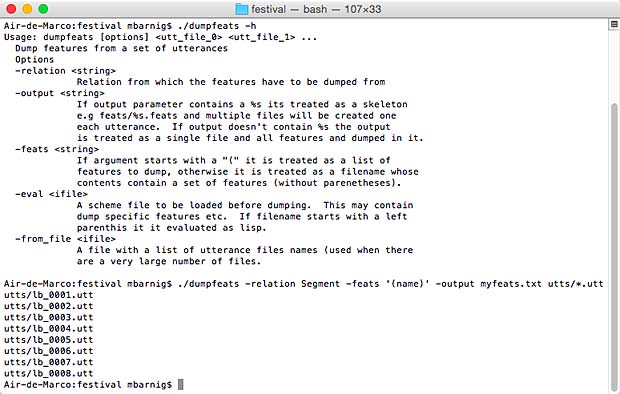
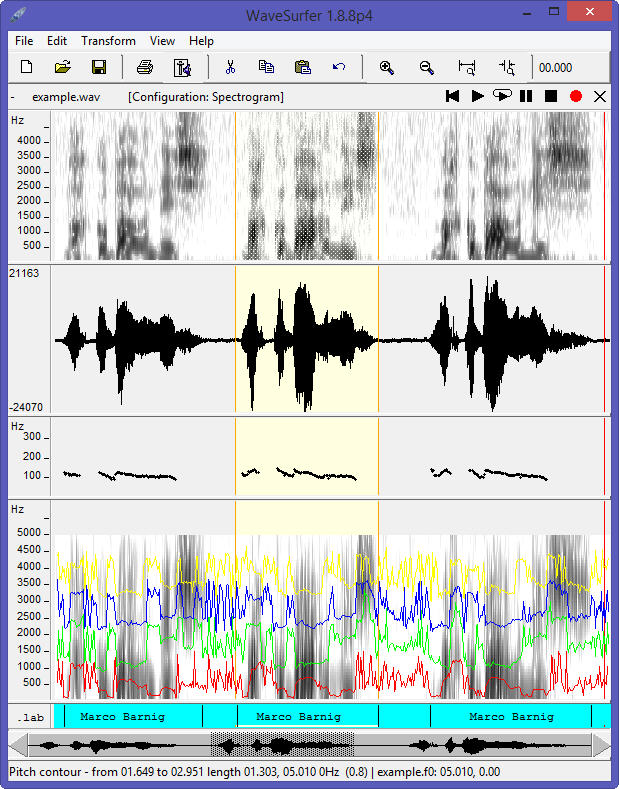
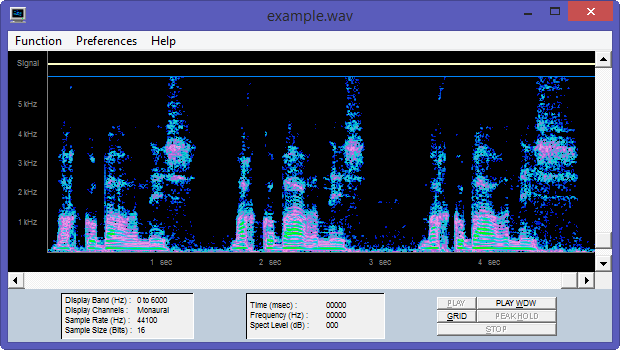
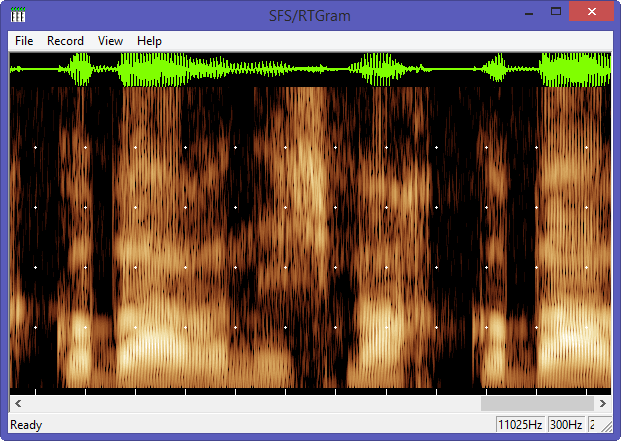
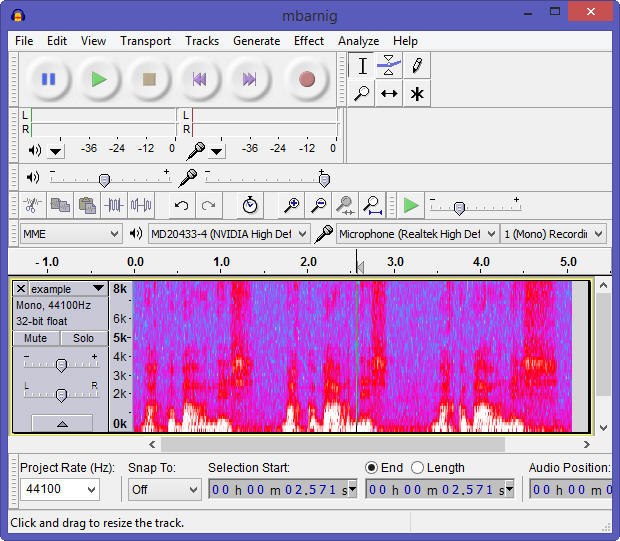
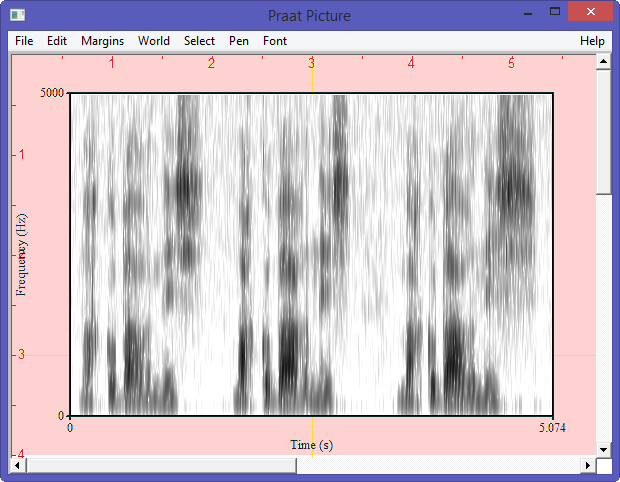
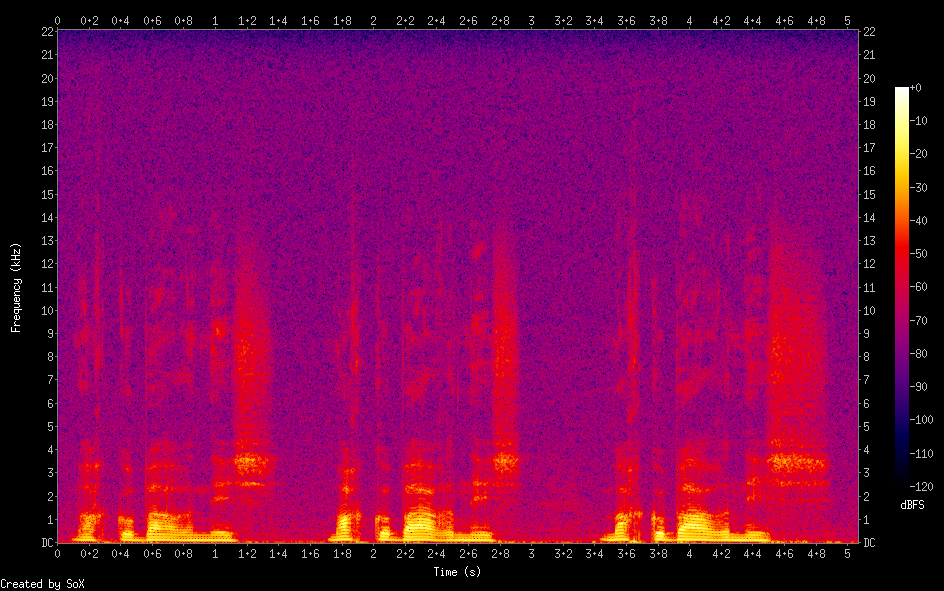
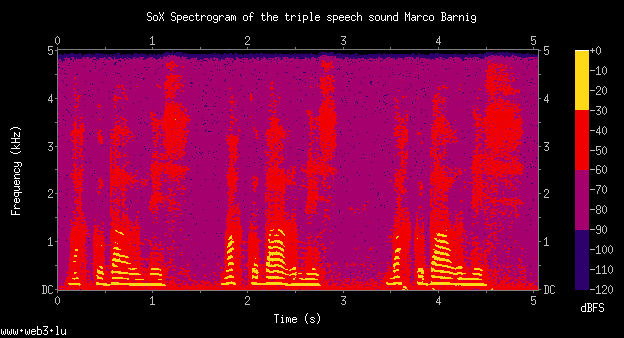
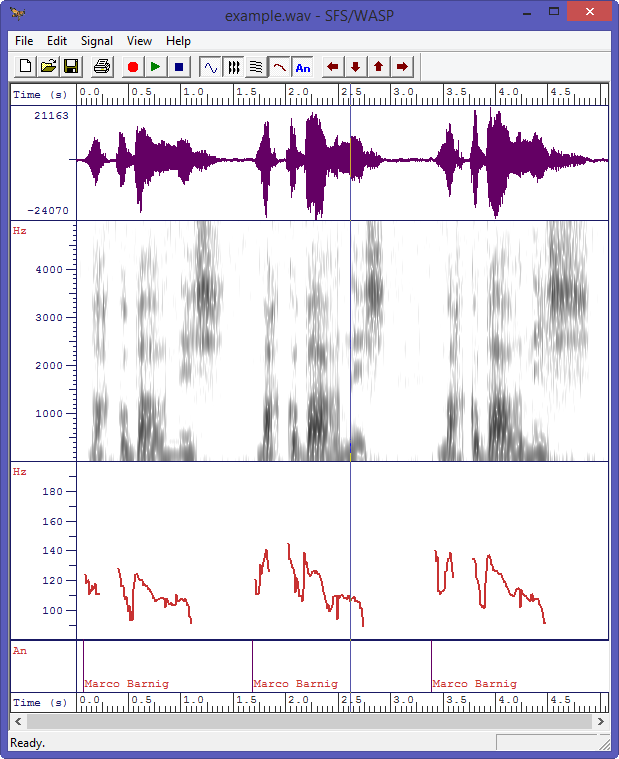
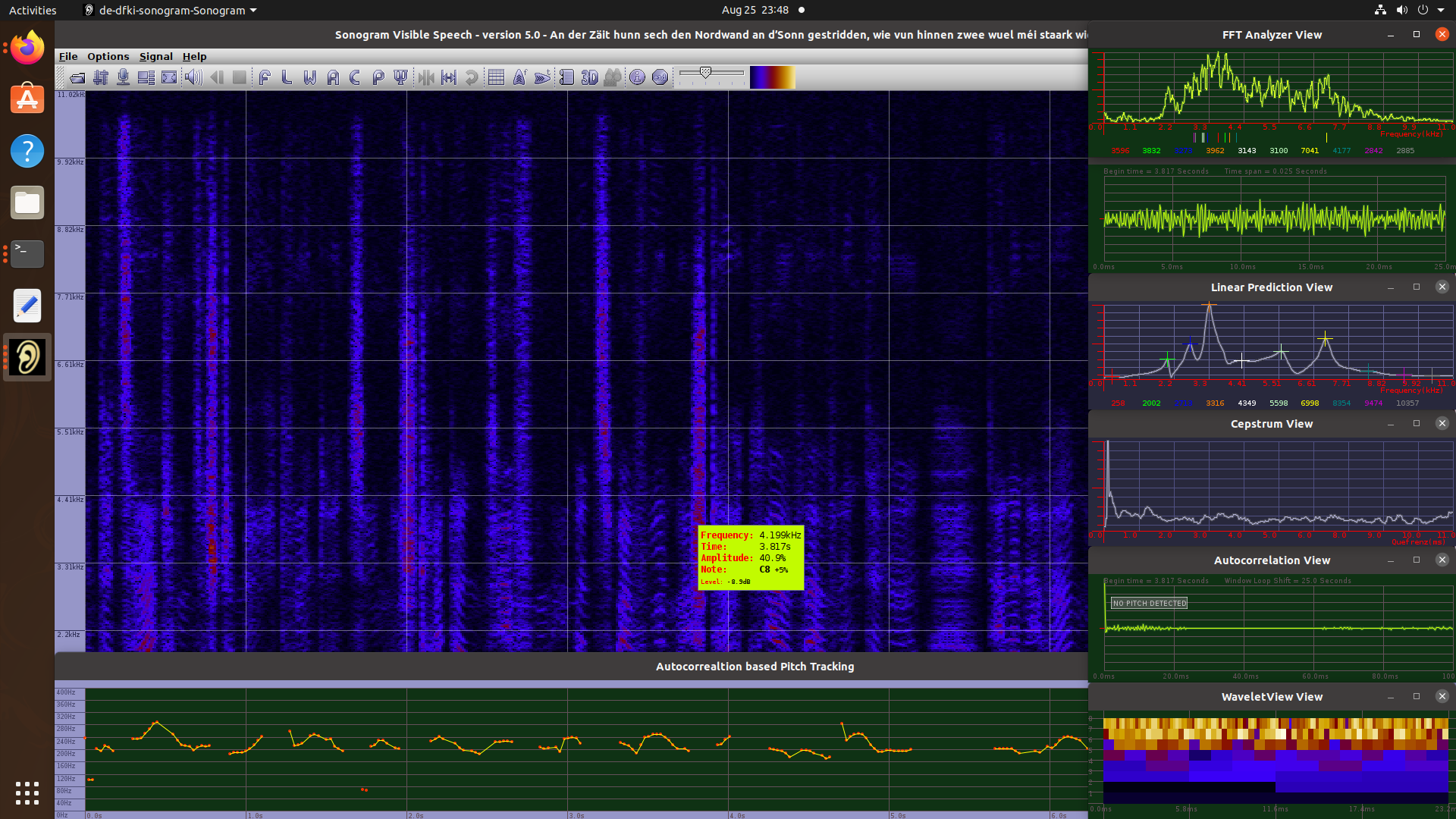
Referring to my recent post about Festival, I am glad to announce that I was successful in building and testing a new uniphone voice (english) with my own prompt recordings. The goal is to set up my system to create a luxembourgish synthetic voice for the Festival package.
The list of the different steps is shown below :
• (creation of the voice directory mbarnig_en_marco)
• $FESTVOXDIR/src/unitsel/setup_clunits mbarnig en marco uniphone
• (define a phoneset)
• (define a lexicon)
• festival -b festvox/build_clunits.scm '(build_prompts_waves
"etc/uniphone.data")'
• (uncomment the line USE_SOX=1 in the script prompt_them)
• ./bin/prompt_them etc/uniphone.data
• ./bin/make_labs prompt-wav/*.wav
• festival -b festvox/build_clunits.scm '(build_utts
"etc/uniphone.data")'
• (copy etc/uniphone.data into etc/txt.done.data)
• ./bin/make_pm_wave wav/*.wav
• ./bin/make_mcep wav/*.wav
• festival -b festvox/build_clunits.scm '(build_clunits
"etc/uniphone.data")'
• (copy data in Festival voice directory)
• festival> (voice_mbarnig_en_marco_clunits)
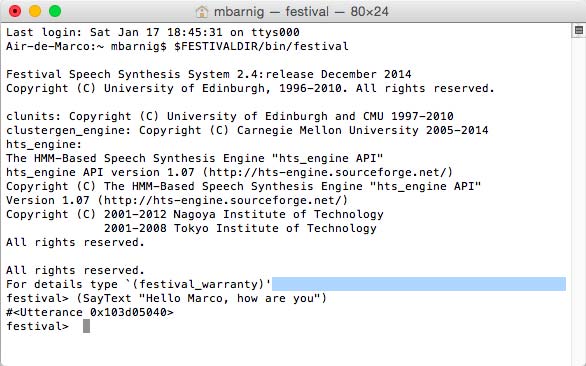
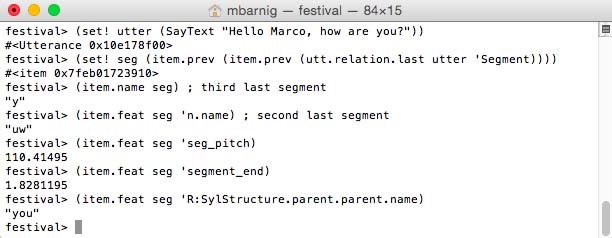
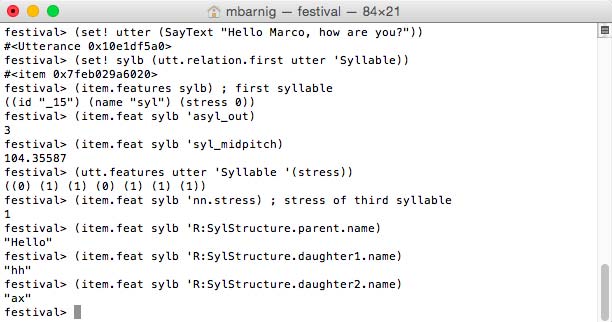
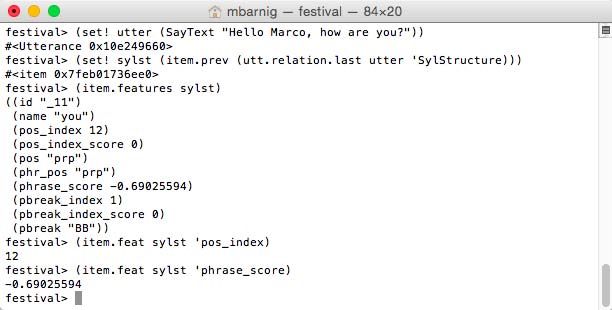
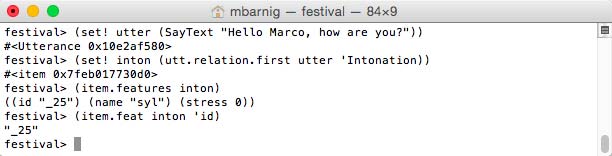
• festival> (SayText "Hello Marco, how are you?")1. Voice Folder
First I created a new voice folder mbarnig_en_marco inside the Festival_TTS/festvox/ directory and opened a terminal window inside this new folder.
2. Clunits Setup
I launched the script
$FESTVOXDIR/src/unitsel/setup_clunits mbarnig en marco uniphoneto construct the voice folder structure and copy there the template files for voice building.
The arguments of the setup script setup_clunits are :
- institution : mbarnig
- language : en
- speaker : marco
- standard prompt list : uniphone

Festival : setup_clunits
The following folders are created inside the voice directory mbarnig_en_marco :
- bin
- cep
- emu
- etc
- f0
- festival
- festvox
- group
- lab
- lar
- lpc
- mcep
- phr
- pm
- pm_lab
- prompt_cep
- prompt_lab
- prompt_utt
- prompt_wav
- recording
- scratch
- syl
- versions
- wav
- wrd
The following programs are copied into the 1sr folder (mbarnig_en_marco/bin) :
- add_noise
- contour_powernormalize
- do_build
- find_db_duration
- find_num_available_cpu
- find_powercontours
- find_poerfactors
- get_lars
- get_wavs
- make_cmm
- make_dist
- make_f0
- make_labs
- make_lpc
- make_mcep
- make_pm
- make_pm_fix
- make_pm_pmlab
- make_pm_wave
- make_pmlab_pm
- make_samples
- prompt_them
- prune_middle_silence
- prune_silence
- reduce_prompts
- simple_powernormalize
- sphinx_lab
- sphinxtrain
- synthfile
- traintest
- ws
The following files are created inside the 4th folder (mbarnig_en_marco/etc) :
- emu_f0.tpl
- emu_hier.tpl
- emu_lab.tpl
- emu_pm.tpl
- uniphone.data
- voice.defs
- ws_festvox.conf
The following sub-folders (most empty) are created inside the 6th folder (mbarnig_en_marco/festival) :
- clunits, including a file all.desc
- coeffs
- disttabs
- dur
- f0
- feats
- phrbrk
- trees
- utts
The following scripts are created inside the 7th folder (mbarnig_en_marco/festvox) :
- build_clunits.scm
- build_st.scm
- mbarnig_en_marco_clunits.scm
- mbarnig_en_marco_duration.scm
- mbarnig_en_marco_durdata.scm
- mbarnig_en_marco_f0model.scm
- mbarnig_en_marco_intonation.scm
- mbarnig_en_marco_lexicon.scm
- mbarnig_en_marco_other.scm
- mbarnig_en_marco_phoneset.scm
- mbarnig_en_marco_phrasing.scm
- mbarnig_en_marco_tagger.scm
- mbarnig_en_marco_tokenizer.scm
The other listed folders are empty.
The file uniphone.data in the mbarnig_en_marco/etc folder contains the following minimal prompt-set :
( uniph_0001 "a whole joy was reaping." )
( uniph_0002 "but they've gone south." )
( uniph_0003 "you should fetch azure mike." )These 3 sentences contain each of the english phonemes once. The prompt list is coded in the standard Festival data-format. The spaces after the left parantheses are required.
The file voice.defs in the mbarnig_en_marco/etc folder contains the following parameters :
FV_INST=mbarnig
FV_LANG=en
FV_NAME=marco
FV_TYPE=clunits
FV_VOICENAME=$FV_INST"_"$FV_LANG"_"$FV_NAME
FV_FULLVOICENAME=$FV_VOICENAME"_"FV_TYPEThe file ws_festvox.conf in the mbarnig_en_marco/etc folder is automatically generated by WaveSurfer.
Phoneset Definition
The phoneset for the new voice is defined in the script mbarnig_en_marco_phoneset.scm. Referring to the english Festival radio phoneset, I modified the phoneset-script as follows :
;;; Phoneset for mbarnig_en_marco
;;;
(defPhoneSet
mbarnig_en_marco
;;; Phone Features
(;; vowel or consonant
(vc + -)
;; vowel length: short long dipthong schwa
(vlng s l d a 0)
;; vowel height: high mid low
(vheight 1 2 3 0)
;; vowel frontness: front mid back
(vfront 1 2 3 0)
;; lip rounding
(vrnd + - 0)
;; consonant type: stop fricative affricate nasal lateral approximant
(ctype s f a n l r 0)
;; place of articulation: labial alveolar palatal labio-dental
;; dental velar glottal
(cplace l a p b d v g 0)
;; consonant voicing
(cvox + - 0)
)
;; Phone set members
(
;; Note these features were set by awb so they are wrong !!!
(aa + l 3 3 - 0 0 0) ;; father
(ae + s 3 1 - 0 0 0) ;; fat
(ah + s 2 2 - 0 0 0) ;; but
(ao + l 3 3 + 0 0 0) ;; lawn
(aw + d 3 2 - 0 0 0) ;; how
(ax + a 2 2 - 0 0 0) ;; about
(axr + a 2 2 - r a +)
(ay + d 3 2 - 0 0 0) ;; hide
(b - 0 0 0 0 s l +)
(ch - 0 0 0 0 a p -)
(d - 0 0 0 0 s a +)
(dh - 0 0 0 0 f d +)
(dx - a 0 0 0 s a +) ;; ??
(eh + s 2 1 - 0 0 0) ;; get
(el + s 0 0 0 l a +)
(em + s 0 0 0 n l +)
(en + s 0 0 0 n a +)
(er + a 2 2 - r 0 0) ;; always followed by r (er-r == axr)
(ey + d 2 1 - 0 0 0) ;; gate
(f - 0 0 0 0 f b -)
(g - 0 0 0 0 s v +)
(hh - 0 0 0 0 f g -)
(hv - 0 0 0 0 f g +)
(ih + s 1 1 - 0 0 0) ;; bit
(iy + l 1 1 - 0 0 0) ;; beet
(jh - 0 0 0 0 a p +)
(k - 0 0 0 0 s v -)
(l - 0 0 0 0 l a +)
(m - 0 0 0 0 n l +)
(n - 0 0 0 0 n a +)
(nx - 0 0 0 0 n d +) ;; ???
(ng - 0 0 0 0 n v +)
(ow + d 2 3 + 0 0 0) ;; lone
(oy + d 2 3 + 0 0 0) ;; toy
(p - 0 0 0 0 s l -)
(r - 0 0 0 0 r a +)
(s - 0 0 0 0 f a -)
(sh - 0 0 0 0 f p -)
(t - 0 0 0 0 s a -)
(th - 0 0 0 0 f d -)
(uh + s 1 3 + 0 0 0) ;; full
(uw + l 1 3 + 0 0 0) ;; fool
(v - 0 0 0 0 f b +)
(w - 0 0 0 0 r l +)
(y - 0 0 0 0 r p +)
(z - 0 0 0 0 f a +)
(zh - 0 0 0 0 f p +)
(pau - 0 0 0 0 0 0 -)
(h# - 0 0 0 0 0 0 -)
(brth - 0 0 0 0 0 0 -)
)
)
(PhoneSet.silences '(pau))
(define (mbarnig_en_marco::select_phoneset)
"(mbarnig_en_marco::select_phoneset)
Set up phone set for mbarnig_en_marco."
(Parameter.set 'PhoneSet 'mbarnig_en_marco)
(PhoneSet.select 'mbarnig_en_marco)
)
(define (mbarnig_en_marco::reset_phoneset)
"(mbarnig_en_marco::reset_phoneset)
Reset phone set for mbarnig_en_marco."
t
)
(provide 'mbarnig_en_marco_phoneset)Lexicon Creation
Without a lexicon, the result of a building command generates unknown words messages
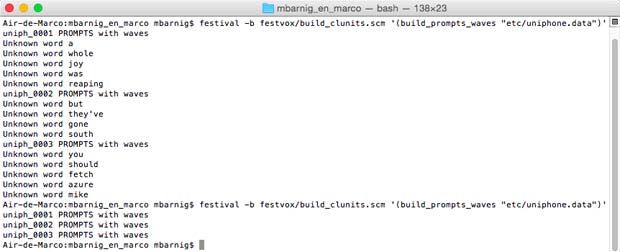
Festival : unknown words without lexicon
The lexicon for the new voice is defined in the script mbarnig_en_marco_lexicon.scm. Referring the the english Festival cmu lexicon, I modified the lexicon-script as follows :
;;; Lexicon, LTS and Postlexical rules for mbarnig_en_marco
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;;;
;;; CMU lexicon for US English
;;;
;;; Load any necessary files here
(require 'postlex)
(setup_cmu_lex)
(define (mbarnig_en_marco::select_lexicon)
"(mbarnig_lx_marco::select_lexicon)
Set up the lexicon for mbarnig_lx_marco."
(lex.select "cmu")
;; Post lexical rules
(set! postlex_rules_hooks (list postlex_apos_s_check))
(set! postlex_vowel_reduce_cart_tree nil) ; no reduction
)
(define (mbarnig_lx_marco::reset_lexicon)
"(mbarnig_lx_marco::reset_lexicon)
Reset lexicon information."
t
)
(provide 'mbarnig_lx_marco_lexicon)Building Prompts
The second command
festival -b festvox/build_clunits.scm '(build_prompts_waves
"etc/uniphone.data")'generates synthesized waveforms to act as prompts and timing cues. The nearest available voice (in this case kal_diphone) is used for synthesizing. The generated files are also used in aligning the spoken data. The -b option (–batch) avoids switching in the interactive Festival mode.

Festival : build_prompts_waves
The following files are created :
- folder prompt-lab : files uniph_0001.lab, uniph_0002.lab and uniph_0003.lab
- folder prompt-utt : files uniph_0001.utt, uniph_0002.utt and uniph_0003.utt
- folder prompt-wav : files uniph_0001.wav, uniph_0002.wav and uniph_0003.wav
The uniph_xxxx.lab files have the following type of content :
#
0.1100 100 pau
0.2200 100 ax
0.3300 100 hh
0.4400 100 ow
0.5500 100 l
0.6600 100 jh
0.7700 100 oy
0.8800 100 w
0.9900 100 aa
1.1000 100 z
1.2100 100 r
1.3200 100 iy
1.4850 100 p
1.6500 100 ih
1.8150 100 ng
1.9250 100 pauThe uniph_xxxx.utt files have the following type of content :
EST_File utterance
DataType ascii
version 2
EST_Header_End
Features max_id 77 ; type Text ;
iform "\"a whole joy was reaping.\"" ;
Stream_Items
1 id _1 ; name a ; whitespace "" ; prepunctuation "" ;
2 id _2 ; name whole ; whitespace " " ; prepunctuation "" ;
3 id _3 ; name joy ; whitespace " " ; prepunctuation "" ;
4 id _4 ; name was ; whitespace " " ; prepunctuation "" ;
5 id _5 ; name reaping ; punc . ; whitespace " " ;
prepunctuation "" ;
6 id _10 ; name reaping ; pbreak B ; pos nil ;
7 id _11 ; name . ; pbreak B ; pos punc ;
8 id _9 ; name was ; pbreak NB ; pos nil ;
9 id _8 ; name joy ; pbreak NB ; pos nil ;
10 id _7 ; name whole ; pbreak NB ; pos nil ;
11 id _6 ; name a ; pbreak NB ; pos dt ;
12 id _12 ; name B ;
13 id _13 ; name syl ; stress 0 ;
14 id _15 ; name syl ; stress 1 ;
15 id _19 ; name syl ; stress 1 ;
16 id _22 ; name syl ; stress 1 ;
17 id _26 ; name syl ; stress 1 ;
18 id _29 ; name syl ; stress 0 ;
19 id _33 ; name pau ; dur_factor 1 ; end 0.11 ;source_end 0.101815 ;
20 id _14 ; name ax ; dur_factor 1 ; end 0.22 ;source_end 0.235802 ;
21 id _16 ; name hh ; dur_factor 1 ; end 0.33 ;source_end 0.322177 ;
22 id _17 ; name ow ; dur_factor 1 ; end 0.44 ;source_end 0.493926 ;
23 id _18 ; name l ; dur_factor 1 ; end 0.55 ;source_end 0.626926 ;
24 id _20 ; name jh ; dur_factor 1 ; end 0.66 ;source_end 0.732624 ;
25 id _21 ; name oy ; dur_factor 1 ; end 0.77 ;source_end 0.900228 ;
26 id _23 ; name w ; dur_factor 1 ; end 0.88 ;source_end 1.06616 ;
27 id _24 ; name aa ; dur_factor 1 ; end 0.99 ;source_end 1.20716 ;
28 id _25 ; name z ; dur_factor 1 ; end 1.1 ;source_end 1.33726 ;
29 id _27 ; name r ; dur_factor 1 ; end 1.21 ;source_end 1.46326 ;
30 id _28 ; name iy ; dur_factor 1 ; end 1.32 ;source_end 1.58507 ;
31 id _30 ; name p ; dur_factor 1.5 ; end 1.485 ;source_end 1.71307 ;
32 id _31 ; name ih ; dur_factor 1.5 ; end 1.65 ;source_end 1.83979 ;
33 id _32 ; name ng ; dur_factor 1.5 ; end 1.815 source_end 2.02441 ;
34 id _34 ; name pau ; dur_factor 1 ; end 1.925 ;source_end 2.36643 ;
35 id _35 ; name Accented ;
36 id _36 ; name Accented ;
37 id _37 ; name Accented ;
38 id _38 ; name Accented ;
39 id _56 ; f0 110 ; pos 1.815 ;
40 id _54 ; f0 126.571 ; pos 1.31 ;
41 id _55 ; f0 116.286 ; pos 1.32 ;
42 id _53 ; f0 128.571 ; pos 1.11 ;
43 id _50 ; f0 130 ; pos 1.09 ;
44 id _51 ; f0 118.571 ; pos 1.1 ;
45 id _52 ; f0 118.571 ; pos 1.101 ;
46 id _49 ; f0 132 ; pos 0.78 ;
47 id _46 ; f0 132.286 ; pos 0.76 ;
48 id _47 ; f0 122 ; pos 0.77 ;
49 id _48 ; f0 122 ; pos 0.771 ;
50 id _45 ; f0 134.286 ; pos 0.56 ;
51 id _42 ; f0 135.714 ; pos 0.54 ;
52 id _43 ; f0 124.286 ; pos 0.55 ;
53 id _44 ; f0 124.286 ; pos 0.551 ;
54 id _41 ; f0 137.714 ; pos 0.23 ;
55 id _40 ; f0 127.714 ; pos 0.22 ;
56 id _39 ; f0 130 ; pos 0.11 ;
57 id _57 ; name pau-ax ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 9 ; end 0.172053 ; num_frames 17 ;
58 id _58 ; name ax-hh ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 5 ; end 0.288115 ; num_frames 11 ;
59 id _59 ; name hh-ow ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 2 ; end 0.406552 ; num_frames 11 ;
60 id _60 ; name ow-l ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 7 ; end 0.559239 ; num_frames 14 ;
61 id _61 ; name l-jh ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 5 ; end 0.673416 ; num_frames 10 ;
62 id _62 ; name jh-oy ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 4 ; end 0.82104 ; num_frames 13 ;
63 id _63 ; name oy-w ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 6 ; end 1.01148 ; num_frames 17 ;
64 id _64 ; name w-aa ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 4 ; end 1.1311 ; num_frames 11 ;
65 id _65 ; name aa-z ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 6 ; end 1.25207 ; num_frames 11 ;
66 id _66 ; name z-r ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 7 ; end 1.39807 ; num_frames 14 ;
67 id _67 ; name r-iy ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 5 ; end 1.52951 ; num_frames 12 ;
68 id _68 ; name iy-p ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 4 ; end 1.64963 ; num_frames 11 ;
69 id _69 ; name p-ih ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 5 ; end 1.78517 ; num_frames 13 ;
70 id _70 ; name ih-ng ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 4 ; end 1.91617 ; num_frames 12 ;
71 id _71 ; name ng-pau ; sig "[Val wave]" ; coefs "[Val track]" ;
middle_frame 9 ; end 2.19542 ; num_frames 27 ;
72 id _72 ; name coef ; coefs "[Val track]" ;
frame "[Val wavevector]" ;
73 id _73 ; name f0 ; f0 "[Val track]" ;
74 id _74 ; coefs "[Val track]" ; residual "[Val wave]" ;
75 id _75 ;
76 id _76 ; map "[Val ivector]" ;
77 id _77 ; wave "[Val wave]" ;
End_of_Stream_Items
Relations
Relation Token ; ()
6 11 1 0 0 0
1 1 0 6 2 0
7 10 2 0 0 0
2 2 0 7 3 1
8 9 3 0 0 0
3 3 0 8 4 2
9 8 4 0 0 0
4 4 0 9 5 3
10 6 5 0 11 0
11 7 0 0 0 10
5 5 0 10 0 4
End_of_Relation
Relation Word ; ()
1 11 0 0 2 0
2 10 0 0 3 1
3 9 0 0 4 2
4 8 0 0 5 3
5 6 0 0 0 4
End_of_Relation
Relation Phrase ; ()
2 11 1 0 3 0
3 10 0 0 4 2
4 9 0 0 5 3
5 8 0 0 6 4
6 6 0 0 0 5
1 12 0 2 0 0
End_of_Relation
Relation Syllable ; ()
1 13 0 0 2 0
2 14 0 0 3 1
3 15 0 0 4 2
4 16 0 0 5 3
5 17 0 0 6 4
6 18 0 0 0 5
End_of_Relation
Relation Segment ; ()
1 19 0 0 2 0
2 20 0 0 3 1
3 21 0 0 4 2
4 22 0 0 5 3
5 23 0 0 6 4
6 24 0 0 7 5
7 25 0 0 8 6
8 26 0 0 9 7
9 27 0 0 10 8
10 28 0 0 11 9
11 29 0 0 12 10
12 30 0 0 13 11
13 31 0 0 14 12
14 32 0 0 15 13
15 33 0 0 16 14
16 34 0 0 0 15
End_of_Relation
Relation SylStructure ; ()
8 20 7 0 0 0
7 13 1 8 0 0
1 11 0 7 2 0
10 21 9 0 11 0
11 22 0 0 12 10
12 23 0 0 0 11
9 14 2 10 0 0
2 10 0 9 3 1
14 24 13 0 15 0
15 25 0 0 0 14
13 15 3 14 0 0
3 9 0 13 4 2
17 26 16 0 18 0
18 27 0 0 19 17
19 28 0 0 0 18
16 16 4 17 0 0
4 8 0 16 5 3
22 29 20 0 23 0
23 30 0 0 0 22
20 17 5 22 21 0
24 31 21 0 25 0
25 32 0 0 26 24
26 33 0 0 0 25
21 18 0 24 0 20
5 6 0 20 6 4
6 7 0 0 0 5
End_of_Relation
Relation IntEvent ; ()
1 35 0 0 2 0
2 36 0 0 3 1
3 37 0 0 4 2
4 38 0 0 0 3
End_of_Relation
Relation Intonation ; ()
5 35 1 0 0 0
1 14 0 5 2 0
6 36 2 0 0 0
2 15 0 6 3 1
7 37 3 0 0 0
3 16 0 7 4 2
8 38 4 0 0 0
4 17 0 8 0 3
End_of_Relation
Relation Target ; ()
12 56 1 0 0 0
1 19 0 12 2 0
13 55 2 0 0 0
2 20 0 13 3 1
14 54 3 0 0 0
3 21 0 14 4 2
15 51 4 0 16 0
16 52 0 0 17 15
17 53 0 0 0 16
4 23 0 15 5 3
18 50 5 0 0 0
5 24 0 18 6 4
19 47 6 0 20 0
20 48 0 0 21 19
21 49 0 0 0 20
6 25 0 19 7 5
22 46 7 0 0 0
7 26 0 22 8 6
23 43 8 0 24 0
24 44 0 0 25 23
25 45 0 0 0 24
8 28 0 23 9 7
26 42 9 0 0 0
9 29 0 26 10 8
27 40 10 0 28 0
28 41 0 0 0 27
10 30 0 27 11 9
29 39 11 0 0 0
11 33 0 29 0 10
End_of_Relation
Relation Unit ; grouped 1 ;
1 57 0 0 2 0
2 58 0 0 3 1
3 59 0 0 4 2
4 60 0 0 5 3
5 61 0 0 6 4
6 62 0 0 7 5
7 63 0 0 8 6
8 64 0 0 9 7
9 65 0 0 10 8
10 66 0 0 11 9
11 67 0 0 12 10
12 68 0 0 13 11
13 69 0 0 14 12
14 70 0 0 15 13
15 71 0 0 0 14
End_of_Relation
Relation SourceCoef ; ()
1 72 0 0 0 0
End_of_Relation
Relation f0 ; ()
1 73 0 0 0 0
End_of_Relation
Relation TargetCoef ; ()
1 74 0 0 2 0
2 75 0 0 0 1
End_of_Relation
Relation US_map ; ()
1 76 0 0 0 0
End_of_Relation
Relation Wave ; ()
1 77 0 0 0 0
End_of_Relation
End_of_Relations
End_of_UtteranceRecording Prompts
Before launching the next command
./bin/prompt_them etc/uniphone.datato start the automatic recording of the prompts, I uncommented the line USE_SOX=1 in the prompt_them script to use the SOX package on the Mac instead of the na_play / na_record programs.
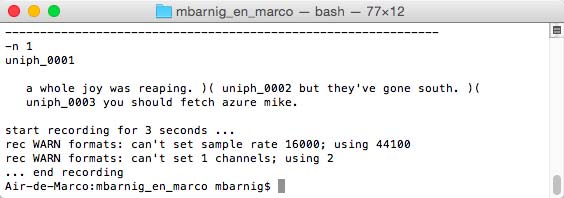
Festival : recording prompts
Festival plays the synthesized prompt before each record and calculates the recording duration, based on the synthesis. The recorded audio files are saved into the wav folder.
As the recording in the required format 16.000 Hz, mono 16 bits was not possible, I did a manual recording with the Audacity app and replaced the audio files in the wav folder.
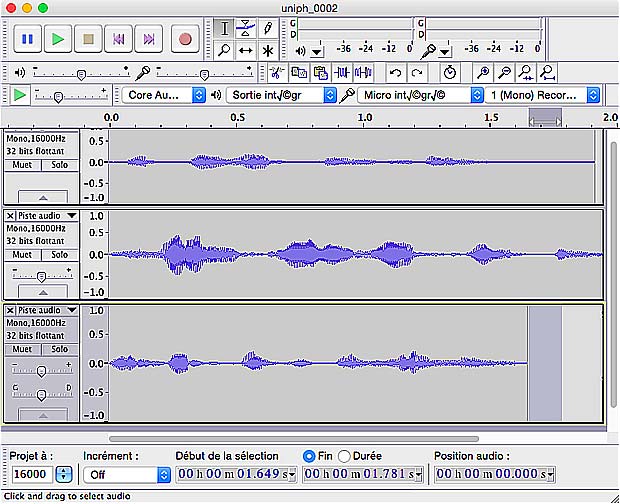
Audacity app to record prompts
Labeling
The labeling of the spoken prompts is done by matching the synthesized prompts with the spoken ones.
./bin/make_labs prompt_wav/*.wav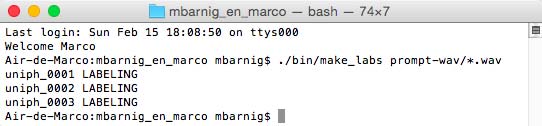
Festival : make_labs
The following files are created :
- folder cep : files uniph_0001.cep, uniph_0002.cep and uniph_0003.cep
- folder lab : files uniph_0001.lab, uniph_0002.lab and uniph_0003.lab
- folder prompt-cep : files uniph_0001.cep, uniph_0002.cep and uniph_0003.cep
The uniph_xxxx.cep files have the following type of content :
EST_File Track
DataType binary
ByteOrder 01
NumFrames 425
NumChannels 24
EqualSpace 0
BreaksPresent true
CommentChar ;
Channel_0 melcep_1
Channel_1 melcep_2
Channel_2 melcep_3
Channel_3 melcep_4
Channel_4 melcep_5
...
Channel_20 melcep_d_9
Channel_21 melcep_d_10
Channel_22 melcep_d_11
Channel_23 melcep_d_N
EST_Header_End
..........The uniph_xxxx.cep files have the following content :
separator ;
nfields 1
#
0.01500 26 pau
0.12500 26 ax
0.23500 26 hh
0.37000 26 ow
0.53000 26 l
0.65000 26 jh
0.87000 26 oy
1.08500 26 w
1.19500 26 aa
1.39500 26 z
1.45000 26 r
1.55500 26 iy
1.74500 26 p
1.91000 26 ih
2.07500 26 ng
2.12500 26 pauThe correct labeling can be checked with the WaveSurfer app.
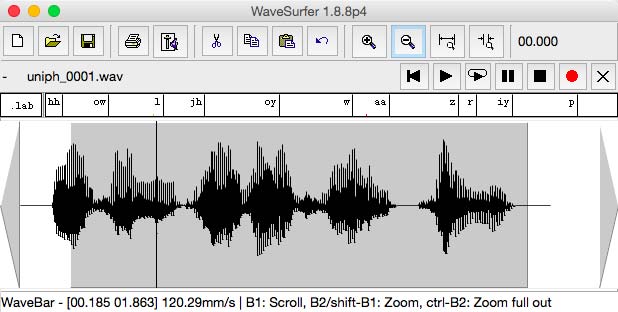
WafeSurfer . checking labels
The uniph_xxxx.cep files have the following type of content :
EST_File Track
DataType binary
ByteOrder 01
NumFrames 385
NumChannels 24
EqualSpace 0
BreaksPresent true
CommentChar ;
Channel_0 melcep_1
Channel_1 melcep_2
Channel_2 melcep_3
Channel_3 melcep_4
Channel_4 melcep_5
Channel_5 melcep_6
...
Channel_19 melcep_d_8
Channel_20 melcep_d_9
Channel_21 melcep_d_10
Channel_22 melcep_d_11
Channel_23 melcep_d_N
EST_Header_End
....Creating Utterances
After labeling the utterance structure is created with the command
festival -b festvox/build_clunits.scm '(build_utts
"etc/uniphone.data")'
Festival : build_utts
The 3 files uniph_0001.utt, uniph_0002.utt and uniph_0003.utt are saved in the folder festival/utts. They have the following type of content :
EST_File utterance
DataType ascii
version 2
EST_Header_End
Features max_id 94 ; type Text ;
iform "\"a whole joy was reaping.\"" ;
filename prompt-utt/uniph_0001.utt ;
fileid uniph_0001 ;
Stream_Items
1 id _1 ; name a ; whitespace "" ; prepunctuation "" ;
2 id _2 ; name whole ; whitespace " " ; prepunctuation "" ;
3 id _3 ; name joy ; whitespace " " ; prepunctuation "" ;
...
1 76 0 0 0 0
End_of_Relation
Relation Phrase ; ()
2 11 1 0 3 0
3 10 0 0 4 2
4 9 0 0 5 3
5 8 0 0 6 4
6 6 0 0 0 5
1 77 0 2 0 0
End_of_Relation
End_of_Relations
End_of_Utterancetxt.done.data
The next scripts are looking for the txt.done.data file instead of the uniphone.data file. Copying the uniphone.data file and renaming it to txt.done.data solves this problem.
Extracting pitchmarks
The simplest way to extract the pitchmarks from the records is to use the command
./bin/make_pm_wave wav/*.wavwithout tuning any parameters.

Festival : make_pm
The 3 files uniph_0001.pm, uniph_0002.pm and uniph_0003.pm are saved in the folder pm. They have the following type of content :
EST_File Track
DataType ascii
NumFrames 271
NumChannels 0
NumAuxChannels 0
EqualSpace 0
BreaksPresent true
EST_Header_End
0.016750 1
0.023312 1
0.030125 1
0.037250 1
0.044625 1
.....
2.070750 1
2.081512 1
2.092275 1
2.103038 1
2.113800 1
2.124563 1Find Mel Frequency Cepstral Coefficients
In the next stage the Mel Frequency Cepstral Coefficients are defined synchronously with the pitch periods
./bin/make_mcep wav/*.wav
Festival : make_mcep
The 3 files uniph_0001.mcep, uniph_0002.mcep and uniph_0003.mcep are saved in the folder mcep. They have the following type of content :
EST_File Track
DataType binary
ByteOrder 01
NumFrames 271
NumChannels 12
EqualSpace 0
BreaksPresent true
CommentChar ;
Channel_0 melcep_1
Channel_1 melcep_2
Channel_2 melcep_3
Channel_3 melcep_4
Channel_4 melcep_5
Channel_5 melcep_6
Channel_6 melcep_7
Channel_7 melcep_8
Channel_8 melcep_9
Channel_9 melcep_10
Channel_10 melcep_11
Channel_11 melcep_N
EST_Header_End
........Building Synthesizer
Building the cluster unit selection synthesizer is the main part of the voice creation. It’s done with the command
festival -b festvox/build_clunits.scm '(build_clunits
"etc/uniphone.data")'
Festival : build synthesizer (click to enlarge)
The following files are created :
- folder festival/clunits : file mbarnig_en_marco.catalogue
- folder festival/feats : 41 files [phoneme-name].feats
- folder festival/trees : 41 files [phoneme-name].tree
- folder festival/trees : file mbarnig_en_marco.tree
The file mbarnig_en_marco.catalogue has the following type of content :
EST_File index
DataType ascii
NumEntries 46
IndexName mbarnig_en_marco
EST_Header_End
pau_5 uniph_0001 0.000000 0.007500 0.015000
ax_0 uniph_0001 0.015000 0.070000 0.125000
hh_0 uniph_0001 0.125000 0.180000 0.235000
ow_0 uniph_0001 0.235000 0.302500 0.370000
l_0 uniph_0001 0.370000 0.450000 0.530000
jh_0 uniph_0001 0.530000 0.590000 0.650000
oy_0 uniph_0001 0.650000 0.760000 0.870000
.....
er_0 uniph_0003 1.150000 1.205000 1.260000
m_0 uniph_0003 1.260000 1.320000 1.380000
ay_0 uniph_0003 1.380000 1.480000 1.580000
k_0 uniph_0003 1.580000 1.615000 1.650000
pau_0 uniph_0003 1.650000 1.650000 1.650000A xx.feats file has the following type of content :
0 w - r 0 0 0 0 l + z - f 0 0 0 0 a + 0.11000001 128.271 130.7258
126.721 1 coda coda onset 1 1 0 0 1 1 single oy + 0 2 d 3 + 0 0 0 0
content content contentA xx.tree file has the following type of content :
((((0 0)) 0))
;; Right cluster 0 (0%) mean ranking 2 mean distance 0The mbarnig_en_marco.tree file has the following type of content :
;; Autogenerated list of selection trees
;; db_dir "./"
;; db_dir "."
;; name mbarnig_en_marco
;; index_name mbarnig_en_marco
;; f0_join_weight 0
;; join_weights (0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5)
;; trees_dir "festival/trees/"
;; catalogue_dir "festival/clunits/"
;; coeffs_dir "mcep/"
;; coeffs_ext ".mcep"
;; clunit_name_feat lisp_mbarnig_en_marco::clunit_name
;; join_method windowed
;; continuity_weight 5
;; optimal_coupling 1
;; extend_selections 2
;; pm_coeffs_dir "mcep/"
;; pm_coeffs_ext ".mcep"
;; sig_dir "wav/"
;; sig_ext ".wav"
;; disttabs_dir "festival/disttabs/"
;; utts_dir "festival/utts/"
;; utts_ext ".utt"
;; dur_pen_weight 0
;; f0_pen_weight 0
;; get_stds_per_unit t
;; ac_left_context 0.8
;; ac_weights (0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5 0.5)
;; feats_dir "festival/feats/"
;; feats (occurid p.name p.ph_vc p.ph_ctype p.ph_vheight p.ph_vlng
p.ph_vfront p.ph_vrnd p.ph_cplace p.ph_cvox n.name n.ph_vc
n.ph_ctype n.ph_vheight n.ph_vlng n.ph_vfront n.ph_vrnd n.ph_cplace
n.ph_cvox segment_duration seg_pitch p.seg_pitch n.seg_pitch
R:SylStructure.parent.stress seg_onsetcoda n.seg_onsetcoda
p.seg_onsetcoda R:SylStructure.parent.accented pos_in_syl
syl_initial syl_final R:SylStructure.parent.lisp_cg_break
R:SylStructure.parent.R:Syllable.p.lisp_cg_break
R:SylStructure.parent.position_type pp.name pp.ph_vc pp.ph_ctype
pp.ph_vheight pp.ph_vlng pp.ph_vfront pp.ph_vrnd pp.ph_cplace
pp.ph_cvox n.lisp_is_pau p.lisp_is_pau
R:SylStructure.parent.parent.gpos
R:SylStructure.parent.parent.R:Word.p.gpos
R:SylStructure.parent.parent.R:Word.n.gpos)
;; wagon_field_desc "festival/clunits/all.desc"
;; wagon_progname "$ESTDIR/bin/wagon"
;; wagon_cluster_size 20
;; prune_reduce 0
;; cluster_prune_limit 40
;; files (uniph_0001 uniph_0002 uniph_0003)
(set! clunits_selection_trees '(
("k" ((((0 0)) 0)))
("ay" ((((0 0)) 0)))
("m" ((((0 0)) 0)))
("er" ((((0 0)) 0)))
("zh" ((((0 0)) 0)))
("ae" ((((0 0)) 0)))
("ch" ((((0 0)) 0)))
("eh" ((((0 0)) 0)))
....
("jh" ((((0 0)) 0)))
("l" ((((0 0)) 0)))
("ow" ((((0 0)) 0)))
("hh" ((((0 0)) 0)))
("ax" ((((0 0)) 0)))
("pau"
((((0 67.455) (1 100) (2 66.73) (3 100) (4 67.43) (5 100)) 83.6025)))
))Install new voice
In the last step I created the folder
Festival-TTS/festival/lib/voices/english/mbarnig_en_marco_clunits/and copied the following folders from the voice directory
Festival_TTS/festvox/mbarnig_en_marco/into this folder :
- festival
- festvox
- mcep
- wav
We can now check if the voice is recognized
festival> (voice.list)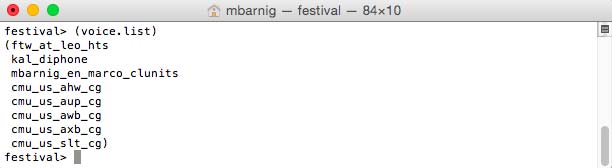
Festival : voice.list
load the new voice
festival> (voice_mbarnig_en_marco_clunits)and test the synthesis
festival> (SayText "Hello Marco, how are you?")
Festival : SayText
It works as expected.
The following folders in the voice folder Festival-TTS/festvox/mbarnig_en_marco remained empty :
- emu, including 2 empty subfolders lab_hlb and pm_hlb
- f0
- group
- lar
- lpc
- phr
- pm_lab
- recording
- scratch, including 2 empty subfolders lab and wav
- syl
- versions
- wrd