Referring to my recent post about Face Recognition Systems, I did some trials with my “About” photo. Here are the results of my Face Recognition Tests :
Animetrics

Face Detection Tests : Animetrics
{"images": [
{"time": 4.328,
"status": "Complete",
"url": "http://www.web3.lu/download/Marco_Barnig_529x529.jpg",
"width": 529,
"height": 529,
"setpose_image": "http://api.animetrics.com/img/setpose/d89864cc3aaab341d4211113a8310f9a.jpg",
"faces": [
{"topLeftX": 206,
"topLeftY": 112,
"width": 82,
"height": 82,
"leftEyeCenterX": 227.525,
"leftEyeCenterY": 126.692,
"rightEyeCenterX": 272.967,
"rightEyeCenterY": 128.742,
"noseTipX": 252.159,
"noseTipY": 158.973,
"noseBtwEyesX": 251.711,
"noseBtwEyesY": 126.492,
"chinTipX": -1,
"chinTipY": -1,
"leftEyeCornerLeftX": 219.005,
"leftEyeCornerLeftY": 126.308,
"leftEyeCornerRightX": 237.433,
"leftEyeCornerRightY": 127.85,
"rightEyeCornerLeftX": 262.995,
"rightEyeCornerLeftY": 129.004,
"rightEyeCornerRightX": 280.777,
"rightEyeCornerRightY": 129.094,
"rightEarTragusX": -1,
"rightEarTragusY": -1,
"leftEarTragusX": -1,
"leftEarTragusY": -1,
"leftEyeBrowLeftX": 211.478,
"leftEyeBrowLeftY": 120.93,
"leftEyeBrowMiddleX": 226.005,
"leftEyeBrowMiddleY": 117.767,
"leftEyeBrowRightX": 241.796,
"leftEyeBrowRightY": 120.416,
"rightEyeBrowLeftX": 264.142,
"rightEyeBrowLeftY": 121.101,
"rightEyeBrowMiddleX": 278.625,
"rightEyeBrowMiddleY": 119.38,
"rightEyeBrowRightX": 290.026,
"rightEyeBrowRightY": 124.059,
"nostrilLeftHoleBottomX": 243.92,
"nostrilLeftHoleBottomY": 168.822,
"nostrilRightHoleBottomX": 257.572,
"nostrilRightHoleBottomY": 170.683,
"nostrilLeftSideX": 236.867,
"nostrilLeftSideY": 163.555,
"nostrilRightSideX": 262.073,
"nostrilRightSideY": 165.049,
"lipCornerLeftX": -1,
"lipCornerLeftY": -1,
"lipLineMiddleX": -1,
"lipLineMiddleY": -1,
"lipCornerRightX": -1,
"lipCornerRightY": -1,
"pitch": -6.52624,
"yaw": -6.43,
"roll": 2.35988
}]}]}
APICloudMe

Face Recognition Tests : APICloudMe FaceRect and FaceMark
{"faces" : [
{"orientation" : "frontal",
"landmarks" : [
{"x" : 193,"y" : 125},
{"x" : 191,"y" : 145},
{"x" : 192,"y" : 163},
{"x" : 196,"y" : 178},
{"x" : 206,"y" : 194},
{"x" : 218,"y" : 204},
{"x" : 229,"y" : 206},
{"x" : 243,"y" : 209},
{"x" : 259,"y" : 206},
{"x" : 268,"y" : 202},
{"x" : 278,"y" : 195},
{"x" : 287,"y" : 182},
{"x" : 292,"y" : 167},
{"x" : 296,"y" : 150},
{"x" : 297,"y" : 129},
{"x" : 284,"y" : 112},
{"x" : 279,"y" : 108},
{"x" : 268,"y" : 110},
{"x" : 263,"y" : 116},
{"x" : 270,"y" : 113},
{"x" : 277,"y" : 111},
{"x" : 214,"y" : 111},
{"x" : 223,"y" : 107},
{"x" : 234,"y" : 110},
{"x" : 238,"y" : 115},
{"x" : 232,"y" : 113},
{"x" : 223,"y" : 110},
{"x" : 217,"y" : 127},
{"x" : 228,"y" : 121},
{"x" : 236,"y" : 129},
{"x" : 227,"y" : 131},
{"x" : 227,"y" : 126},
{"x" : 280,"y" : 129},
{"x" : 271,"y" : 123},
{"x" : 262,"y" : 130},
{"x" : 271,"y" : 133},
{"x" : 271,"y" : 127},
{"x" : 242,"y" : 128},
{"x" : 238,"y" : 145},
{"x" : 232,"y" : 157},
{"x" : 232,"y" : 163},
{"x" : 247,"y" : 168},
{"x" : 262,"y" : 164},
{"x" : 262,"y" : 158},
{"x" : 258,"y" : 146},
{"x" : 256,"y" : 129},
{"x" : 239,"y" : 163},
{"x" : 256,"y" : 164},
{"x" : 221,"y" : 179},
{"x" : 232,"y" : 178},
{"x" : 240,"y" : 179},
{"x" : 245,"y" : 180},
{"x" : 251,"y" : 180},
{"x" : 259,"y" : 180},
{"x" : 269,"y" : 182},
{"x" : 261,"y" : 186},
{"x" : 253,"y" : 189},
{"x" : 245,"y" : 189},
{"x" : 236,"y" : 187},
{"x" : 229,"y" : 184},
{"x" : 235,"y" : 182},
{"x" : 245,"y" : 184},
{"x" : 255,"y" : 184},
{"x" : 254,"y" : 183},
{"x" : 245,"y" : 183},
{"x" : 235,"y" : 182},
{"x" : 245,"y" : 183},
{"x" : 249,"y" : 160}
]}],
"image" : {
"width" : 529,
"height" : 529
}}
Betaface API
Image ID : 65fe585d-e565-496e-ab43-bcfdc18c7918
Faces : 2

Face Recognition Tests : Betaface API
hair color type: red (24%), gender: male (52%), age: 49 (14%), ethnicity: white (57%), smile: yes (15%), glasses: yes (48%), mustache: yes (46%), beard: yes (35%)
500: HEAD Height/Width level parameter (POS = long narrow face NEG = short wide face)(min -2 max 2): 1
501: HEAD TopWidth/BottomWidth level parameter (POS = heart shape NEG = rectangular face)(min -2 max 2):0
502: NOSE Height/Width level parameter (NEG = thinner) (min -2 max 2) : 2
503: NOSE TopWidth/BottomWidth level parameter (NEG = wider at the bottom) (min -2 max 2) : 1
504: MOUTH Width level parameter (min -2 max 2) : 1
505: MOUTH Height level parameter (NEG = thin) (min -2 max 2) : 1
521: MOUTH Corners vertical offset level parameter (NEG = higher) (min -2 max 2) : -2
506: EYES Height/Width level parameter (NEG = thinner and wider, POS = more round) (min -2 max 2) : -1
507: EYES Angle level parameter (NEG = inner eye corners moved towards mouth) (min -2 max 2) : 1
517: EYES closeness level parameter (NEG = closer) (min -2 max 2) : 0
518: EYES vertical position level parameter (NEG = higher) (min -2 max 2) : 0
508: HAIRSTYLE Sides thickness level parameter (min 0 max 3) : 0
509: HAIRSTYLE Hair length level parameter (min 0 max 5) : 0
510: HAIRSTYLE Forehead hair presence parameter (min 0 max 1) : 1
511: HAIRSTYLE Hair Top hair amount level parameter (min 0 max 4) : 3
512: FACE HAIR Mustache level parameter (min 0 max 2) : 0
513: FACE HAIR Beard level parameter (min 0 max 2) : 0
514: GLASSES presence level parameter (min 0 max 1) : 0
515: EYEBROWS thickness level parameter (min -2 max 2) : -2
516: EYEBROWS vertical pos level parameter (POS = closer to the eyes) (min -2 max 2) : -2
520: EYEBROWS Angle level parameter(NEG = inner eyebrows corners moved towards mouth)(min -2 max 2) :-2
519: TEETH presence level parameter (min 0 max 1) : 1
522: NOSE-CHIN distance level parameter (min -2 max 2) : 0
620756992: face height/face width ratio / avg height/width ratio : 1.0478431040781575
620822528: face chin width/face width ratio / avg height/width ratio : 1.0038425243863847
620888064: face current eyes distance/ avg eyes distance ratio : 1.0104771666577224
620953600: eyes vertical position - avg position, minus - higher : -0.00089347261759175321
621019136: distance between chin bottom and low lip / avg distance : 0.97106500562603393
621084672: distance between nose bottom and top lip / avg distance : 1.0075242288018134
621150208: distance between nose top and bottom / avg distance : 1.0619860919447868
621215744: distance between nose left and right / avg distance : 1.0426301239394231
621281280: distance between left mouth corner and right mouth corner / avg distance : 1.0806991515139102
621346816: eyebrows thichkness / avg thichkness : 0.83331489266473235
621412352: ratio (low nose part width / top nose part width) / avg ratio : 0.9717897529241869
621477888: eye height/width ratio / avg height/width ratio : 0.9611420163590253
621543424: width of the chin / avg width of the chin : 0.96738062415147075
621608960: angle of the eyes in degrees - avg angle. Negative angle mean inner eye corners moved towards mouth from average position : -0.35247882153940435
621674496: distance between eyebrows and eyes / avg distance : 0.88418599076781756
621740032: face width / avg width ratio : 0.96367766920692888
621805568: skin color (Weight) (min 0 max 1) : 1.340999960899353
621871104: skin color (H) (min 0 max 180) : 7
621936640: skin color (S) (min 0 max 255) : 81
622002176: skin color (V) (min 0 max 255) : 208
622067712: skin color (R) (min 0 max 255) : 208
622133248: skin color (G) (min 0 max 255) : 157
622198784: skin color (B) (min 0 max 255) : 142
622264320: mustache color if detected (Weight) (min 0 max 1) : 0
622329856: mustache color if detected (H) (min 0 max 180) : 0
622395392: mustache color if detected (S) (min 0 max 255) : 0
622460928: mustache color if detected (V) (min 0 max 255) : 0
622526464: mustache color if detected (R) (min 0 max 255) : 0
622592000: mustache color if detected (G) (min 0 max 255) : 0
622657536: mustache color if detected (B) (min 0 max 255) : 0
622723072: beard color if detected (Weight) (min 0 max 1) : 0
622788608: beard color if detected (H) (min 0 max 180) : 0
622854144: beard color if detected (S) (min 0 max 255) : 0
622919680: beard color if detected (V) (min 0 max 255) : 0
622985216: beard color if detected (R) (min 0 max 255) : 0
623050752: beard color if detected (G) (min 0 max 255) : 0
623116288: beard color if detected (B) (min 0 max 255) : 0
623181824: weight of teeth color (Weight) (min 0 max 1) : 0.4440000057220459
623247360: glasses detection (weight floating value, related to thickness of rim/confidence) (min 0.03 max 1) : 0.065934065934065936
623312896: color of the hair area (Weight) (min 0 max 1) : 0.23899999260902405
623378432: color of the hair area (H) (min 0 max 180) : 4
623443968: color of the hair area (S) (min 0 max 255) : 151
623509504: color of the hair area (V) (min 0 max 255) : 130
623575040: color of the hair area (R) (min 0 max 255) : 130
623640576: color of the hair area (G) (min 0 max 255) : 63
623706112: color of the hair area (B) (min 0 max 255) : 53
673513472: eyebrows angle. Negative angle mean inner eyebrow corners moved towards mouth from average position : 0.086002873281683989
673579008: mouth corners Y offset - avg offset : -0.12499242147802289
673644544: mouth height / avg height : 1.1755344432588537
673710080: nose tip to chin distance / avg distance : 1.0093704038280917
BioID
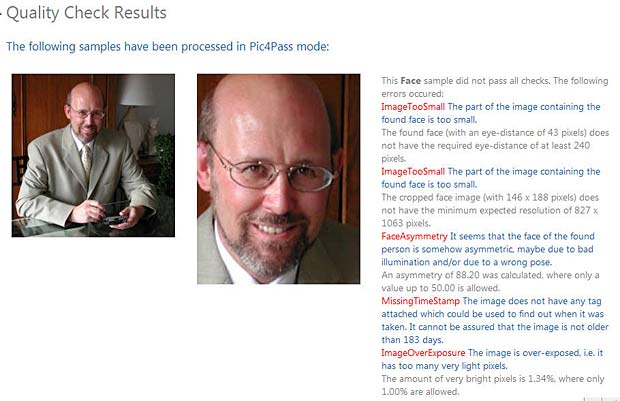
Face Recognition Tests : BioID
<?xml version="1.0" encoding="utf-16"?>
<OperationResults xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.bioid.com/2012/02/BWSMessages">
<JobID>955410d9-eb2c-43db-b3ca-deeedcd665af</JobID>
<Command>QualityCheck</Command>
<Succeeded>true</Succeeded>
<Samples>
<Sample Trait="Face" Suitable="true">
<Errors>
<Error>
<Code>ImageTooSmall</Code>
<Message>The part of the image containing the found face is too small.</Message>
<Details>The found face (with an eye-distance of 43 pixels) does not have the required eye-distance of at least 240 pixels.</Details>
</Error>
<Error>
<Code>ImageTooSmall</Code>
<Message>The part of the image containing the found face is too small.</Message>
<Details>The cropped face image (with 146 x 188 pixels) does not have the minimum expected resolution of 827 x 1063 pixels.</Details>
</Error>
<Error>
<Code>FaceAsymmetry</Code>
<Message>It seems that the face of the found person is somehow asymmetric, maybe due to bad illumination and/or due to a wrong pose.</Message>
<Details>An asymmetry of 88.20 was calculated, where only a value up to 50.00 is allowed.</Details>
</Error>
<Error>
<Code>MissingTimeStamp</Code>
<Message>The image does not have any tag attached which could be used to find out when it was taken. It cannot be assured that the image is not older than 183 days.</Message>
<Details />
</Error>
<Error>
<Code>ImageOverExposure</Code>
<Message>The image is over-exposed, i.e. it has too many very light pixels.</Message>
<Details>The amount of very bright pixels is 1.34%, where only 1.00% are allowed.</Details>
</Error>
</Errors>
<Tags>
<RightEye X="52.174" Y="84.108" />
<LeftEye X="95.448" Y="86.173" />
</Tags>
</Sample>
</Samples>
<Statistics>
<ProcessingTime>00:00:01.3642947</ProcessingTime>
<TotalServiceTime>00:00:01.6941376</TotalServiceTime>
</Statistics>
</OperationResults>
BiometryCloud
No demo app available.
HP Labs Multimedia Analytical Platform

Face Recognition Tests : HP Labs Multimedia Analytical Platform
{
"pic":{
"id_pic":"8f2cb88987e9e6b88813c5c17599204a25a8d63b",
"height":"529",
"width":"529"
},
"face":[{
"id_face":"2500002",
"id_pic":"8f2cb88987e9e6b88813c5c17599204a25a8d63b",
"bb_left":"209",
"bb_top":"109",
"bb_right":"290",
"bb_bottom":"190"
}]}
Lambda Labs Face

Face Recognition Tests : Lambda Labs
{
"status": "success",
"images": ["http://www.web3.lu/download/Marco_Barnig_529x529.jpg"],
"photos": [{"url": "http://www.web3.lu/download/Marco_Barnig_529x529.jpg",
"width": 529,
"tags": [
{"eye_left": {"y": 128,"x": 269},
"confidence": 0.978945010372561,
"center": {"y": 143,"x": 250},
"mouth_right": {"y": 180,"x": 267},
"mouth_left": {"y": 180,"x": 220},
"height": 128,"width": 128,
"mouth_center": {"y": 180,"x": 243.5},
"nose": {"y": 166,"x": 250},
"eye_right": {"y": 129,"x": 231},
"tid": "31337",
"attributes": [{"smile_rating": 0.5,"smiling": false,"confidence": 0.5},
{"gender": "male","confidence": 0.6564017215167235}],
"uids": [
{"confidence": 0.71,"prediction": "TigerWoods","uid": "TigerWoods@CELEBS"},
{"confidence": 0.258,"prediction": "ArnoldS","uid": "ArnoldS@CELEBS"}]}],
"height": 529
}]}
Orbeus ReKognition
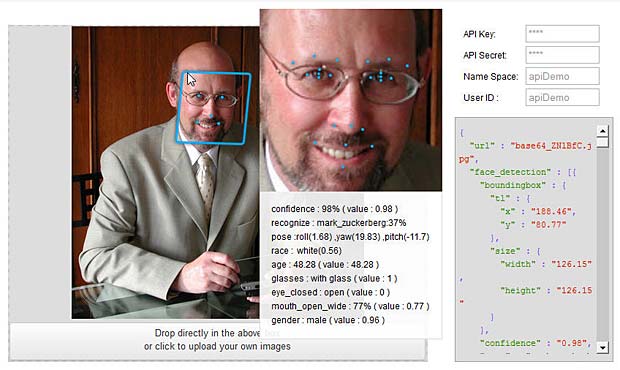
Face Recognition Tests : Orbeus ReKognition
{
"url" : "base64_ZNlBfC.jpg",
"face_detection" : [{
"boundingbox" : {
"tl" : {"x" : "188.46","y" : "80.77"},
"size" : {"width" : "126.15","height" : "126.15"}},
"confidence" : "0.98",
"name" : "mark_zuckerberg:0.37,obama:0.33,brad_pitt:0.16,",
"matches" : [{"tag" : "mark_zuckerberg","score" : "0.37"},
{"tag" : "obama","score" : "0.33"},
{"tag" : "brad_pitt","score" : "0.16"}],
"eye_left" : {"x" : "229.6","y" : "125.6"},
"eye_right" : {"x" : "272.5","y" : "127.7"},
"nose" : {"x" : "252.4","y" : "161.5"},
"mouth l" : {"x" : "226.9","y" : "173"},
"mouth_l" : {"x" : "226.9","y" : "173"},
"mouth r" : {"x" : "266.1","y" : "175.6"},
"mouth_r" : {"x" : "266.1","y" : "175.6"},
"pose" : {"roll" : "1.68","yaw" : "19.83","pitch" : "-11.7"},
"b_ll" : {"x" : "211.6","y" : "118"},
"b_lm" : {"x" : "226.7","y" : "113.2"},
"b_lr" : {"x" : "242.2","y" : "116.1"},
"b_rl" : {"x" : "263.5","y" : "117.1",
"b_rm" : {"x" : "277.8","y" : "115.5"},
"b_rr" : {"x" : "290.5","y" : "120"},
"e_ll" : {"x" : "221.5","y" : "125.7"},
"e_lr" : {"x" : "237.4","y" : "126.7"},
"e_lu" : {"x" : "229.9","y" : "122.5"},
"e_ld" : {"x" : "229.4","y" : "128.1"},
"e_rl" : {"x" : "265.3","y" : "128.2"},
"e_rr" : {"x" : "279.5","y" : "128.4"},
"e_ru" : {"x" : "272.5","y" : "124.8"},
"e_rd" : {"x" : "272.5","y" : "130.1"},
"n_l" : {"x" : "240.3","y" : "161.2"},
"n_r" : {"x" : "259.7","y" : "163.8"},
"m_u" : {"x" : "248.2","y" : "174.2"},
"m_d" : {"x" : "246.3","y" : "189.3"},
"race" : {"white" : "0.56"},
"age" : "48.28",
"glasses" : "1",
"eye_closed" : "0",
"mouth_open_wide" : "0.77",
"sex" : "0.96"},
{"boundingbox" : {
"tl" : {"x" : "19.23","y" : "221.54"},
"size" : {"width" : "160","height" : "160"}},
"confidence" : "0.07",
"name" : "obama:0.03,brad_pitt:0.02,jim_parsons:0.01,",
"matches" : [
{"tag" : "obama","score" : "0.03"},
{"tag" : "brad_pitt","score" : "0.02"},
{"tag" : "jim_parsons","score" : "0.01"}
],
"eye_left" : {"x" : "93.7","y" : "257.9"},
"eye_right" : {"x" : "128.4","y" : "309.1"},
"nose" : {"x" : "95.8","y" : "299.5"},
"mouth l" : {"x" : "58.9","y" : "306.9"},
"mouth_l" : {"x" : "58.9","y" : "306.9"},
"mouth r" : {"x" : "94.1","y" : "350.9"},
"mouth_r" : {"x" : "94.1","y" : "350.9"},
"pose" : {"roll" : "59.26","yaw" : "-11.22","pitch" : "9.96"},
"b_ll" : {"x" : "102.4","y" : "227.3"},
"b_lm" : {"x" : "114.9","y" : "240.8"},
"b_lr" : {"x" : "119.5","y" : "259.5"},
"b_rl" : {"x" : "133.9","y" : "282.1"},
"b_rm" : {"x" : "147.7","y" : "295.7"},
"b_rr" : {"x" : "153.8","y" : "312.3"},
"e_ll" : {"x" : "88.2","y" : "248.3"},
"e_lr" : {"x" : "100.2","y" : "267.6"},
"e_lu" : {"x" : "94.2","y" : "257.4"},
"e_ld" : {"x" : "92.7","y" : "258.4"},
"e_rl" : {"x" : "122.3","y" : "299.1"},
"e_rr" : {"x" : "134.7","y" : "319.7"},
"e_ru" : {"x" : "129.5","y" : "308.5"},
"e_rd" : {"x" : "127.2","y" : "309.6"},
"n_l" : {"x" : "78.7","y" : "298.6"},
"n_r" : {"x" : "97.8","y" : "318.4"},
"m_u" : {"x" : "80.4","y" : "321.2"},
"m_d" : {"x" : "72.6","y" : "328.5"},
"race" : {"black" : "0.63"},
"age" : "23.07",
"glasses" : "0.98",
"eye_closed" : "0.9",
"mouth_open_wide" : "0.46",
"sex" : "0.66"
}],
"ori_img_size" : {
"width" : "529",
"height" : "529"
},
"usage" : {
"quota" : "-10261829",
"status" : "Succeed.",
"api_id" : "4321"
}
}
Sky Biometry

Face Recognition Tests : SkyBiometry
face: (85%)
gender: male (86%)
smiling: true (100%)
glasses: true (57%)
dark glasses: false (21%)
eyes: open (80%)
mood: angry (69%)
N: 0%
A: 69%
D: 40%
F: 0%
H: 23%
S: 0%
SP: 21%
roll: 3
yaw: -14




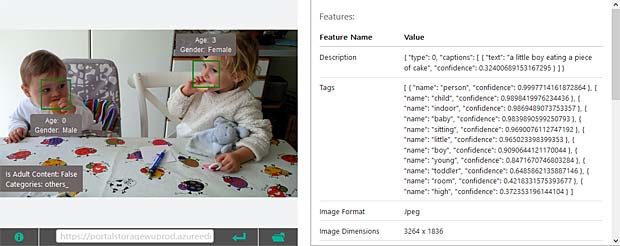
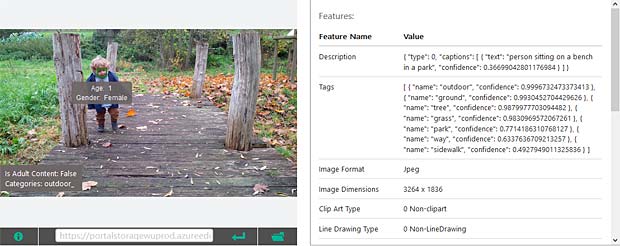


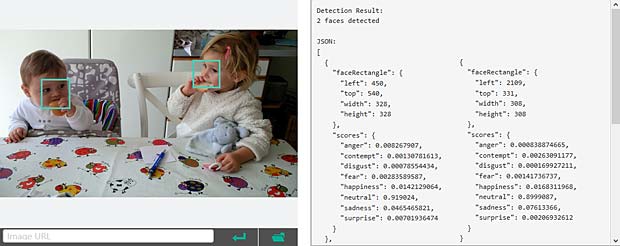
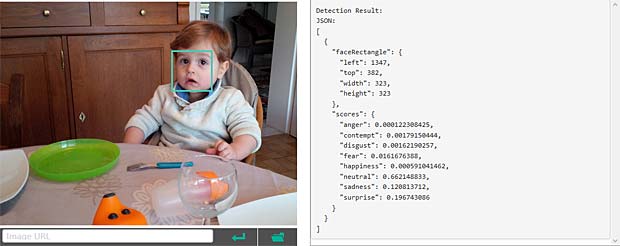
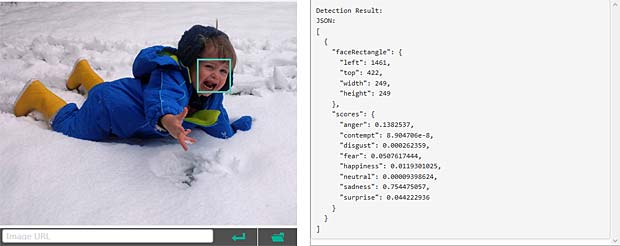
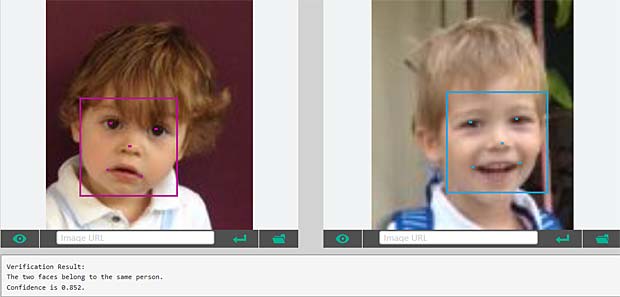
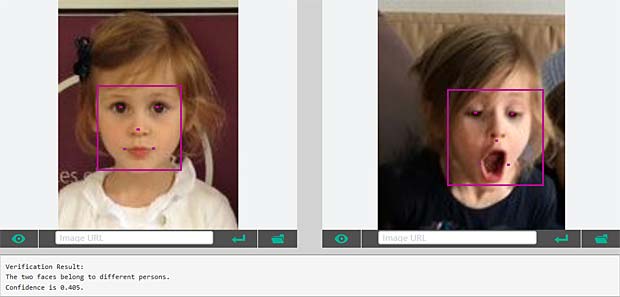
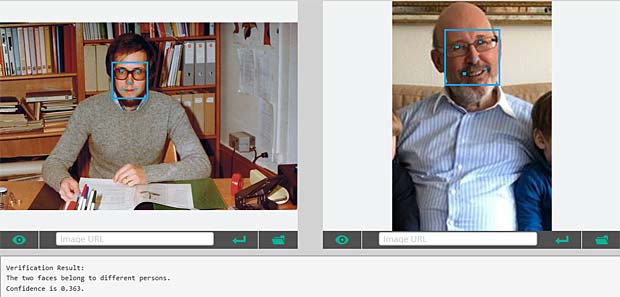
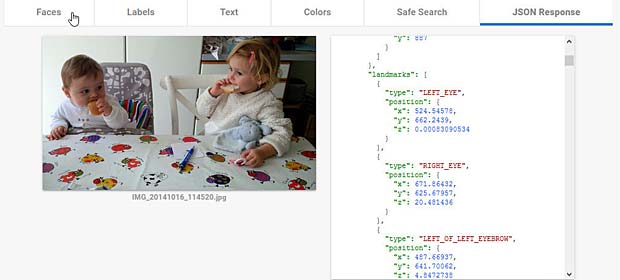
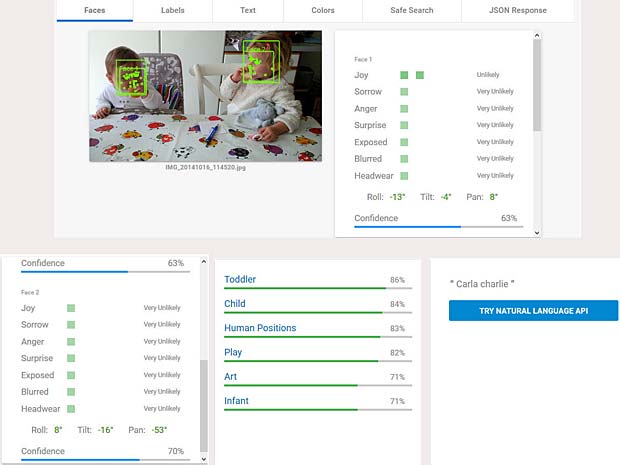 Google Vision ne fournit pas un service de reconnaissance des personnes comme dans Google Photo, mais se limite à détecter les visages et à interpréter les émotions. Dans la figure ci-dessus les informations pour les deux visages sont indiquées en haut à droite (Charles) et en bas à gauche (Capucine). Les étiquettes (label) pour la scène sont affichées en bas au milieu, le texte reconnu se trouve en bas à droite.
Google Vision ne fournit pas un service de reconnaissance des personnes comme dans Google Photo, mais se limite à détecter les visages et à interpréter les émotions. Dans la figure ci-dessus les informations pour les deux visages sont indiquées en haut à droite (Charles) et en bas à gauche (Capucine). Les étiquettes (label) pour la scène sont affichées en bas au milieu, le texte reconnu se trouve en bas à droite.
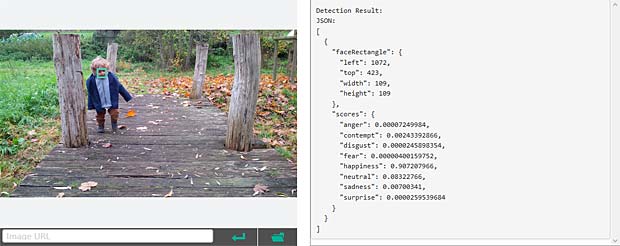
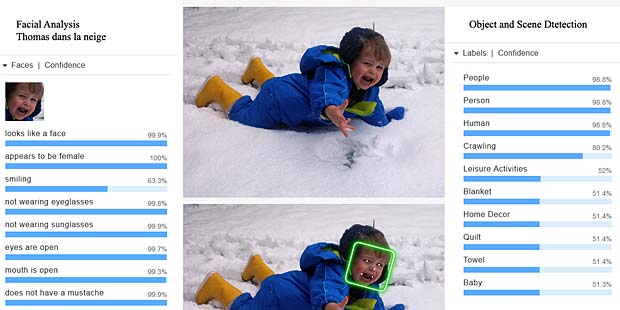
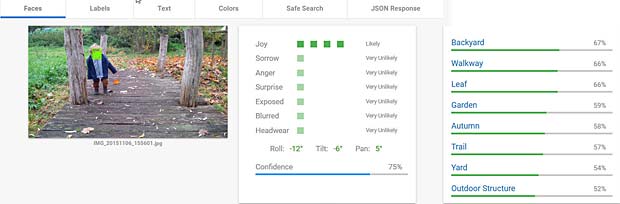 Google Vision voit de la joie dans le visage de Charles qui se trouve dehors, dans une sorte de jardin, avec des feuilles, en automne. Bonne interprétation.
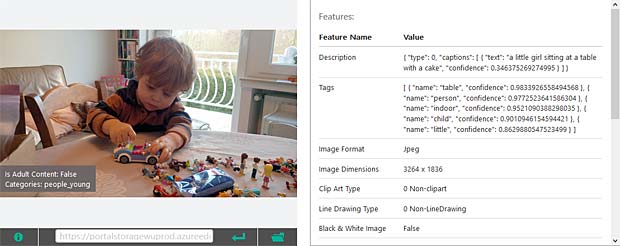
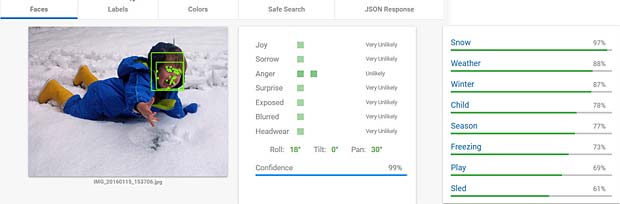
Google Vision voit de la joie dans le visage de Charles qui se trouve dehors, dans une sorte de jardin, avec des feuilles, en automne. Bonne interprétation.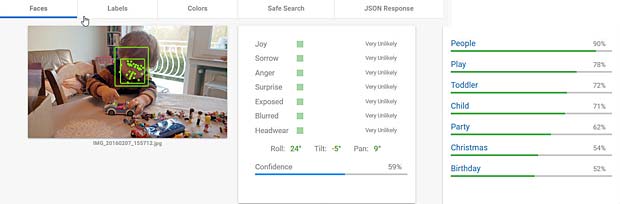 Google Vision estime que Charles fête son anniversaire à Noël. En réalité il joue en février 2016 avec du Lego. Echec.
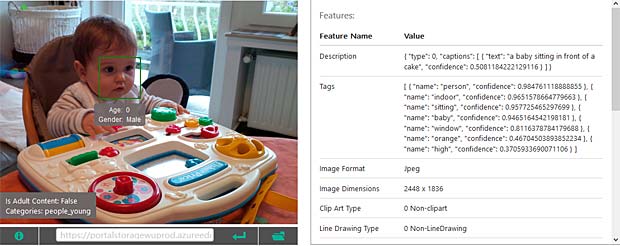
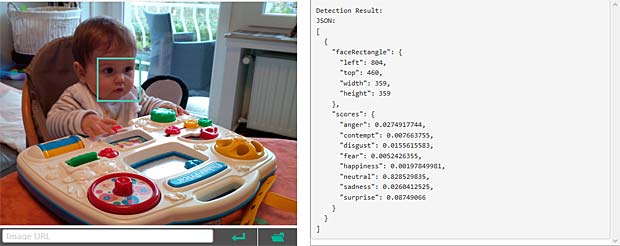
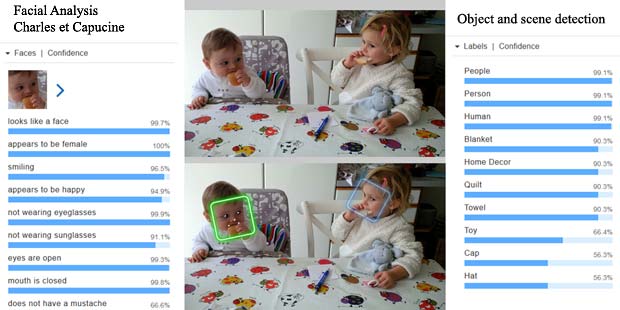
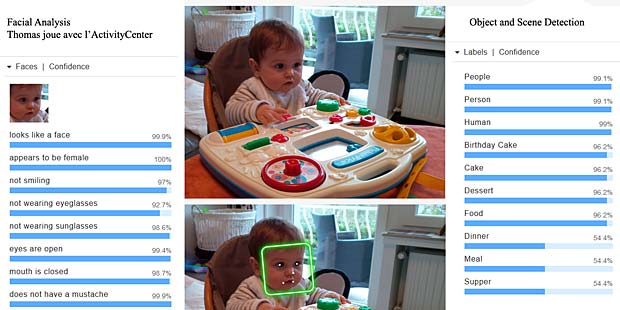
Google Vision estime que Charles fête son anniversaire à Noël. En réalité il joue en février 2016 avec du Lego. Echec.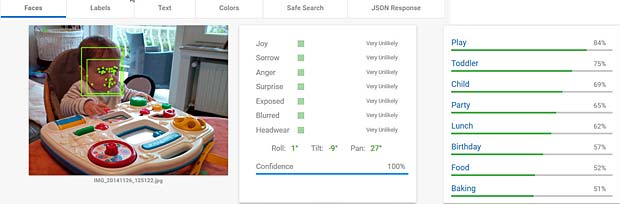 L’activity-Center Fisher-Prize de Thomas fait penser Google Vision à un anniversaire et à de la nourriture.
L’activity-Center Fisher-Prize de Thomas fait penser Google Vision à un anniversaire et à de la nourriture.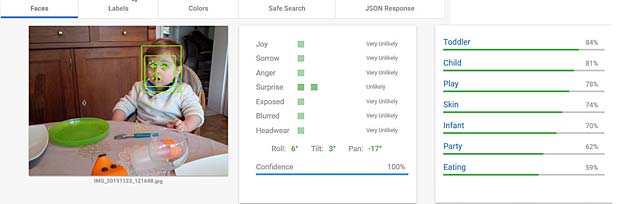

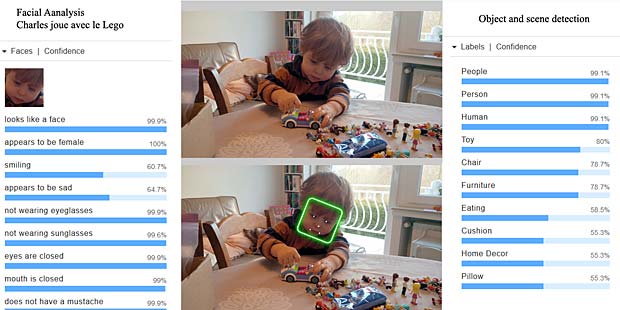






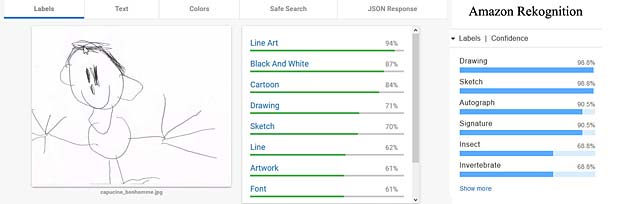 Le dessin du bonhomme est reconnu par Google Vision (résultats au milieu) comme cartoon et oeuvre d’art, tandis que Amazon Rekognition voit une signature ou un insecte. Aucun des deux systèmes reconnaît une figure humaine.
Le dessin du bonhomme est reconnu par Google Vision (résultats au milieu) comme cartoon et oeuvre d’art, tandis que Amazon Rekognition voit une signature ou un insecte. Aucun des deux systèmes reconnaît une figure humaine.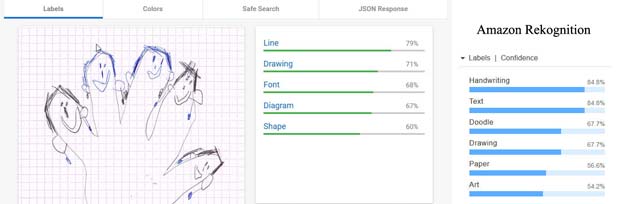 Les visages avec des boucles d’oreille qui ornent le contour de la main de Capucine ne sont pas identifiés comme tels par aucun des systèmes. Ce sont des lignes, des dessins, des formes ou diagrammes. Amazon Rekognition est au moins d’avis qu’il s’agit de l’art.
Les visages avec des boucles d’oreille qui ornent le contour de la main de Capucine ne sont pas identifiés comme tels par aucun des systèmes. Ce sont des lignes, des dessins, des formes ou diagrammes. Amazon Rekognition est au moins d’avis qu’il s’agit de l’art.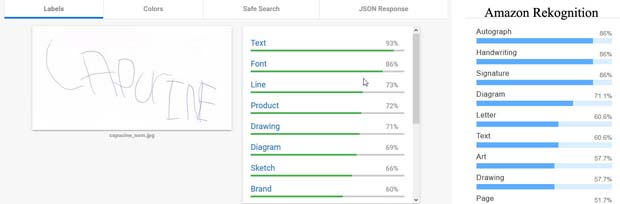 En ce qui concerne le nom de Capucine, Google Vision estime qu’il s’agit d’un texte, mais n’est pas en mesure de le lire. L’OCR (optical character recognition) ne fait pas encore partie du produit Amazon Rekognition. Ce système détecte toutefois qu’il s’agit de textes, de caractères, d’une signature ou d’un autographe.
En ce qui concerne le nom de Capucine, Google Vision estime qu’il s’agit d’un texte, mais n’est pas en mesure de le lire. L’OCR (optical character recognition) ne fait pas encore partie du produit Amazon Rekognition. Ce système détecte toutefois qu’il s’agit de textes, de caractères, d’une signature ou d’un autographe.