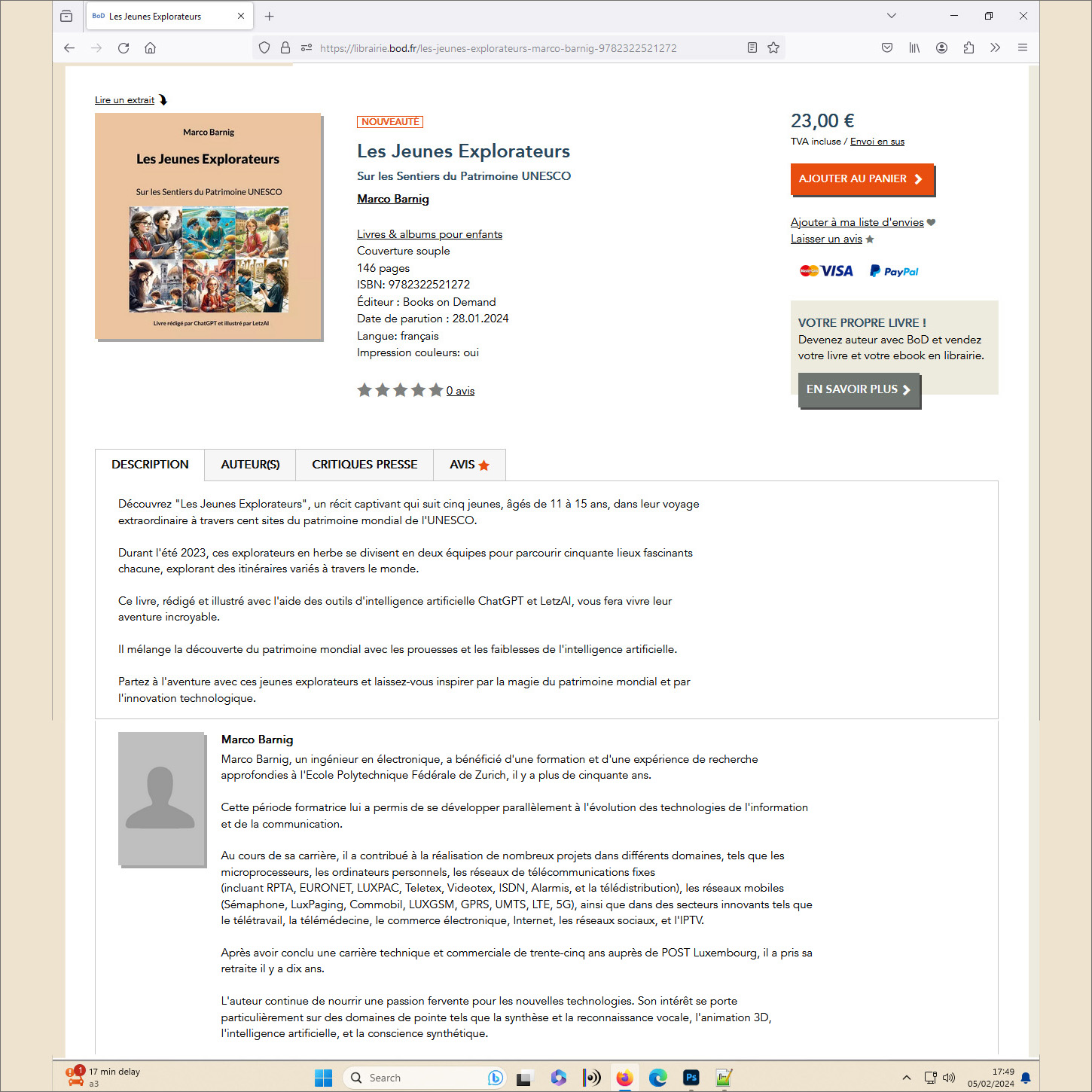
RTL Lëtzebuerg a diffusé le 7 mars 2024 dans son magazine du soir un reportage au sujet de mon livre.

On peut revoir la vidéo dans la rubrique Culture sur le site web de RTL avec le lien https://www.rtl.lu/kultur/news/a/2174401.html.
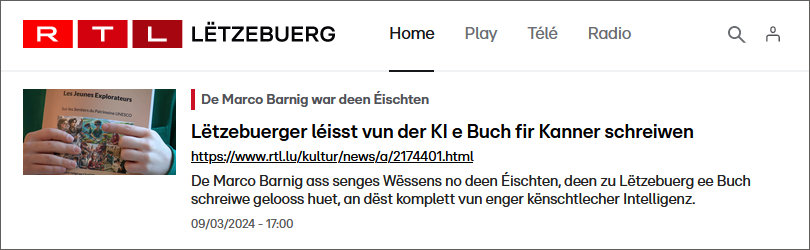
L’Essentiel a publié le 10 avril 2024 dans son journal et sur son site web des articles en français et allemand au sujet de mon livre et de mes autres activités AI. Merci à la journaliste Marion Mellinger pour son reportage pertinent, bien écrit et bien présenté.

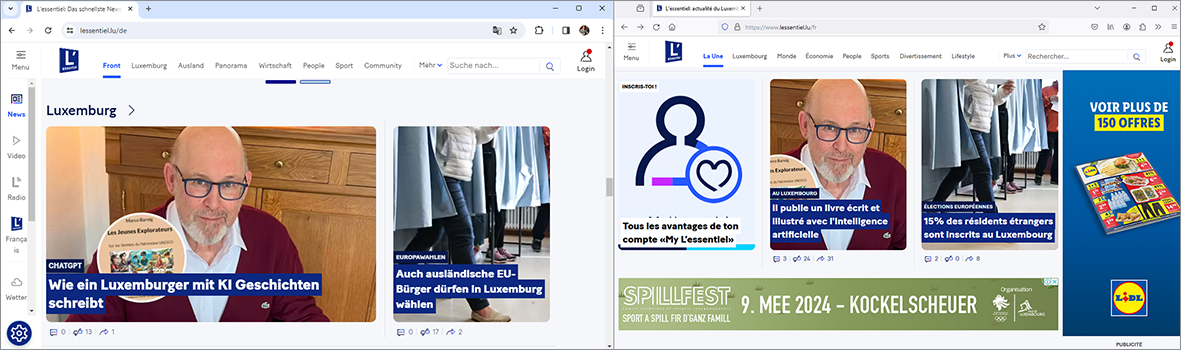
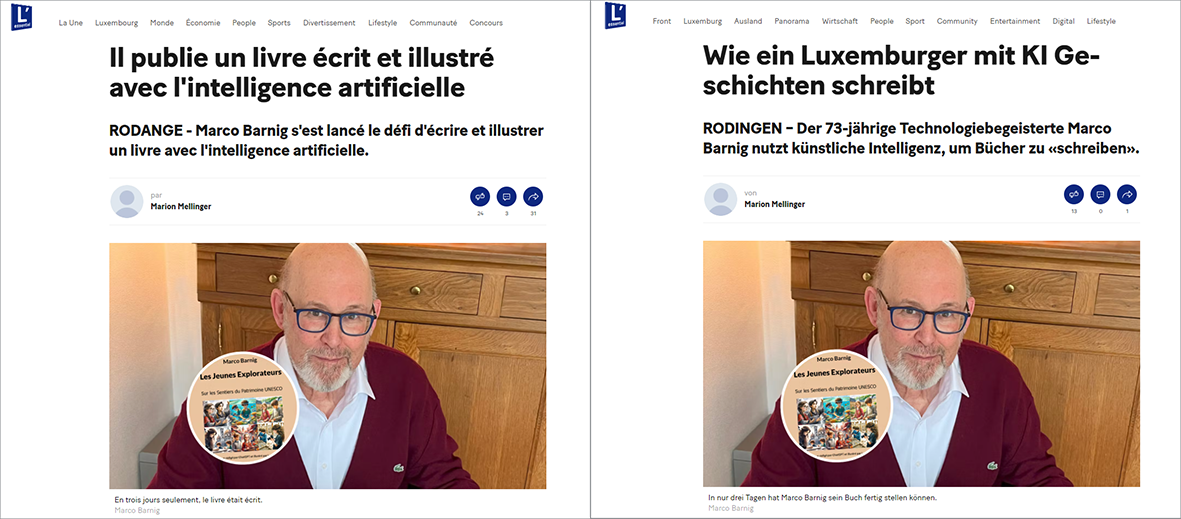
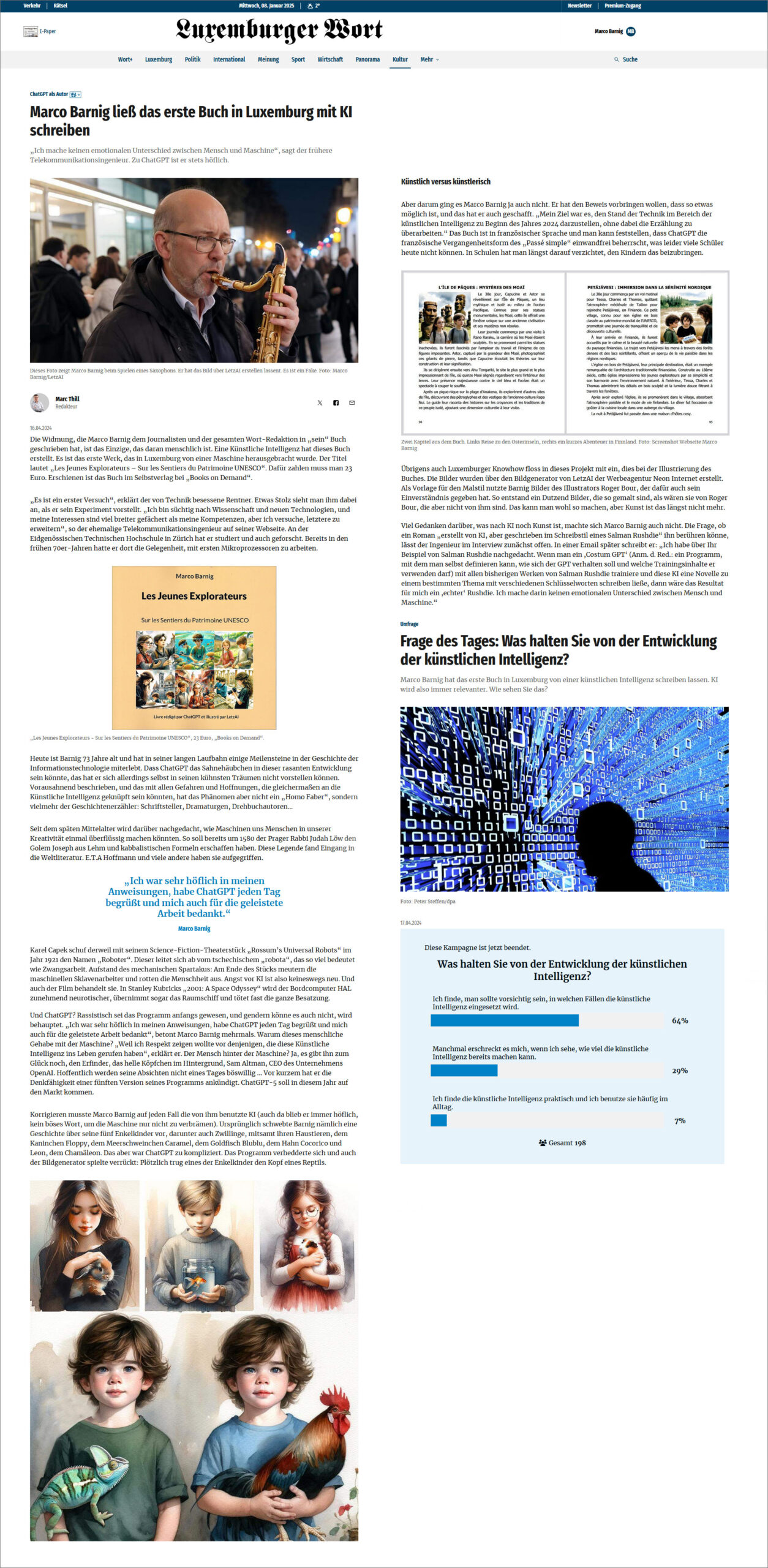
Le Luxemburger Wort a publié le 16 avril 2024 un article en allemand sur le livre. Merci au journaliste Marc Thill pour son reportage critique.
Inspiration
L’inspiration de créer un livre d’aventures pour les jeunes, moyennant des outils d’intelligence artificielle, m’est venue fin février 2023, lorsque Thierry Labro, rédacteur en chef de Paperjam, a publié son roman futuriste “Ils ont tué mon avatar !“, conçu en une heure par ChatGPT et illustré par Dall-E. À cette époque, l’intelligence artificielle, bien qu’avancée, ne permettait pas encore de créer des images en haute résolution ou de rédiger de longs textes de manière cohérente.
LetzAI
L’été 2023 a marqué un tournant avec la présentation de LetzAI, un générateur d’images luxembourgeois révolutionnaire, basé sur l’intelligence artificielle. Ce progrès majeur permettait pour la première fois d’entraîner un modèle de manière fiable et aisée avec ses propres personnages, pour produire ensuite des illustrations fidèles et harmonieuses.
Début septembre 2023, j’ai découvert LetzAI pendant mon petit déjeuner, lors de la lecture de l’article “Hier wird der Großherzog zu Iron Man” dans le Luxemburger Wort. Les jours suivants, presque toute la presse (Adada, Paperjam, Farvest, Virgule, RTL, 100Komma7, …) présentait le projet. Dans la suite, les média continuaient de parler de LetzAI (Page, Forbes, …). L’assemblage d’images, générées avec LetzAI, qui suit, donne un aperçu sur les différents modèles disponibles lors du lancement public du projet.

Equipe de création
Les créateurs de LetzAI sont les spécialistes de l’agence de communication Neon Internet. Il s’agit de Misch Strotz (chief executive officer), Karim Youssef (chief marketing officer), Sacha Schmitz (chief content officer), Ricardo Prosperi (agency manager), Jacques Weniger (chief operating officer), Julie Wieland (lead designer), Carlos Gonser (chief technology officer), Kim Feyereisen (graphic designer), Daniel Wahl (lead developer), Torge Schwandt (business consultant), Laura Seidlitz (content creator), Michael Klares (video editor), Mathieu Schiltz (business consultant).


Neon Internet
Neon Internet se présente comme agence hybride marketing et technologie. Elle a été co-fondée par Misch Strotz et Karim Youssef en 2018. Sacha Schmitz est partenaire dans la société. Lors de la 7ème édition du Concours de l’Innovation dans l’Artisanat en 2022, organisée par la Chambre des Métiers, Neon Internet a obtenu le prix dans la catégorie Gestion/Organisation/Management pour le développement d’un écosystème d’outils de marketing en ligne, appelé Neontools. Cette application est utilisée par plus de 75.000 créateurs et entrepreneurs à travers le monde.

Une autre offre de l’agence est le site web Neon Academy, qui propose des cours de formation et des conseils sur le marketing en ligne.
Maach eppes Lëtzebuergesches
LetzAI a été annoncé sous la devise Maach eppes Lëtzebuergesches, mat LetzAI. Les modèles de génération d’images, présentés au début, se référaient à des produits luxembourgeois comme la Bouneschlupp, les Gromperekichelcher, les bières Battin et Diekirch.






D’autres modèles permettaient de créer des scènes avec des politiciens, par exemple avec l’ancien et le nouveau premier ministre. Des séances photo pour capter les portraits des personnages consentants, aux fins d’entraîner les modèles AI, ont eu lieu pendant les vacances d’été.






D’autres personnes de la vie publique ne manquaient pas, un cardinal, des athlètes, des acteurs, des artistes, des entrepreneurs.






Enfin et surtout on y trouvait des célébrités emblématiques comme Superjemp, Yuppi et Boxemännchen.





Bien sûr les développeurs de LetzAI participaient également au jeu avec leurs propres modèles. Je laisse le plaisir aux lecteurs de deviner les noms des créateurs présentés ci-après.









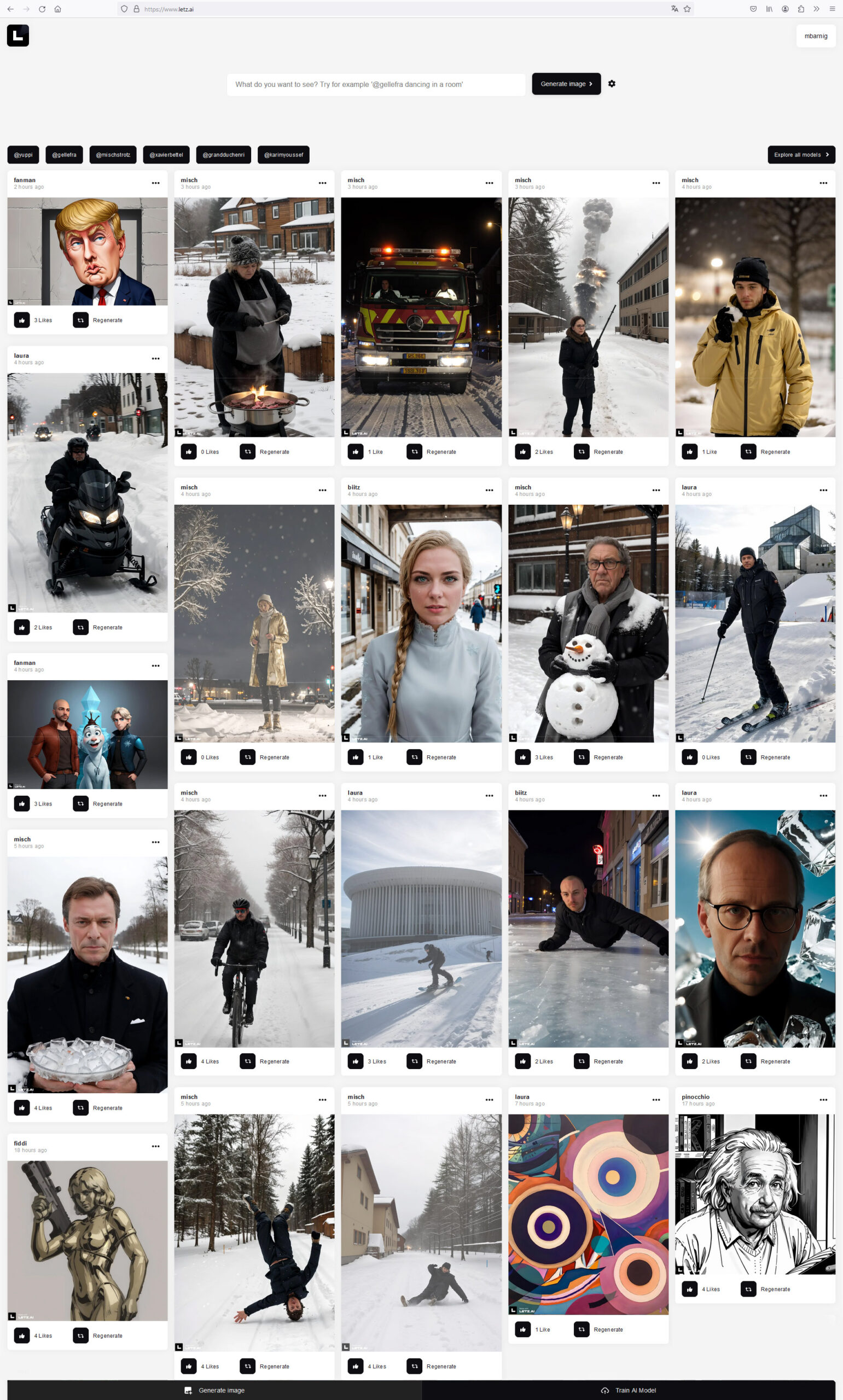
L’ensemble des images publiques générées peut être visualisé dans le “Feed” sur la page web de LetzAI.
Réseaux sociaux
Comme Neon Internet est un spécialiste de la communication sur les réseaux sociaux, il est évident que LetzAI se présente sur tous les canaux : Facebook, Instagram, LinkedIn, X(Twitter), Youtube et TikTok.
LetzAI sur RTL Lëtzebuerg
Des reportages au sujet de LetzAI ont été diffusés sur RTL Radio le 21 septembre 2023.
Le 18 octobre 2023, un entretien avec Misch Strotz au sujet de LetzAI a été diffusé sur RTL Télé.
Early Access
LetzAI a été lancé fin août/début septembre 2023 en mode Early Access. L’achat d’une clé d’accès, à un prix forfaitaire, permettait de générer des images et de créer des modèles à discrétion. J’étais parmi les premiers usagers à profiter de cette offre. Évidemment, le premier modèle que j’ai entraîné était basé sur des photos récentes de moi-même, dans différentes poses et sous différents angles de vue. J’étais ravi des premiers résultats.









Mon premier modèle public @steampunkluucht permettait de générer des images synthétiques de lampes steampunk, dans le style des lampes réelles construites par Gast Klares. Ce bricoleur et artiste génial m’a autorisé à utiliser les photos, en haute résolution, de ses 86 lampes présentées sur son site web. Ensuite j’ai fouillé dans mes archives d’anciennes photos et diapositives pour trouver des motifs pour des modèles LetzAI à créer, par exemple les sculptures de Niki de Saint Phalle (@sculpturesnikidesaintphalle), installées dans la capitale lors de l’année culturelle 1995. Une autre collection se réfère à l’exposition de 103 vaches (@artoncows), décorées par des artistes et installées à travers la capitale en 2001. Avec des photos prises de fleurs (@flowers) et de mannequins de vitrine, j’avais épuisé les collections de photos dans mes archives, qui se prêtaient pour entraîner des modèles LetzAI.












Pour explorer d’autres pistes, j’ai effectué des randonnées dans les environs pour photographier la nature et l’architecture, notamment dans la Réserve naturelle Giele Botter (@gielebotter) et dans le nouveau quartier urbain Esch-Belval. Le modèle @eschbelval était le premier que j’ai combiné avec un autre modèle, à savoir @flowers, pour générer des images imaginaires d’Esch-Belval fleuri. Le Luxembourg Learning Center (LLC), qui abrite la bibliothèque universitaire, se prêtait pour la création d’un modèle LetzAI d’architecture intérieure @learningcenter.












Après une déviation dans le monde animal avec le modèle @black_cat, entraîné avec des photos du chat noir Billy de mon beau-fils, c’était le tour des artistes pour être mis en scène. Le premier était Rosch Bour de Lamadelaine, un multitalent : auteur de plusieurs livres, peintre, dessinateur, illustrateur, musicien, historien, archiviste, acteur de théâtre et athlète. Pour le 150e anniversaire des chemins de fer en 2009, ses aquarelles de locomotives figuraient sur des timbres de POST Luxembourg. Rosch m’a autorisé à utiliser un échantillon de ses aquarelles et de ses fusains pour l’entrâinement des modèles AI @watercolor_by_roger_bour et @charcoal_by_roger_bour. Ainsi lui-même, il a pu ajouter un titre supplémentaire à son palmarès: premier artiste peintre figurant sur LetzAI. Le deuxième artiste est mon ancienne collaboratrice Céline Kruten. De formation ingénieur-multimédia, elle a changé de métier il y a quelques années pour devenir créatrice d’art floral. Elle a fondé son propre entreprise Les Herbes Folles – Floral Design pour créer des décorations florales et pour organiser des événements particuliers, comme des mariages ou banquets. Céline m’a autorisé à sélectionner des photos d’arrangements florales dans le portfolio sur son site web pour créer le modèle LetzAI @les_herbes_folles. Les images générées avec ce modèle ont toutefois du mal à reproduire la beauté, la délicatesse et le naturel des vraies créations florales de Céline.












Le troisième artiste est Harold Cohen, un pionnier à la confluence de l’intelligence artificielle et des arts visuels. En 1972, il a développé AARON, un programme informatique révolutionnaire conçu pour générer de manière autonome des peintures et des dessins. Son croisement innovant de la créativité informatique et de l’art traditionnel lui a valu une renommée internationale, son travail étant présenté dans de nombreuses expositions dans des musées prestigieux du monde entier. En reconnaissance de ses contributions, Harold Cohen a reçu de nombreuses distinctions, tout au long de sa carrière.
Né au Royaume-Uni en 1928, Harold Cohen a déménagé aux États-Unis, où il a partagé son expertise et sa passion pour l’art et la technologie à l’Université de Californie, de 1968 jusqu’à sa retraite en 1998. Même après sa retraite, il est resté activement engagé dans le développement d’AARON, améliorant ainsi ses capacités et sa complexité. Initialement, le programme a été développé en C, mais il est ensuite passé au LISP pour exploiter ses puissantes fonctionnalités pour le développement de l’intelligence artificielle.
Dans les semaines qui ont précédé son décès en 2016, Harold Cohen s’est lancé dans une nouvelle aventure avec AARON, intitulée de manière ambitieuse « La peinture au doigt pour le 21e siècle ». Alors que les premières années l’ont vu utiliser des traceurs x-y pour donner vie aux créations d’AARON, dans les années 1990, il avait conçu une série de machines de peinture numérique. Son évolution continue dans le médium a vu un passage aux imprimantes à jet d’encre et finalement aux écrans tactiles dans son projet final, cherchant toujours à mélanger la technologie avec l’essence tactile de la peinture.
Ray Kurzweil, un éminent informaticien et futuriste américain, a introduit l’héritage de Harold Cohen dans l’ère numérique en développant un programme d’économiseur d’écran AARON en 2000, adapté aux ordinateurs Windows. Ce programme fonctionne encore aujourd’hui sous Windows 11, en mode compatibilité Windows 98. La création de mes propres images AARON, avec le logiciel de Ray Kurzweil m’a permis d’entraîner mon modèle @aaron_by_harold_cohen dans le respect des droits d’auteur pour les oeuvres originales de Harold Cohen. Ray Kurzweil a réalisé en 1987 le film documentaire The Age of Intelligent Machines qui présentait l’état d’art de l’intelligence artificielle à cette époque.






Un créneau que je n’avais pas encore exploré étaient les dessins animés. J’ai effectué un premier essai avec Big Buck Bunny, le protagoniste d’un court métrage néerlandais, réalisé en 2008 par Sacha Goedegebure, exclusivement avec des logiciels libres, dont principalement Blender. Le film, ainsi que l’ensemble des fichiers source et matériaux ayant servi à sa réalisation, ont été publiés sous licence Creative Commons. Comme j’étais moi-même à l’époque créateur 3D sur le web pendant mon temps libre, je dispose de toutes les images du film en haute résolution et c’était facile de créer le modèle LetzAI @big_buck_bunny.



Mon deuxième modèle LetzAI de dessin animé est @velo_cartoon. L’origine de ce modèle remonte à l’été 2022, lorsque j’ai été admis comme testeur-beta pour le générateur d’images DALL*E2 par OpenAI. Ma première image a été générée avec le prompt “cartoon of an elephant and a giraffe riding a bicycle on the beach” et publiée le même jour sur Facebook. Dans la suite j’ai utilisé régulièrement le même prompt pour tester d’autres générateurs d’images comme Dreamstudio, Craiyon, Midjourney et Stable Diffusion.





La galerie qui suit présente quelques images générées avec des modèles LetzAI qui ne sont pas encore à point (@animal_croissant, @artpet, @birthday_cake, @letz_postage_stamps, @minerals, @naive_art, @vase et @vintage_toy) ou qui se trouvent encore en mode privé, notamment les modèles de mes portraits comme bébé, enfant et jeune adulte ainsi que celui des mannequins.





















Je clôture ce chapitre avec l’affichage de quelques captures d’écran, exposant les photos utilisées pour entraîner des modèles.


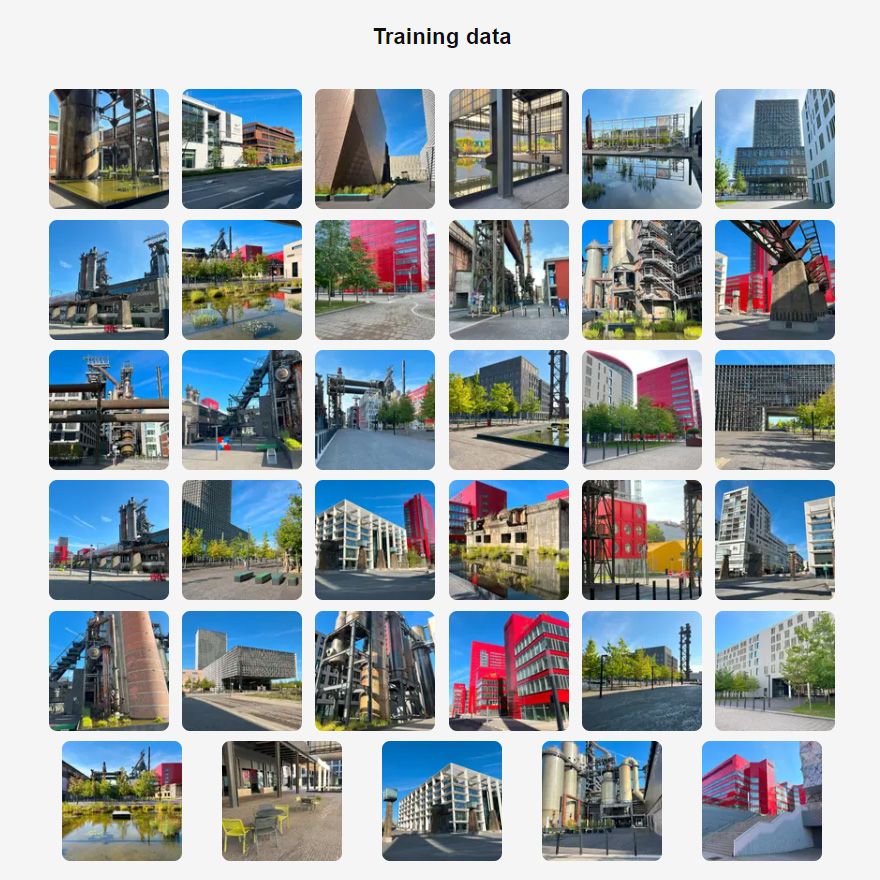
Lors de la période Early Access, j’ai donc pu acquérir les compétences pour faire face au défi de création des illustrations pour le livre d’aventure pour mes enfants.
Animations et vidéos
À côté de la génération d’images fixes avec les outils d’intelligence artificielle, j’ai également commencé à sonder les possibilités de créer des animations et des vidéos avec ces applications. En décembre 2022, j’ai réalisé ma première vidéo avec un générateur text2video, en spécifiant le prompt “A panda playing chess on the beach“. Certes ce n’était pas encore un chef d’oeuvre, mais c’était un début promettant. Avec une image de Big Buck Bunny, j’ai produit plusieurs animations. La première est une synchronisation labiale en langue anglaise. Le deuxième exemple est synchronisé avec une voix synthétique française, la troisième animation parle luxembourgeois, avec ma propre voix. Ensuite c’était mon MiniMoi, une petite figurine de 20 cm, imprimée en 3D à mon effigie, qui apprenait à parler luxembourgeois. Après les élections en octobre 2023, Superjemp, qui avait déjà appris à parler luxembourgeois, racontait avec une voix synthétique qu’il venait de voter la liste 19. Dans tous les cas, j’ai utilisé l’outil AI HeyGen pour réaliser ces animations.
Début novembre 2023, j’ai animé quatre images du Boxemännchen, générées par Sacha Schmitz, moyennant la nouvelle version du module Text + Image2Video Gen-2 de Midjourney.
Début 2024, les générateurs vidéo, basés sur l’intelligence artificielle, n’étaient pas encore à un niveau pour pouvoir envisager la réalisation de longs métrages, même pas des courts métrages, mais les fondations étaient posées. Tout a changé le 15 février 2024 quand OpenAI a présenté son générateur SORA qui permet de générer des vidéos d’une durée de 60 secondes, avec une qualité époustouflante. J’espère pouvoir enchaîner dans les prochains mois sur mon livre d’aventures pour créer un film animé des jeunes explorateurs, à l’effigie de mes petit-enfants.
Incident avec Mélusine
Retournons à LetzAI. Début octobre 2023, une première communication visuelle, réalisée avec l’outil LetzAI, a été lancée par l’agence Wait, pour le compte de wortimmo.lu, le site internet immobilier du Luxemburger Wort. La campagne présentait Mélusine, la sirène magenta du modèle polygonal 3D «low-poly», créé par Serge Ecker en 2013, installée dans le quartier du Grund au bord de l’Alzette. La campagne avait un défaut : l’artiste n’a jamais été contacté pour l’utilisation de l’image de son œuvre. Serge Ecker s’est référé à la loi de 2001 sur les droits d’auteurs et la campagne est rapidement disparue des supports de publicité et des pages web.
Luxembourg Artweek
La neuvième édition de la foire Luxembourg Artweek s’est déroulée du 10 au 12 novembre 2023. C’était l’occasion pour LetzAI de s’adresser au public. Dans le cadre de l’ArtTalk “Art and New Technologies“, Misch Strotz présentait la plateforme LetzAI et il a démystifié les systèmes d’intelligence artificielle créatifs dans le monde de l’art. La démonstration était suivie par la projection du film Artist Alain Welter tries LETZ.AI.
Ensuite la parole fut donnée aux artistes luxembourgeois présents sur le plateau : Lynn Klemmer, Eric Mangen et Serge Ecker. La discussion entre Misch Strotz, les artistes et le public fut modéré par Hinde Baddou. Le débat était animé et de haut niveau et a permis de dégager les différents sentiments des artistes par rapport aux générateurs d’images, entraînées avec leurs propres œuvres. Serge Ecker a saisi l’occasion pour revenir sur sa réaction au sujet de la campagne publicitaire ratée avec sa sculpture Mélusine. “I would rather cut off my foot than train a public AI model on my art” était une de ses déclarations.
Démarrage beta
Début décembre 2023, LetzAI est entré dans une phase de beta publique. Lors d’une release party le soir du 3 décembre 2023, en présence de la Gëlle Fra, de Yuppi, de Superjemp et d’autres célébrités, les conditions d’utilisation de la plateforme ont été dévoilées. Trois formules d’abonnement, avec facturation mensuelle, sont proposées : Beginner, Fun et Pro. Pour les indécis, la formule Just Testing, au prix de 4,90 € sans engagement, permet de créer environ 30 images. Pendant la phase beta, les quatre formules permettent la création d’un nombre illimité de modèles.
Challenge AI mam Kleeschen
Pour la fête de Saint Nicolas, LetzAI avait lancé son premier concours parmi les anciens et nouveaux usagers. Le défi consistait à créer une image avec le modèle public @kleeschen, plébiscité par l’ensemble des usagers. Plus que mille images furent générées. Le vainqueur était Timothy Bettega, le jeune fondateur du Guide Luxembourg et de Black Thunder, une agence événementielle luxembourgeoise visionnaire.
La galerie ci-après présente l’image couronnée muscular @kleeschen doing a deadlift (en haut à droite), ainsi qu’une sélection d’images de @kleeschen dans d’autres scènes.















Marché Augenschmaus
Quelques jours avant Noël 2023, la quatrième édition du marché des créateurs Augenschmaus a eu lieu dans les Rotondes. Le Jingle Mingle X‑Mas Market by Augenschmaus était une occasion unique pour trouver un cadeau original à mettre sous le sapin. On y trouvait une sélection de créations uniques et de produits artisanaux, tous imaginés avec talent par des artistes, designers et producteurs locaux. LetzAI était présent sur ce marché avec un stand de démonstration de sa plateforme de génération d’images. L’équipe de Neon Internet a eu un grand plaisir de présenter les oeuvres, générées par l’intelligence artificielle, au public.



Evolution LetzAI
Le début du nouvel an 2024 était le moment idéal pour l’équipe de LetzAI d’annoncer plusieurs améliorations de la plateforme. En premier lieu c’était une extension des dimensions des images générées. Dans le passé, le format imposée était un carré de 1080 x 1080 pixels. Maintenant, la sélection de formats “portrait” ou “paysage” est également possible, avec une hauteur ou une largeur maximale de 1600 pixels. On peut également varier deux paramètres pour régler la “créativité” et la “qualité“. C’était le signal de départ de la création de nombreux nouveaux modèles par les usagers, surtout des styles à appliquer à des modèles d’objets ou de personnages. Je n’ai pas pu résister pour créer quelques portraits de moi-même dans différents styles d’images.






Annonce de LetzAI V2
En mi février 2024, LetzAI a annoncé l’introduction d’une nouvelle version V2, plus polyvalente et plus performante que la version 1, qui est commercialisée depuis décembre 2023. La résolution maximale d’une image générée a été augmentée jusqu’à 1.920 x 1.920 pixels.
L’interprétation de la description (prompt), pour générer une image, a été sensiblement perfectionnée, ce qui permet de créer des images d’une précision et d’une qualité étonnantes. Quelques créations réalisées par Misch Strotz, le développeur principal de LetzAI, sont présentées ci-après, avec affichage du prompt spécifié.

sculpted, thick volume, french model, white background

oranges and lemons, color: dark green and gold, background: dark and luxury, hyper detailled, stil: raw, cinematic light, canon, expressive and original, canon,
50 mm lens, editorial, look: expensive, mood: motivated and good vibes

8k, text : “apx-390”, scene from bladerunner 2049
Cliquez sur l’image en haut pour l’agrandir, utiliser la souris pour scroller le prompt.
Le processus de création des modèles LetzAI personnels, publics ou privés, a également été amélioré. Le nombre de photos ou d’illustrations requis pour entraîner un modèle V2 a été réduit. La définition du type d’image, demandée lors de l’activation du modèle, est devenue plus granulaire, ce qui garantit une meilleure fidélité. L’accès public à la plateforme LetzAI V2 est prévue pour début mars 2024. Reste à signaler que les modèles V1 existants sont compatibles avec la version 2.
Partenariat LetzAI – Gcore
Le 21 février 2024, LetzAi a annoncé sur les réseaux sociaux et sur son blog qu’un protocole d’accord, pour un partenariat stratégique, a été signé avec le fournisseur luxembourgeois de cloud et d’IA Gcore, situé à Contern. Grâce à ce partenariat, LetzAI peut étendre les capacités de sa plateforme actuelle, servir plus d’utilisateurs et permettre des cas d’utilisation professionnels.
L’objectif de LetzAI est de fournir une plate-forme qui est non seulement amusante à utiliser, mais qui aide également les professionnels du marketing à accélérer considérablement leurs processus créatifs.
La version V2 de LetzAI constitue déjà une des plateformes d’intelligence artificielle générative les plus inclusives au monde. Au cours des dernières semaines, Gcore a mis son infrastructure GPU Nvidia H100 à disposition de LetzAI pour le développement et l’entraînement de la version V2. Pour le lancement, Gcore fournira des GPUs L40S.
Le partenariat LetzAI-Gcore conclu prévoit d’offrir la technologie LetzAI sur le plan international. À ces fins, Gcore fournira des services de pointe d’une infrastructure GPU, avec 160 points de présence dans le monde entier, en commençant dans les pays voisins comme Allemagne, France et BENELUX.

Commercialisation internationale de la version 2 de LetzAI
Après une phase de test intensive, LetzAI a annoncé le 5 mars 2024 l’introduction commerciale de la version 2 de son générateur d’images non seulement au Luxembourg, mais dans toute l’Europe. Cette version a le potentiel de révolutionner le marché de la génération d’images par l’intelligence artificielle. Ce n’est pas seulement l’avis des développeurs luxembourgeois de LetzAI, mais celui des meilleurs spécialistes et créateurs internationaux dans le domaine de l’ingénierie AI artistique, parmi eux Julie Wieland, Sarah Vermeulen, Mark Isle, Jesús Plaza, Allar Haltsonen et Halim Alrasihi.

Avec cette information, je termine le récit de l’histoire de LetzAI. Mais cette plateforme constitue seulement la moitié des outils requis pour la réalisation de mon projet de livre “Les Jeunes Explorateurs“. L’autre moitié est ChatGPT, que je vais présenter dans le prochain chapitre.
ChatGPT
Ma première rencontre avec ChatGPT a eu lieu au printemps 2022. J’ai demandé au modèle GPT-3 la génération d’un article au sujet de la guerre qui venait d’éclater entre les créateurs d’oeuvres d’art plastiques et les générateurs d’oeuvres d’art synthétiques. Quelques mois plus tard, j’ai publié sur HuggingFace (une plateforme de collaboration AI renommée), une application qui permettait de générer un poème en langue luxembourgeoise.

Rapidement je suis devenu un utilisateur régulier de ChatGPT et j’ai suivi toutes les évolutions de cet outil de traitement et de génération de textes. Sur les réseaux sociaux, j’ai écrit des contributions au sujet de thèmes variés : génération d’un poème concernant un chien qui est tombé amoureux d’un grille-pain, illustration de ce poème, hallucinations des modèles de langage AI, essai au sujet du cerveau écrit dans la manière d’un élève, rédaction d’un résumé d’un article sur le web, dialogues entre robots, fables de Jean de la Fontaine, messages dans une bouteille.
En décembre 2023, j’ai rédigé une contribution étoffée sur mon site web au sujet de l’évolution de ChatGPT qui progresse avec des bottes de sept lieues : De gestiwwelte ChatGPT. Je recommande à tous les lecteurs qui sont intéressés à plus de détails au sujet de l’histoire, de la technique et des créateurs de ChatGPT, de lire cet article.



Personnalisation de ChatGPT
Il y avait une compétence qui manquait à ChatGPT, à savoir la possibilité d’ajouter ses propres documents et informations, pour étendre son savoir. Cette faculté est indispensable si on souhaite générer des textes avec des connaissances spécifiques ou créer des récits autobiographiques, sauf si on est une célébrité bien documenté sur le web. Lors de la mise en ligne de ChatGPT en automne 2022, la date limite de ses connaissances était septembre 2021. En 2023, les connaissances ont été actualisées jusqu’en janvier 2022, lors d’une mise à jour discrète de ChatGPT. Le processus d’entraînement d’un modèle AI géant de langage comme ChatGPT, avec un corpus qui comprend tout le contenu du web, ainsi qu’un nombre énorme de livres, prend plusieurs mois, sur les ordinateurs les plus puissants qui existent, et il coûte une fortune.
En été 2023, OpenAI a ajouté une option à ChatGPT permettant d’accéder à des informations sur le web. En outre deux entreprises, Dante.ai et Berri.ai, proposaient une interface à ChatGPT pour ajouter son propre contenu à ce robot de dialogue. C’était un premier pas dans le bons sens. J’ai décrit mes propres expériences avec ces outils dans mon article “Ech hunn haut mam Dante AI gechatt !“.
Evolution de ChatGPT
Tout a changé le 6 novembre 2023, lorsque la première conférence de développement OpenAI a eu lieu. Sam Altman, le CEO de OpenAI, présentait une série d’innovations et une réduction sensible des prix pour l’utilisation des produits de son entreprise. Un des atouts était la conversion de ChatGPT en modèle AI multimodale ChatGPT-4, avec l’intégration du module DALL*E3 pour générer des images, du module Vision pour analyser et décrire des images, des modules Voice (TTS) et Whisper (ASR) pour parler avec une voix synthétique et pour comprendre la parole humaine, et du module Code Interpreter pour faciliter la création de programmes informatiques avec ChatGPT.
J’ai exploré de suite ces innovations et rapporté sur mes expériences sur les réseaux sociaux: dialogue vocale avec ChatGPT-4, nombre de personnes sur une image, résumé de ma page web d’accueil, génération d’une image sur base d’un croquis, génération de cartoons.
Les innovations les plus attrayantes étaient l’introduction de ChatGPT-4 Turbo et du concept de Custom GPT.
GPT-4 Turbo est plus performant et connaît les événements mondiaux jusqu’en avril 2023. Il dispose d’une fenêtre contextuelle de 128 000 pages et peut donc contenir l’équivalent de plus de 300 pages de texte dans une session.
J’ai testé les nouvelles compétences et performances de ChatGPT-4 dans un dialogue impressionnant “My discussion with ChatGPT-4 about the evolution of the Internet“.
Ecosystème Custom GPT
Une Custom GPT permet de personnaliser le robot ChatGPT-4 pour des besoins spécifiques, en ajoutant des contenus personnels (textes et images), en écrivant des instructions à effectuer et en ajoutant, éventuellement, du code pour exécuter des actions informatiques, par exemple envoyer un message, faire des recherches dans une base de données, mettre à jour un site web.
Les premières applications luxembourgeoises du type Custom GPT ont été réalisées par les spécialistes suivants:
- Misch Strotz, CEO de l’agence de communication Neon Internet et créateur du générateur d’images LetzAI, a réalisé le modèle LetzGPT.
- Jean-Baptiste Niedercorn, radiologue aux hôpitaux Robert Schuman, a développé le modèle Radiology Report Assistant.
- Erwin Sotiro, avocat spécialisé dans le domaine des technologies et de l’intelligence artificielle, a créé plusieurs modèles: Labour Law Guide, Lux Company Law, Casp Guide, VASP Analyst, Lux Vat Advisor, etc.
Il y à quelques jours, OpenAI a ouvert son magasin Custom GPT, permettant à tout abonné de ChatGPT-4 de profiter des applications spécialisées, développées par d’autres usagers. À l’image de GooglePlay et du AppStore, qui offrent des applications pour les smartphones, OpenAI a lancé tout un écosystème, permettant la recherche de modèles gratuits et payants et de rémunérer les développeurs pour leur travail. Ce magasin ouvre une nouvelle dimension dans la popularisation de l’intelligence artificielle.
Rédaction et illustration de mon livre
Mi-novembre 2023, la technique était donc prête pour concrétiser mon rêve et pour procéder à la conception d’un livre d’aventures pour mes petits-enfants, avec l’aide de ChatGPT-4 et de LetzAI.
Concept initial de mon livre
Au début, j’avais esquissé un concept sophistiqué. Les 5 enfants, 2 filles et 3 garçons, parmi eux des jumeaux, étaient accompagnés par leurs animaux de compagnie : le lapin Floppy, le cochon d’Inde Caramel, le poisson rouge Blublu, le coq Cocorico et Léon, le caméléon. La galerie d’images qui suite montre les protagonistes imaginées.


Le voyage aurait du se dérouler comme une grande aventure, parsemée d’imprévus et de complications. Mais ChatGPT était accablé avec mon script, aussi bien au niveau de la génération d’illustrations qu’au niveau de la génération de textes cohérents.
Au niveau des illustrations, je n’ai pas réussi à générer des images correctes avec tous les personnages et les animaux de compagnie : des enfants avec des têtes de caméléon ou avec des jambes de coq, des incohérences avec les habits et les lunettes des enfants, des confusions au niveau de la couleur des cheveux et des yeux, sont quelques exemples des problèmes rencontrés. À côté de DALL*E3, j’ai essayé d’autres applications de génération d’images comme Stable Diffusion (stability.ai) et Midjourney. C’était encore pire. J’ai visité les grands sites web AI communautaires comme Stable Diffusion Art ou CivitAI pour me rendre compte qu’aucun modèle ajusté de génération d’images, développé par les usagers inscrits, permettait de générer des groupes de personnes.
J’ai commencé à entraîner mes propres modèles du type LoRA avec Stable Diffusion, respectivement des modèles LetzAI. Comme supports pour l’entraînement des modèles, j’ai utilisé quelques rares images DALL*E3 réussies, ainsi que des assemblages des différentes personnes à l’aide de Photoshop. Malgré tous les efforts, j’ai dû me rendre compte que la génération cohérente d’images de plus de trois personnes était illusionnaire.
Au niveau de la génération du texte, j’ai constaté que des scénarios complexes embrouillaient ChatGPT et ne permettaient plus de créer des récits cohérents dans une même session. J’avais par exemple imaginé qu’un des acteurs se cassait une jambe lors d’un saut en parachute en Indonésie et devait être rapatrié par Luxembourg Air Rescue. J’avais prévu d’autres complications et incidents, mais c’était trop fastidieux de demander en permanence à ChatGPT des modifications des récits générés, respectivement de procéder à des corrections manuelles.
Mon ambition était d’exposer l’état de l’art de l’intelligence artificielle au début de l’an 2024 par la publication de mon livre, sans procéder à des retouches aux niveaux des illustrations et des récits. J’avais toutefois l’intention de demander différentes créations des illustrations et des textes pour certaines scènes et de sélectionner ensuite les meilleurs résultats.
Concept définitif de mon livre
Pour tenir compte des limitations actuelles de l’intelligence artificielle, je me suis résigné à simplifier mon script initial. Les animaux de compagnie sont restés à la maison et les cinq enfants ont été répartis en deux équipes : la fille ainée formait un groupe avec les deux jumeaux et la fille cadette faisait un team avec son cousin. De cette façon c’était possible de dépicter, d’une façon cohérente, les deux bandes avec 2 et 3 personnes dans des images générées par AI.
Au niveau de la description du voyage, j’ai remplacé l’expédition, avec des imprévues et des complications à travers le monde, par une exploration bien organisée de plusieurs destinations, définies au préalable, dans différents pays. De cette manière ChatGPT-4 a pu mettre en valeur ses riches connaissances du monde, sans devoir trop réfléchir. Malgré ses compétences impressionnantes pour programmer des applications informatiques ou pour résoudre des problèmes logiques, le raisonnement n’est pas encore le trait le plus fort de ChatGPT-4. D’ailleurs les autres robots de dialogue n’ont pas encore atteint le même niveau d’intelligence que l’application d’OpenAI. Sam Altman, le CEO de l’entreprise, a annoncé récemment que la faculté de penser de ChatGPT-5, qui sera lancé en 2024, sera sensiblement améliorée et que la génération de vidéos, à partir de prompts, sera ajoutée au produit. J’espère donc pouvoir reprendre mon concept initial au début de 2025 pour donner une suite aux aventures des jeunes explorateurs dans un deuxième livre.
Au niveau des dimensions du livre, j’ai opté pour un format carré de 17 x 17 cm, en présentant les explorations des deux équipes, jour par jour, sur une double page.

Après la définition des dimensions de i’illustration sur chaque page et le choix de la police de caractères pour le texte, j’ai pu évaluer que le récit sur chaque page ne pouvait pas dépasser 200 mots.
Dialogue avec ChatGPT
Pour s’entretenir avec ChatGPT-4, il faut être abonné payant auprès d’OpenAI, au prix mensuel de 21,29 €, TVA incluse. Je suis un abonné de longue date. Malgré quelques privilèges, je suis de plus en plus souvent confronté au problème de la surcharge des serveurs d’OpenAI, accompagnée d’un temps d’attente pour accéder au service. Pour faire face à l’augmentation continue des usagers, OpenAI a introduit des restrictions pour l’utilisation du service. Après 30 requêtes, il faut attendre 3 heures pour continuer le dialogue. La session reste toutefois établie et ChatGPT garde en mémoire toute la discussion du passé. D’ailleurs, tout le dialogue au sujet de mon livre, pendant des dizaines de jours, s’est passé dans une même session.
Avant d’ouvrir la session de dialogue, j’avais préparé un avant-projet pour le déroulement de l’exploration. Comme je voulais créer quelque chose de consistant, je me suis proposé de dresser une liste de 100 sites du patrimoine mondial de l’UNESCO, à visiter par les enfants dans différents pays, à travers de trajets distincts à parcourir par chaque équipe, moyennant une panoplie de moyens de transport. J’avais également esquissé un itinéraire pour la traversée des différents pays. Comme introduction, j’ai soumis mes réflexions à ChatGPT. Après ses éloges et félicitations au sujet de mon initiative de création d’un livre pour enfants, on a abordé du concret: j’ai demandé à ChatGPT de me proposer une liste des sites UNESCO à visiter, un relevé des moyens de transport disponibles dans les différents pays et une chronologie des visites à faire. Et progressivement, on s’est mis d’accord sur les moments du voyage et sur la chronologie.
J’ai commencé avec la deuxième équipe, composée de deux enfants. Comme commande à soumettre à ChatGPT, c’était suffisant d’entrer un prompt du type : “jour x, visite du site Y, moyen de transport Z, nuitée à Q“. Et progressivement on est arrivé au 60e jour du voyage avec le retour à Luxembourg, après la visite de 50 sites UNESCO dans 25 pays différents, avec des parcours en avion de ligne, en avion privé, en bateau, en taxi, en voiture Uber, en co-voiturage, à pied, etc.
Pour la première équipe, constituée de trois enfants, c’était la même procédure. Mais au lieu de commencer leur exploration au Luxembourg comme l’autre groupe, les enfants sont partis le premier jour en Australie. Et comme les distances à parcourir entre les différents sites étaient plus longues, ils étaient obligés de prendre des moyens de transport plus innovants : un avion privé avec décollage et atterrissage verticale, un hovercraft. Et dans les pays plus exotiques, c’était un Tuk-Tuk.
Dans l’introduction j’avais informé ChatGPT que le texte pour chaque page devait être d’environ 200 mots, ce que le robot a scrupuleusement respecté. C’était rare que j’ai demandé à ChatGPT de reformuler le récit pour une journée, et le plus souvent c’était à cause de ma propre faute, à cause d’une erreur dans le prompt spécifié. Pour les lecteurs intéressés aux détails, je fournis ici le lien pour accéder à la discussion entière avec le chatbot dans la session archivée.
Custom GPT pour les illustrations
Après la validation du texte, c’était le moment de procéder à la création des illustrations pour le livre. Après mes expériences du passé et mes essais réalisés pour générer des images AI d’un groupe de personnes, je suis arrivé à la conclusion que l’entraînement de deux modèles LetzAI, moyennant la génération de quelques dizaines d’illustrations générées avec ChatGPT-4 / DALL*E3, suivie éventuellement de retouches avec l’outil Adobe Photoshop, était la procédure la plus prometteuse pour obtenir rapidement des résultats valables. J’ai eu raison. Je souligne que la génération directe des images voulues dans LetzAI n’était pas encore possible au début de l’année 2024, à cause de la longueur limitée des prompts à entrer sur la plateforme. Cette restriction a été levée récemment dans le cadre des autres évolutions de LetzAI.
La page qui suit affiche une capture d’écran de la page de configuration de ma Custom GPT “Two young explorers“.
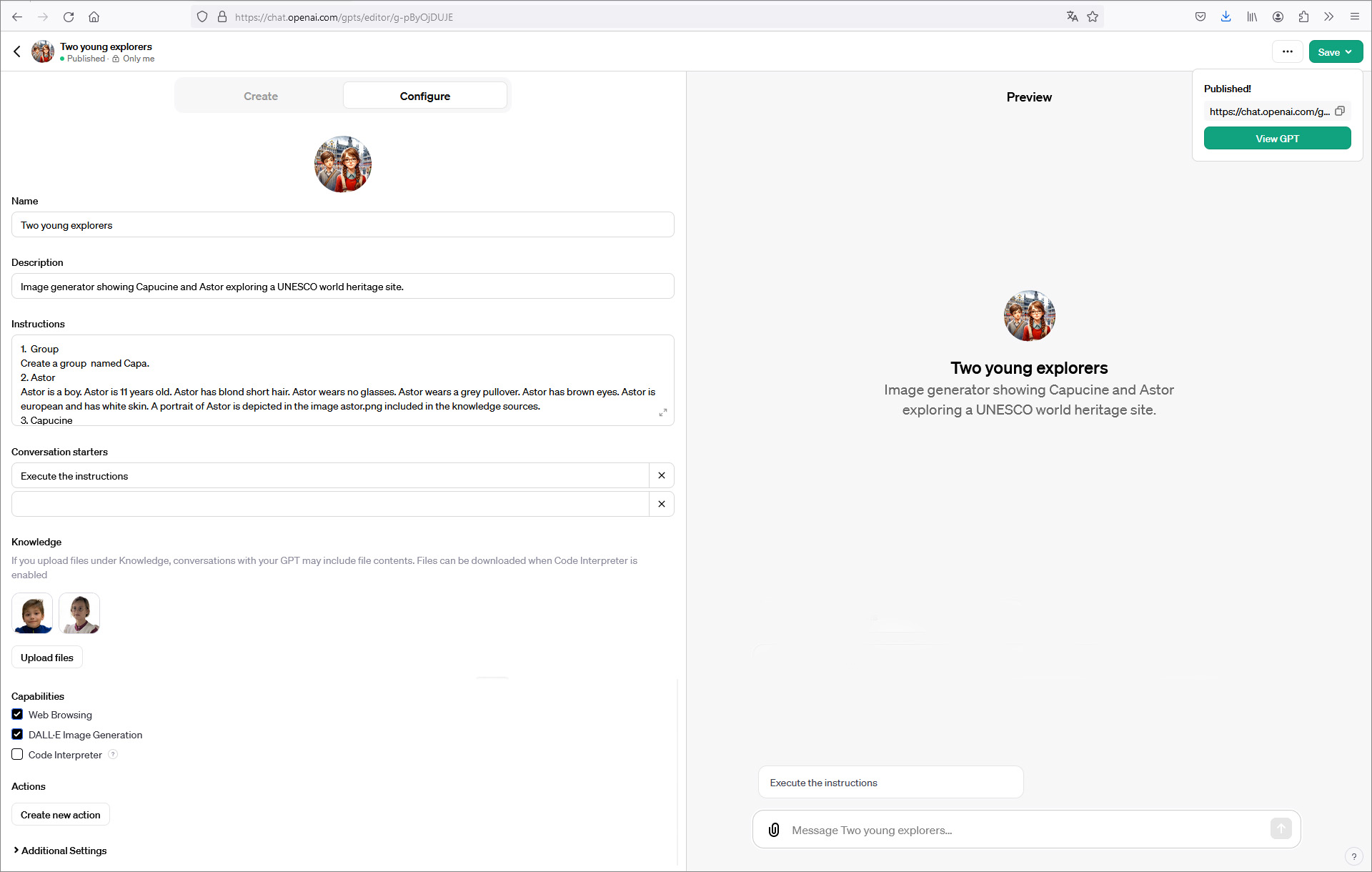
Dans les instructions j’ai défini un groupe, suivi par la spécification des deux membres de ce groupe, comme le genre, l’âge, les cheveux, les yeux, les accessoires (lunettes), les habits, etc. Ensuite j’ai indiqué les caractéristiques des images à générer : dimensions, style, angle de vue, etc. J’ai également fixé les règles à observer : pas d’écriture de textes dans l’image, respect de la cohérence, etc. J’ai ajouté comme référence deux photos avec des portraits de mes petits-enfants concernés. Comme dernière instruction, j’ai invité ChatGPT à demander à l’usager, à chaque requête, le lieu de la scène et les activités du groupe à afficher dans l’image. Ensuite il suffit de cliquer sur le bouton “Exécuter les instructions” et de répondre à la question de ChatGPT, par exemple “site UNESCO de la Grande Barrière en Australie, plongée dans les corails“.


Le modèle personnalisé Custom GPT “Three young explorers” pour l’autre groupe a été configuré de la même manière. Si l’image ne correspondait pas aux attentes, j’ai demandé une nouvelle génération au robot. La capture d’écran qui suit montre que cette tentative se terminait des fois avec un dialogue de sourd.
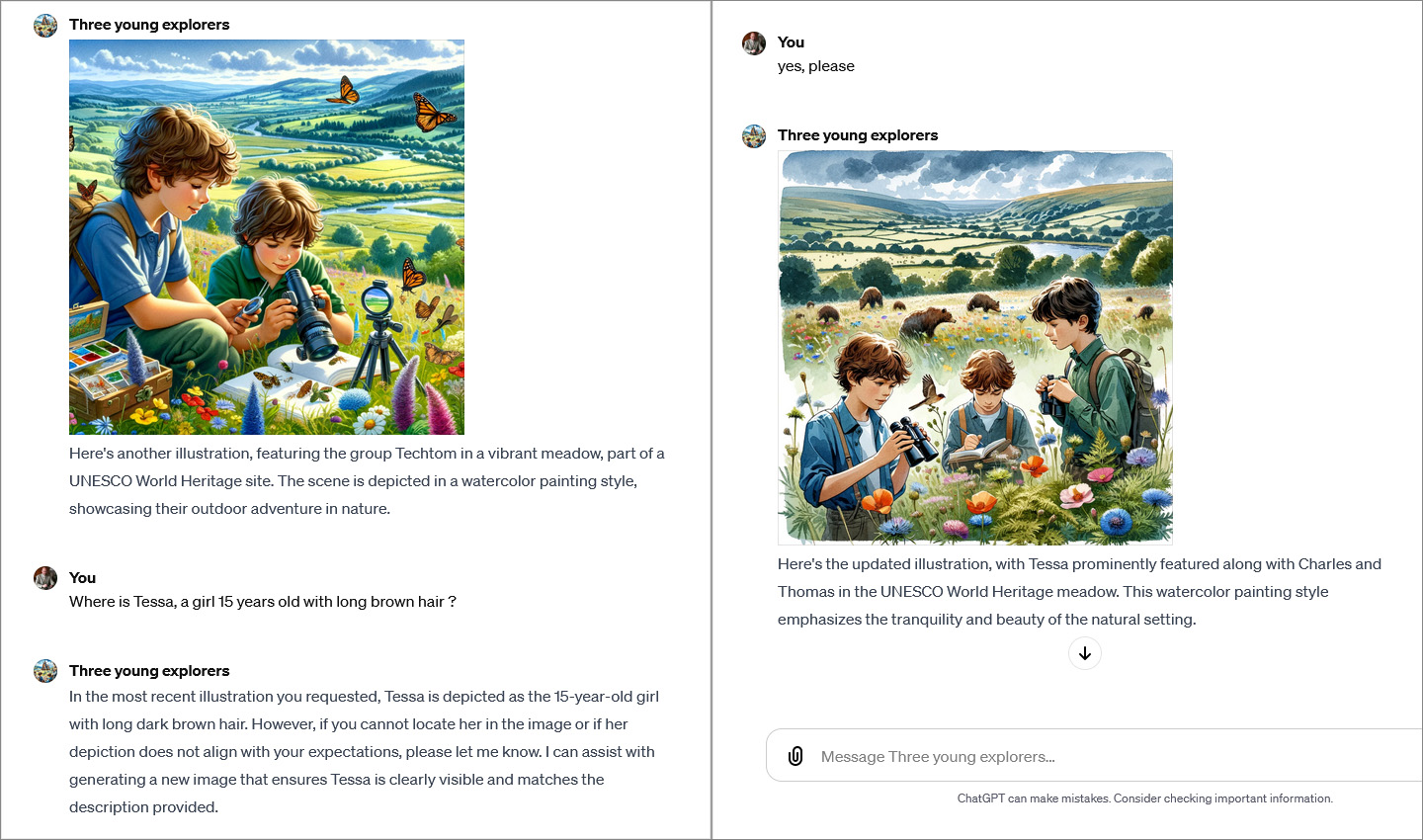
Il reste à signaler que ChatGPT s’est efforcé pendant tout le cycle de génération d’images de témoigner de ses connaissances du monde, lors de la création des illustrations. Comme les personnes en Afrique sont en général de couleur noire et comme celles en Asie ont les yeux bridées, la physionomie des jeunes explorateurs a été modifiée dans ce sens par ChatGPT, lors de leurs voyages dans ces continents. Quelques exemples sont affichés ci-après :



Après la réalisation de quelques retouches à la collection des illustrations générées pour les deux groupes, j’ai pu procéder à l’avant-dernière étape : l’entraînement des modèles LetzAI.
Création des modèles LetzAI
L’étape de création des modèles LetzAI était la plus facile. Après le login sur la plateforme LetzAI, on se décide pour la création d’un modèle public ou privé. On déclare qu’on dispose des droits sur les images utilisées pour la création du modèle, on choisit un nom, on télécharge les images et on clique sur entraînement. Ensuite on peut passer à autre chose. Après un quart d’heure on est informé que le modèle est prêt et qu’il faut l’activer.
Le 10 novembre 2023, j’examinai quelques nouvelles fonctionnalités de mon éditeur vidéo. Pour se baser sur un cas concret, j’ai profité de l’occasion pour réaliser un tutoriel LetzAI. La vidéo n’est pas parfaite et l’interface de la plateforme LetzAI a un peu changé entretemps, mais le tutoriel donne une vue fidèle comment procéder pour entraîner un modèle et pour générer des images.
Pour commenter la vidéo en anglais, j’ai utilisé une application AI de synthèse de la parole, avec clonage de ma propre voix et synchronisation labiale. La musique de fond a également été composée par une application d’intelligence artificielle, développée par l’entreprise luxembourgeoise AIVA.AI.
Mes deux modèles LetzAI créés pour le livre s’appellent @2_explorers et @3_explorers. Pour les activer, j’ai spécifié le type de modèle comme groupe de 2 ou 3 personnes, en décrivant les membres du groupe dans les sous-types. Pour générer ensuite une image, il suffit alors d’entrer un prompt dans le bon format, par exemple “@2_explorers, group, riding a bicycle in Amsterdam” ou “@3_explorers, group, hiking in Katmandou, Nepal“. Et voilà. Le jeu est joué.


L’ensemble des images générées peut être visualisé dans l’aperçu du livre.
Impression de mon livre
Pour l’impression de mon livre, j’ai opté pour l’auto-édition auprès du fournisseur en-ligne Books on Demand (BoD). Il y a d’autres entreprises qui proposent l’impression de livres en auto-édition, comme Amazon avec son service Kindle Direct Publishing (KDP), mais j’ai fait d’excellentes expériences avec BoD dans le passé, avec mes autres livres.
Pour préparer le fichier avec le texte à fournir à l’imprimerie, j’ai utilisé de logiciel Microsoft Office Word. Sur le site web de BoD on peut télécharger des canevas word (.dotx) pour configurer la mise en page optimale pour l’impression. J’ai copié les différents chapitres générés par ChatGPT-4 dans Word et inséré les illustrations LetzAI dans les pages correspondantes. À la fin, j’ai profité d’un utilitaire de Word pour créer de manière automatique une table des matières du livre et j’ai exporté le document complet en format PDF. Dans le passé j’avais composé, pour mes autres livres BoD, le fichier PDF de couverture à l’aide de Photoshop. Les dimensions à respecter et le code barre à insérer au verso ont été communiqués par BoD. Pour le présent livre, j’ai profité de EasyCover, l’outil gratuit de création automatique de couvertures en-ligne de BoD, qui contient de nombreux spécimen. Les deux fichiers sont téléchargés sur la plateforme BoD et vérifiés par le système. Le cas échéant, des erreurs sont signalées et il faut alors recharger le fichier corrigé.
Pour commander l’impression du livre, on choisit d’abord une formule de publication. La moins chère s’appelle “BoD Fun” et permet de faire imprimer un livre sur papier à partir de 2,05 €. Je conseille de commencer avec cette formule, car elle permet de tenir rapidement un livre imprimé dans les mains pour procéder à une validation finale, avant de commander plus d’exemplaires pour la famille, pour les amis ou pour la vente privée, respectivement pour passer à la deuxième formule, au nom de “BoD Classique“. Cette formule est la plus appréciée, car pour un contrat d’un an au prix unique de 39 €, elle inclut une distribution auprès d’Amazon, auprès des grandes librairies et dans le magasin en ligne de BoD. On peut déterminer soi-même le prix de vente, avec une certaine marge à accorder à l’éditeur BoD et au vendeur, en fonction du montant défini. Le contrat inclut la création d’une version eBook et l’attribution d’un numéro ISBN. D’autres formules plus chères offrent une assistance professionnelle pour la rédaction et l’édition du livre. Dans tous les cas on peut choisir différents formats (de 12x19cm jusqu’à A4), différents types de papier (blanc, crème, photo), différents pelliculages (mat, brillant, relief), différentes couvertures (souple, dure collée, dure cousue, anneaux) et deux modes d’impression (standard, premium). Une calculette en ligne sur le site web de BoD permet de calculer le prix d’impression, en fonction des critères sélectionnés, du nombre de pages, du nombre de pages en couleur et du nombre de livres commandés.
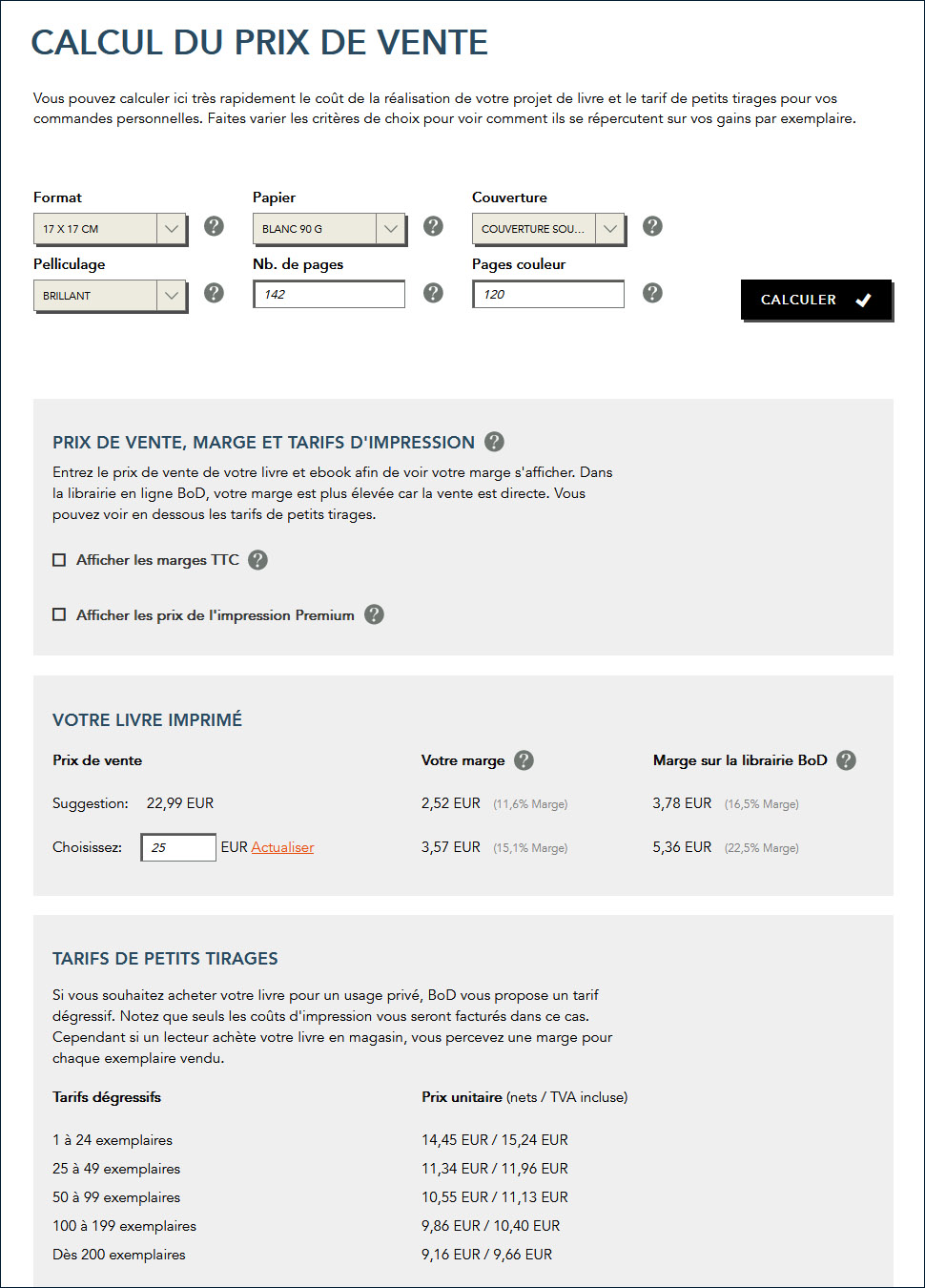
Pour la première impression j’ai commandé le livre, qui comprend 142 pages, au format 17×17, en trois variantes, du moins cher (10,87 €) jusqu’au plus cher (22,20 €), aux fins d’évaluer la qualité d’impression et de la reliure. Je viens d’être informé en ce moment par UPS que le premier exemplaire sera livré aujourd’hui. Je suis impatient de l’avoir dans mes mains.
Bibliographie
- 10 Things Sam Altman Says are Likely COMING in 2024 for ChatGPT!, Afaq Ali, 12.2023
- Best Way to Re-create Any Image!, Stella Sky, 12.2023
- Stable Diffusion enables the control of camera distance and angles, Edmond Yip, 5.2023
- Conscience synthétique, Marco Barnig, 2018








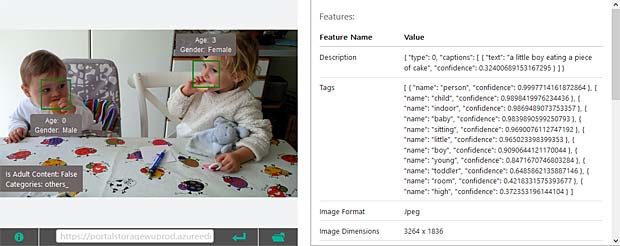
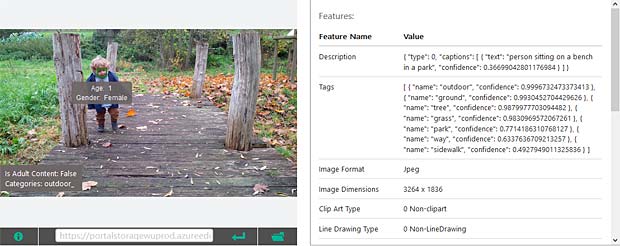


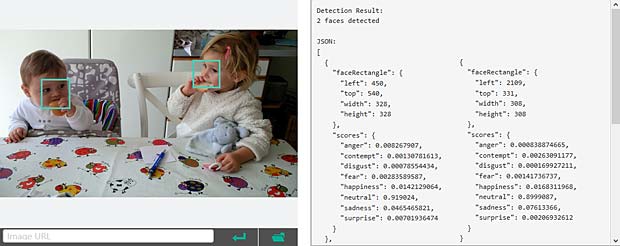
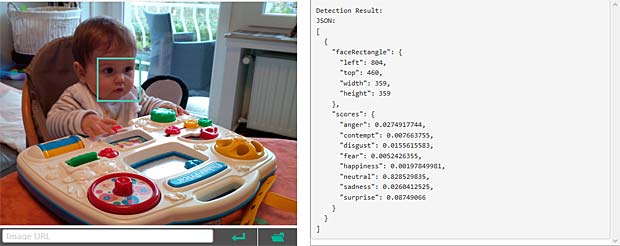
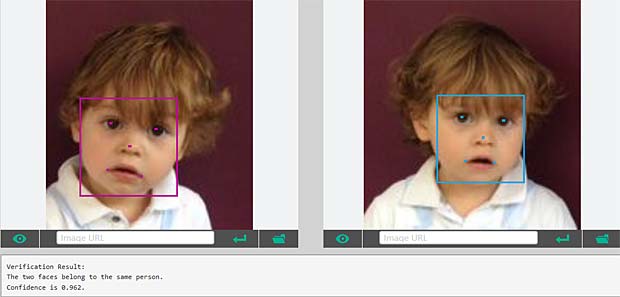
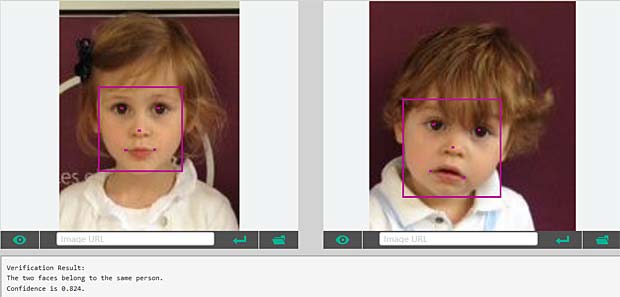
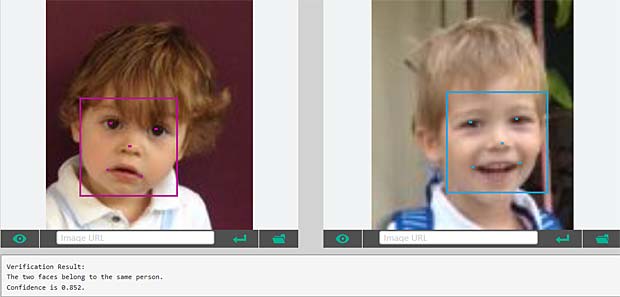
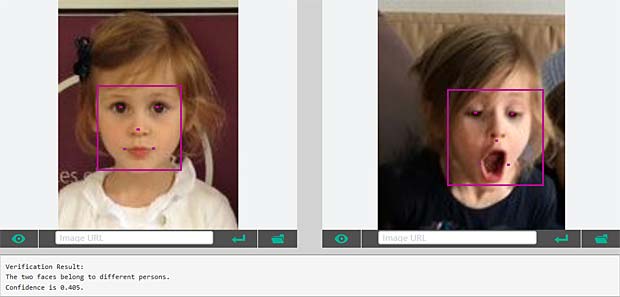
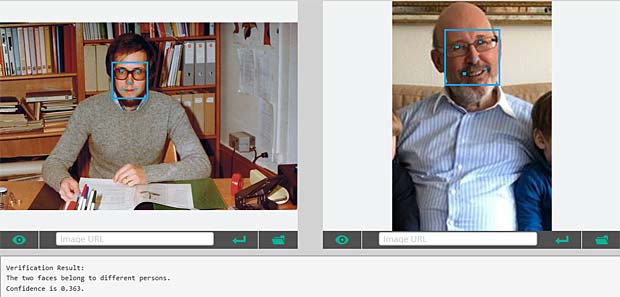
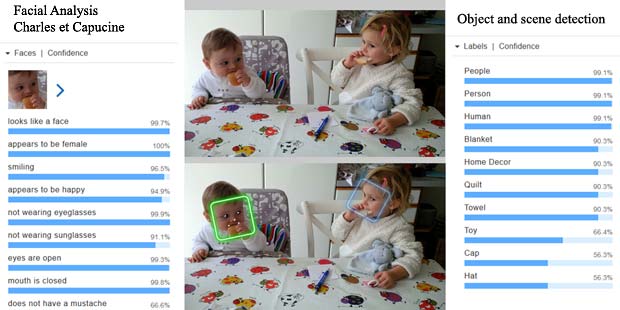
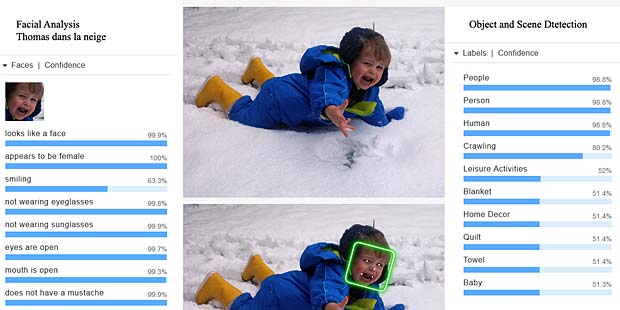
 Google Vision ne fournit pas un service de reconnaissance des personnes comme dans Google Photo, mais se limite à détecter les visages et à interpréter les émotions. Dans la figure ci-dessus les informations pour les deux visages sont indiquées en haut à droite (Charles) et en bas à gauche (Capucine). Les étiquettes (label) pour la scène sont affichées en bas au milieu, le texte reconnu se trouve en bas à droite.
Google Vision ne fournit pas un service de reconnaissance des personnes comme dans Google Photo, mais se limite à détecter les visages et à interpréter les émotions. Dans la figure ci-dessus les informations pour les deux visages sont indiquées en haut à droite (Charles) et en bas à gauche (Capucine). Les étiquettes (label) pour la scène sont affichées en bas au milieu, le texte reconnu se trouve en bas à droite.
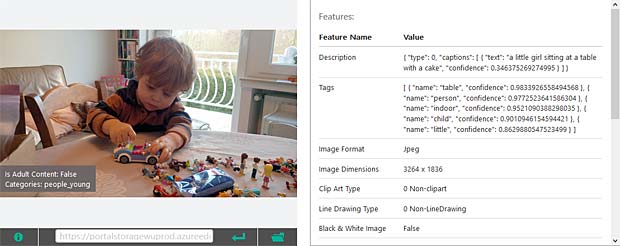
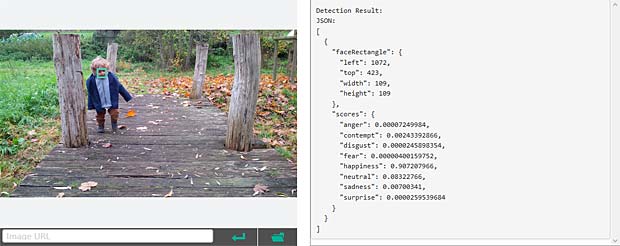
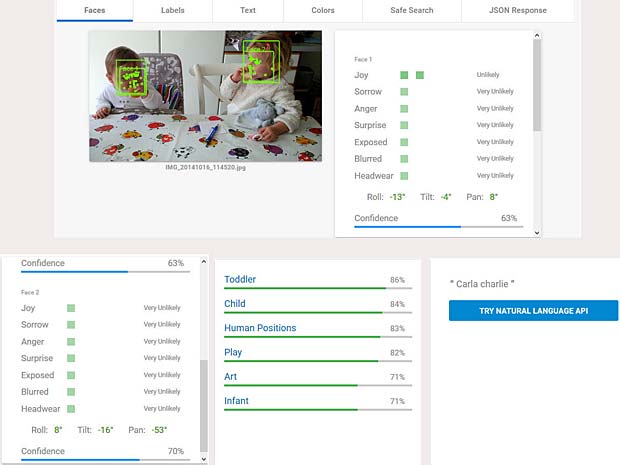
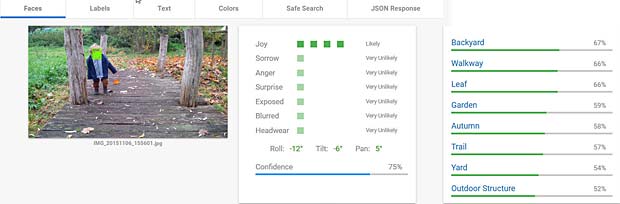 Google Vision voit de la joie dans le visage de Charles qui se trouve dehors, dans une sorte de jardin, avec des feuilles, en automne. Bonne interprétation.
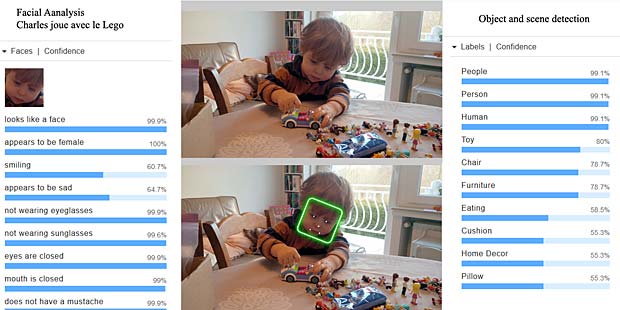
Google Vision voit de la joie dans le visage de Charles qui se trouve dehors, dans une sorte de jardin, avec des feuilles, en automne. Bonne interprétation.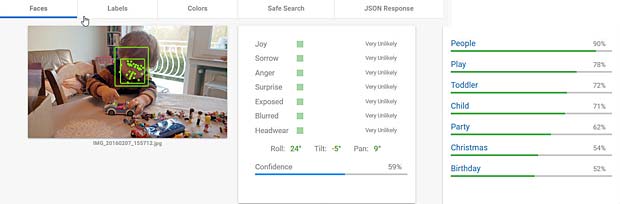 Google Vision estime que Charles fête son anniversaire à Noël. En réalité il joue en février 2016 avec du Lego. Echec.
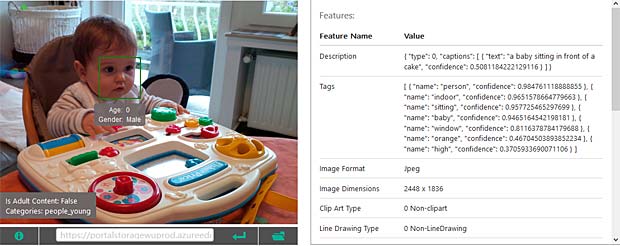
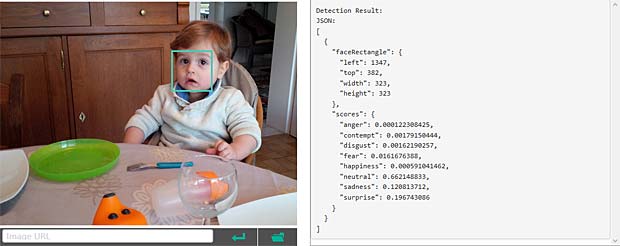
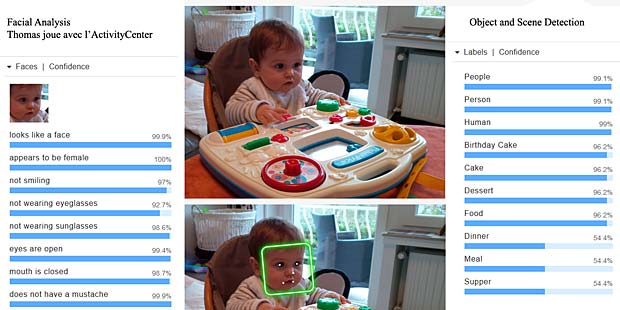
Google Vision estime que Charles fête son anniversaire à Noël. En réalité il joue en février 2016 avec du Lego. Echec.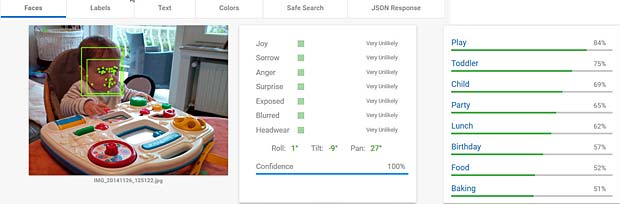 L’activity-Center Fisher-Prize de Thomas fait penser Google Vision à un anniversaire et à de la nourriture.
L’activity-Center Fisher-Prize de Thomas fait penser Google Vision à un anniversaire et à de la nourriture.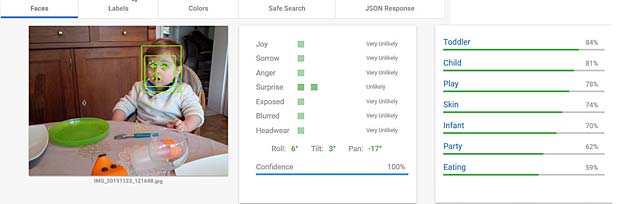







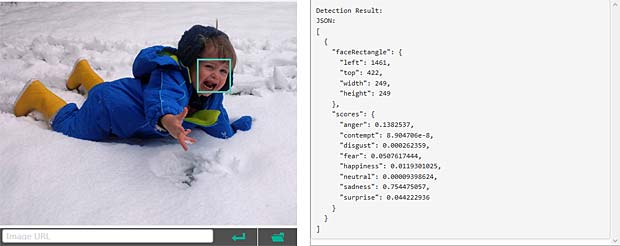
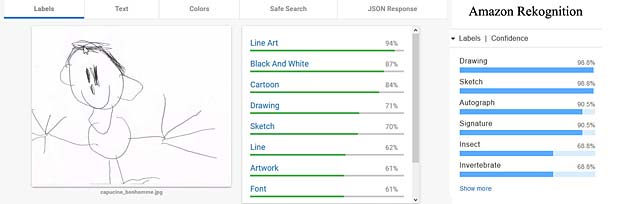 Le dessin du bonhomme est reconnu par Google Vision (résultats au milieu) comme cartoon et oeuvre d’art, tandis que Amazon Rekognition voit une signature ou un insecte. Aucun des deux systèmes reconnaît une figure humaine.
Le dessin du bonhomme est reconnu par Google Vision (résultats au milieu) comme cartoon et oeuvre d’art, tandis que Amazon Rekognition voit une signature ou un insecte. Aucun des deux systèmes reconnaît une figure humaine.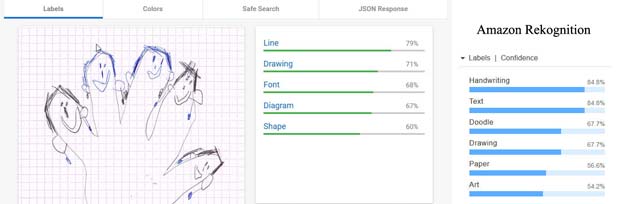 Les visages avec des boucles d’oreille qui ornent le contour de la main de Capucine ne sont pas identifiés comme tels par aucun des systèmes. Ce sont des lignes, des dessins, des formes ou diagrammes. Amazon Rekognition est au moins d’avis qu’il s’agit de l’art.
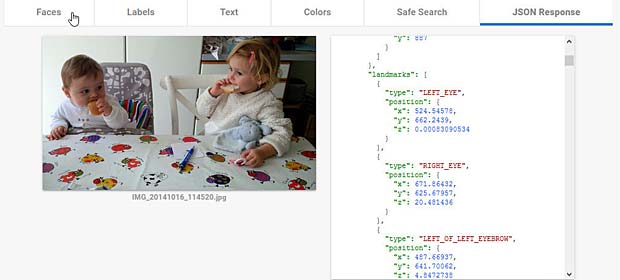
Les visages avec des boucles d’oreille qui ornent le contour de la main de Capucine ne sont pas identifiés comme tels par aucun des systèmes. Ce sont des lignes, des dessins, des formes ou diagrammes. Amazon Rekognition est au moins d’avis qu’il s’agit de l’art.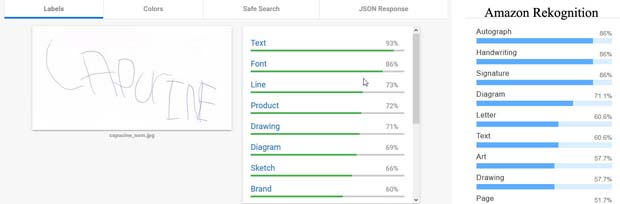 En ce qui concerne le nom de Capucine, Google Vision estime qu’il s’agit d’un texte, mais n’est pas en mesure de le lire. L’OCR (optical character recognition) ne fait pas encore partie du produit Amazon Rekognition. Ce système détecte toutefois qu’il s’agit de textes, de caractères, d’une signature ou d’un autographe.
En ce qui concerne le nom de Capucine, Google Vision estime qu’il s’agit d’un texte, mais n’est pas en mesure de le lire. L’OCR (optical character recognition) ne fait pas encore partie du produit Amazon Rekognition. Ce système détecte toutefois qu’il s’agit de textes, de caractères, d’une signature ou d’un autographe.