Mise à jour : 1er août 2022
Introduction
Suite à mes premières expériences avec l’apprentissage profond (deep machine learning) pour réaliser un système de synthèse vocale pour la langue luxembourgeoise, dont les résultats ont été publiés sur mon blog “Mäi Computer schwätzt Lëtzebuergesch“, j’ai constaté que le recours au seul corpus de données Marylux-648 ne permet pas d’entraîner un meilleur système que le modèle VITS, présenté le 6 janvier 2022. Il fallait donc étendre la base de données TTS (text-to-speech) luxembourgeoise pour améliorer les résultats.
Le ZLS (Zentrum fir d’Lëtzebuerger Sprooch) m’a offert sa collaboration pour enregistrer un texte d’envergure par deux orateurs, l’un féminin, l’autre masculin, dans son studio d’enregistrement. Comme un tel projet demande de grands efforts, j’ai proposé d’explorer d’abord tous les enregistrements audio, avec transcriptions, qui sont disponibles sur le web. Une telle approche est typique pour le Grand-Duché de Luxembourg : réaliser des grands exploits avec un minimum de moyens.
Une première source pour l’extension du corpus TTS constitue les dictées luxembourgeoises publiées sur le site web infolux de l’Institut de linguistique et de littératures luxembourgeoises de l’Université du Luxembourg, dirigé par Pr Peter Gilles. Avec l’accord aimable de tous les ayants droit, j’ai converti les fichiers audio et texte de ces dictées dans un format qui convient pour l’apprentissage profond, avec les mêmes procédures que celles décrites dans mon dépôt Github Marylux-648.
Pour faciliter l’apprentissage du corpus TTS luxembourgeois étendu, j’ai seulement retenu les dictées lues par des orateurs féminins. Heureusement c’est le cas pour la majorité des dictées. Les oratrices sont Caroline Doehmer, Nathalie Entringer et Sara Martin.
Les résultats sont les suivants:
- 10 Übungsdictéeën : 179 échantillons, 2.522 mots, ca 26 minutes
- 100 Sätz : 100 échantillons, 1.117 mots, ca 9 minutes
- Walfer-Dictéeën : 78 échantillons, 1.177 mots, ca 9 minutes
Ensemble avec Marylux-648, la nouvelle base de données TTS comprend 1005 échantillons, avec quatre voix. J’appelle ce corpus “Luxembourgish-TTS-Corpus-4-1005”. Dans une première étape j’ai utilisé ces données pour entraîner le modèle COQUI-TTS-VITS-multispeaker à partir de zéro.
Entraînement TTS avec quatre voix à partir de zéro
Après 32.200 itérations, les métriques des performances du modèle, affichés régulièrement dans les logs lors de l’entraînement, n’ont plus progressé. Mais comme le best_model.pth.tar, sauvegardé à cette occasion, n’est pas nécessairement le plus performant pour la synthèse de textes luxembourgeois inconnus, j’ai continué l’entraînement jusqu’à 76.000 itérations. Le checkpoint le plus avancé est dénommé checkpoint_76000.pth.tar.
Lors de la synthèse vocale, il faut spécifier non seulement le texte à parler, le fichier de configuration, le fichier du modèle TTS et le nom du ficher audio à sauvegarder, mais également la voix à utiliser pour la synthèse. Comme dans mes expériences précédentes, j’ai utilisé la fable “De Nordwand an d’Sonn” comme texte à synthétiser. A titre d’information j’indique un exemple de commande entrée dans le terminal linux pour procéder à la synthèse.
tts --text "An der Zäit hunn sech den Nordwand an d’Sonn gestridden, wie vun hinnen zwee wuel méi staark wier, wéi e Wanderer, deen an ee waarme Mantel agepak war, iwwert de Wee koum. Si goufen sech eens, datt deejéinege fir dee Stäerkste gëlle sollt, deen de Wanderer forséiere géif, säi Mantel auszedoen. Den Nordwand huet mat aller Force geblosen, awer wat e méi geblosen huet, wat de Wanderer sech méi a säi Mantel agewéckelt huet. Um Enn huet den Nordwand säi Kampf opginn. Dunn huet d’Sonn d’Loft mat hire frëndleche Strale gewiermt, a schonn no kuerzer Zäit huet de Wanderer säi Mantel ausgedoen. Do huet den Nordwand missen zouginn, datt d’Sonn vun hinnen zwee dee Stäerkste wier." --use_cuda True --config_path /media/mbarnig/T7/lb-vits-multispeaker/vits_vctk-January-21-2022_07+56AM-c63bb481/config.json --model_path /media/mbarnig/T7/lb-vits-multispeaker/vits_vctk-January-21-2022_07+56AM-c63bb481/checkpoint_76000.pth.tar --out_path /media/mbarnig/T7/lb-vits/vits_vctk-January-21-2022_07+56AM-c63bb481/walfer_checkpoint_76000.wav --speakers_file_path /media/mbarnig/T7/lb-vits-multispeaker/vits_vctk-January-21-2022_07+56AM-c63bb481/speakers.json --speaker_idx "VCTK_walfer"Je vais présenter ci-après les auditions pour les différents cas de figure :
Voix “Judith”
Voix “Caroline”
Voix “Sara”
Voix “Nathalie”
Même si les résultats sont impressionnants à la première écoute, il ne s’agit pas encore de l’état d’art en matière d’apprentissage profond pour la création d’un modèle de synthèse vocale.
Entraînement TTS avec quatre voix et apprentissage par transfert
Un des atouts des réseaux neuronaux qui sont à la base de l’apprentissage profond des machines est l’apprentissage par transfert (transfer learning). Wikipedia le décrit comme suit :
L’apprentissage par transfert est l’un des champs de recherche de l’apprentissage automatique qui vise à transférer des connaissances d’une ou plusieurs tâches sources vers une ou plusieurs tâches cibles. Il peut être vu comme la capacité d’un système à reconnaître et appliquer des connaissances et des compétences, apprises à partir de tâches antérieures, sur de nouvelles tâches ou domaines partageant des similitudes.
Dans le cas de la synthèse vocale, l’apprentissage par transfert consiste à utiliser un modèle TTS, entraîné avec une large base de données dans une langue à ressources riches, pour l’entraîner dans la suite avec une petite base de données dans une langue à faibles ressources, comme le Luxembourgeois.
La communauté COQUI-TTS partage un modèle TTS-VITS anglais, entraîné avec le corpus VCTK pendant un million d’itérations et avec un large jeu de phonèmes IPA, y compris ceux que j’ai retenu pour mes modules de phonémisation luxembourgeoise gruut et espeak-ng. La base de données de référence VCTK comprend environ 44.000 échantillons, prononcés par 46 orateurs et 63 oratrices.
J’ai téléchargé ce modèle tts_models–en–ljspeech–vits et j’ai continué son entraînement avec ma base de données “Luxembourgish-TTS-Corpus-4-1005”. Le best_model.pth.tar a été sauvegardé à 1.016.100 itérations. Après mon interruption de l’entraînement, le dernier checkpoint a été enregistré à 1.034.000 itérations. Je présente ci-après seulement les auditions des synthèses réalisées avec ce checkpoint.
Voix “Judith”
Voix “Caroline”
Voix “Sara”
Voix “Nathalie”
Spécifications techniques
Contrairement à ma première contribution “Mäi Computer schwätzt Lëtzebuergesch“, je n’ai pas présenté des détails techniques dans le présent rapport pour faciliter la lecture. Je vais toutefois publier prochainement les graphiques, métriques et autres caractéristiques techniques en relation avec les entraînements sur mon dépôt Github Luxembourgish-TTS-Corpus-4-1005. Avis aux amateurs des technologies de l’intelligence artificielle.
Conclusions
Les résultats obtenus avec l’apprentissage par transfert donnent envie à parfaire le modèle de synthèse vocale luxembourgeois. Plusieurs pistes restent à creuser :
- création d’une base de données TTS luxembourgeoise multi-voix plus large avec les contenus audio et texte disponible sur le site web de RTL-Radio. Un grand Merci aux responsables de RTL qui m’ont autorisé à utiliser les ressources afférentes pour constituer un tel corpus.
- utilisation d’un modèle TTS pré-entraîné avec une large base de données allemande, au lieu du modèle TTS anglais, pour l’apprentissage par transfert
- utilisation d’un modèle TTS pré-entraîné multi-voix et multilingue pour l’apprentissage par transfert
- perfectionnement du modèle de phonémisation luxembourgeoise
- réalisation de tests avec d’autres architectures de modèles TTS
En parallèle à mes expériences de création d’un système de synthèse vocale luxembourgeoise, j’ai démarré les premiers essais avec un système de reconnaissance de la langue luxembourgeoise (STT : speech to text) avec transcription automatique, en utilisant mes bases de données TTS luxembourgeoises, converties dans un format approprié. Les premiers résultats sont encourageants.
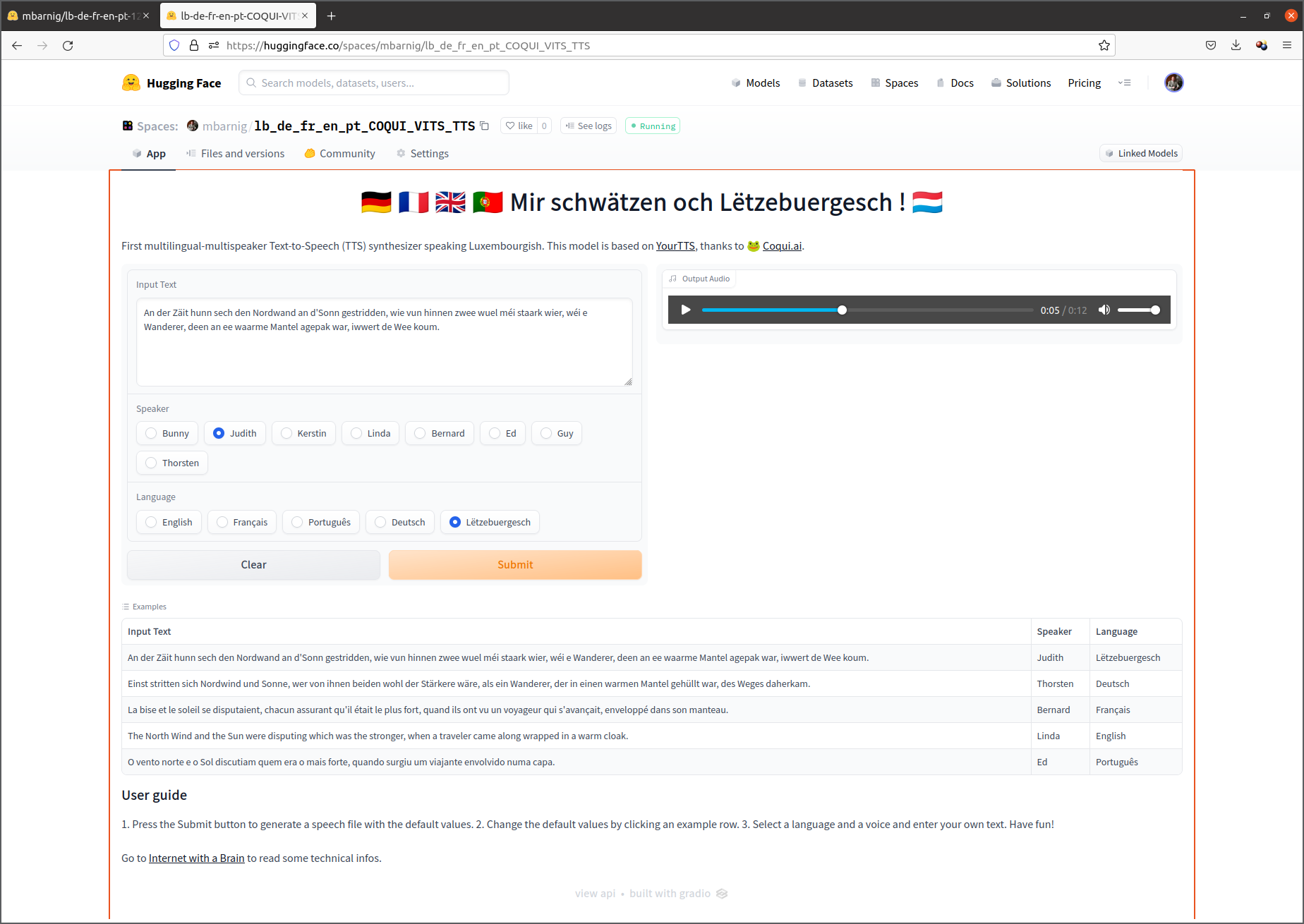
Application interactive de démonstration
J’ai publié le 12 juillet 2022 une application interactive étendue multilingue et multivoix lb-de-en-fr-pt-COQUI-STT de mon modèle sur la plateforme d’intelligence artificielle Huggingface.