
Speech Corpora
A speech corpus is a database of speech audio files and text transcriptions. In Speech technology, speech corpora are used to create voices for TTS (Text-to Speech) and to create acoustic models for speech recognition.
For a speech database to serve as the basis for constructing a synthetic voice, the recordings should be of studio quality and free of noise. Noise includes not just external sounds, but also unwanted breaths and clicks. The recorded utterances need to be phonetically balanced and the prosody of speech needs to be controlled so that the synthetic voice’s style of delivery is both consistent and appropriate. To satisfy these requirements it’s not sufficient to collect speech records, but you have to design a speech corpus for synthesis. The basic idea is to take a very large amount of text (millions of words) and automatically find nice utterances that match the following criteria :
- phonetically and prosodically balanced
- targeted toward an intended domain
- easy to say by a speaker without mistakes
- short enough for a speaker to be willing to say it
Some historic speech database projects are :
- 1986 : TIDIGITS
- 1986 : TIMIT
- 1992 : SWITCHBOARD
- 1994 : Boston University’s FM Radio News Corpus
- 1997 : CALLHOME
- 1998 : BABEL
- 2000 : AURORA
If the use of a designed speech corpus should be unrestricted, we need to start from a source of written material that does not impose any copyright. In the past one such source was the Gutenberg Project (PG), a volunteer effort to digitize and archive cultural works. It was founded in 1971 by Michael S. Hart and is the oldest digital library. Most of the items in its collection are the full texts of public domain books. As most of these texts are at least 70 years old, we face the issue of language drift. Languages changed considerable over the last century and the related texts are often archaic. Today, dumps of Wikipedia are usually preferred as free sources to design a speech corpus for TTS.
In the next chapters some recent speech corpora projects are presented.
CMU-ARCTIC US Voice Databases
The CMU_ARCTIC databases were constructed in 2003 at the Language Technologies Institute at Carnegie Mellon University as phonetically balanced, US English single speaker databases, designed for unit selection speech synthesis research. The databases consist of around 1150 utterances carefully selected from out-of-copyright texts from Project Gutenberg. The databases include US English male and female speakers as well as other accented speakers. The distributions include 16KHz waveform and simultaneous EGG signals. Full phonetically labelling was performed by the CMU Sphinx using the FestVox based labelling scripts. No hand correction has been made. Runnable Festival Voices are included with the database distributions.
The following corpora are available :
- US male (bdl) – 593 a files, 539 b files
- US male (rms) – 593 a files, 539 b files
- US Canadian male (jmk) – 593 a files, 539 b files
- US Scottish male (awb) – 597 a files, 541 b files
- US Indian male (ksp) – 593 a files, 539 b files
- US female (slt) – 593 a files, 539 b files
- US female (clb) – 593 a files, 539 b files
The typical structure of a CMU_ARCTIC database is shown below :
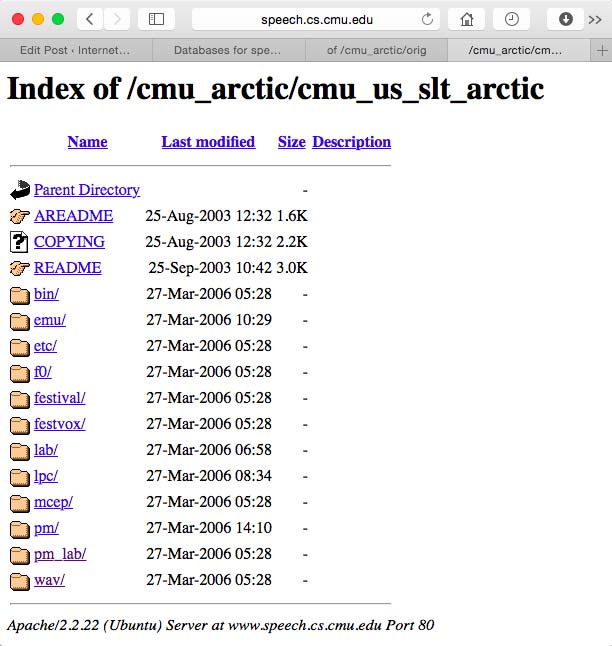
cmu_arctic database structure
The main folders are :
- etc/ : list of prompts; one file txt.done.data included with all utterances
- wav/ : recorded audio data (XXXX.wav); one file per utterance
- lab/ : labelled text files (XXXX.lab); one file per utterance
ENST and UMPC French Speech Corpora
French speech corpora have been designed for synthesis in 2013 at Télécom ParisTech (ENST : École nationale supérieure des télécommunications) and by the Institut des Systèmes Intelligents et de Robotique (ISIR), Université Pierre et Marie Curie (UPMC).
The audio data is provided in the losslessly compressed FLAC format. The speaker were recorded at a 44.1 kHz or 48 kHz sampling rate, 16 bits per sample, in mono. No filters of any sort have been applied to the raw data. Phonetic labels, automatically obtained using forced alignment using the eHMM tool from Festvox 2.1, are provided as Xwaves .lab file with the fields ENDTIME (in seconds), NUMBER (no significance) and LABEL (variant of the SAMPA phonetic alphabet.
The following corpora are available :
- ENST Camille : recorded by Camille Dianoux, a female native speaker of French
- UPMC Pierre : recorded by Pierre Chauvin, a male native speaker of French
- UPMC Jessica : recorded by Jessica Durand, a female native speaker of French
The GitHub repository of a typical ENST or UPMC corpus is shown below :
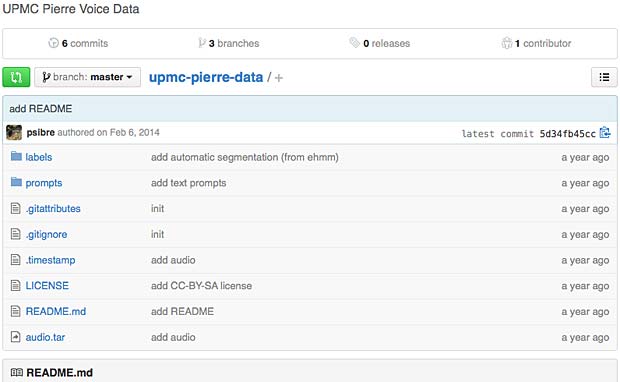
upmc speech corpus repository
The main folders are :
- prompts/ : one text_xxxx.txt file per utterance (1.000 files)
- labels/ : one text_xxxx.lab file per utterance (1.000 files)
- audio.tar archive with one text_xxxx.flac file per utterance (1.000 files)
PAVOQUE German Corpus of Expressive Speech
A single speaker, multi-style corpus of German speech, with a large neutral subset, and subsets acting out four different expressive speaking styles, has been designed for synthesis in 2013 in the context of the SEMAINE and IDEAS4GAMES projects. PAVOQUE is the abbreviation for PArametrisation of prosody and VOice QUality for concatenative speech synthesis in view of Emotion expression. The speaker is Stefan Röttig, a male native speaker of German, trained as a professional actor and baritone opera singer.
The audio data is provided in the losslessly compressed FLAC format. The speaker was recorded at a 44.1 kHz sampling rate, 24 bits per sample, in mono. No filters of any sort have been applied to this raw data, but low-pass filtering at 50 Hz is recommended. The manually corrected phonetic labels are provided as Xwaves .lab files with the fields ENDTIME (in seconds), NUMBER (no significance) and LABEL (variant of the SAMPA phonetic alphabet.
The following corpora are available :
- Neutral
- Obadiah ist von Natur aus niedergeschlagen und blickt pessimistisch in die Zukunft.
- Poker ist ein ausgekochter Pokerspieler. Er ist cool, ihn bringt nichts aus der Ruhe.
- Poppy ist fröhlich, optimistisch und sieht das Gute in allen Dingen!
- Spike ist aggressiv und geht keinem Streit aus dem Weg!
The GitHub repository of the PAVOQUE corpus is shown below :
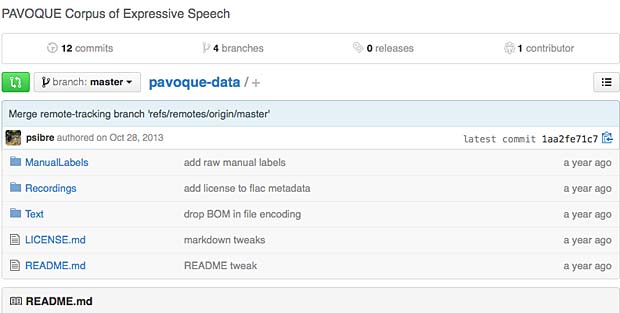
pavoque speech corpus repository
The main folders are :
- Text/ one axxx.txt file per utterance (total 4.242 files)
- ManualLabels/Neutral/ one Xxxxx.lab file per utterance (total 3.126 files : 1.591 a-files, 1.423 e-files, 112 prudence-files)
- ManualLabels/Obadia/ one Xxxxx.lab file per utterance (total 556 files : 124 obadia-files, 400-m files, 32 poker_d-files)
- ManualLabels/Poker/ one Xxxxx.lab file per utterance (total 682 files : 282 poker_n-files, 400 m-files)
- ManualLabels/Poppy/ one Xxxxx.lab file per utterance (total 584 files : 159 poppy-files, 400 m-files, 25 poker__f-files)
- ManualLabels/Spike/ one Xxxxx.lab file per utterance (total 601 files : 151 spike-files, 400 m-files, 50 poker_a-files)
- Recordings/Neutral.tar archive one Xxxx.wav file per utterance (3.126 files)
- Recordings/Obadia.tar archive one Xxxx.wav file per utterance (556 files)
- Recordings/Poker.tar archive one Xxxx.wav file per utterance (682 files)
- Recordings/Poppy.tar archive one Xxxx.wav file per utterance (584 files)
- Recordings//Spike.tar archive one Xxxx.wav file per utterance (601 files)
Praat
The label files (abcd.lab) can be opened in Praat using the command
{Praat Object}
Open > Read from special tier file > Read IntervalTier from Xwaves ..Links :
- CMU ARCTIC databases for speech synthesis, by John Kominek and Alan W Black
- CMU ARCTIC prompt list with 1132 utterances