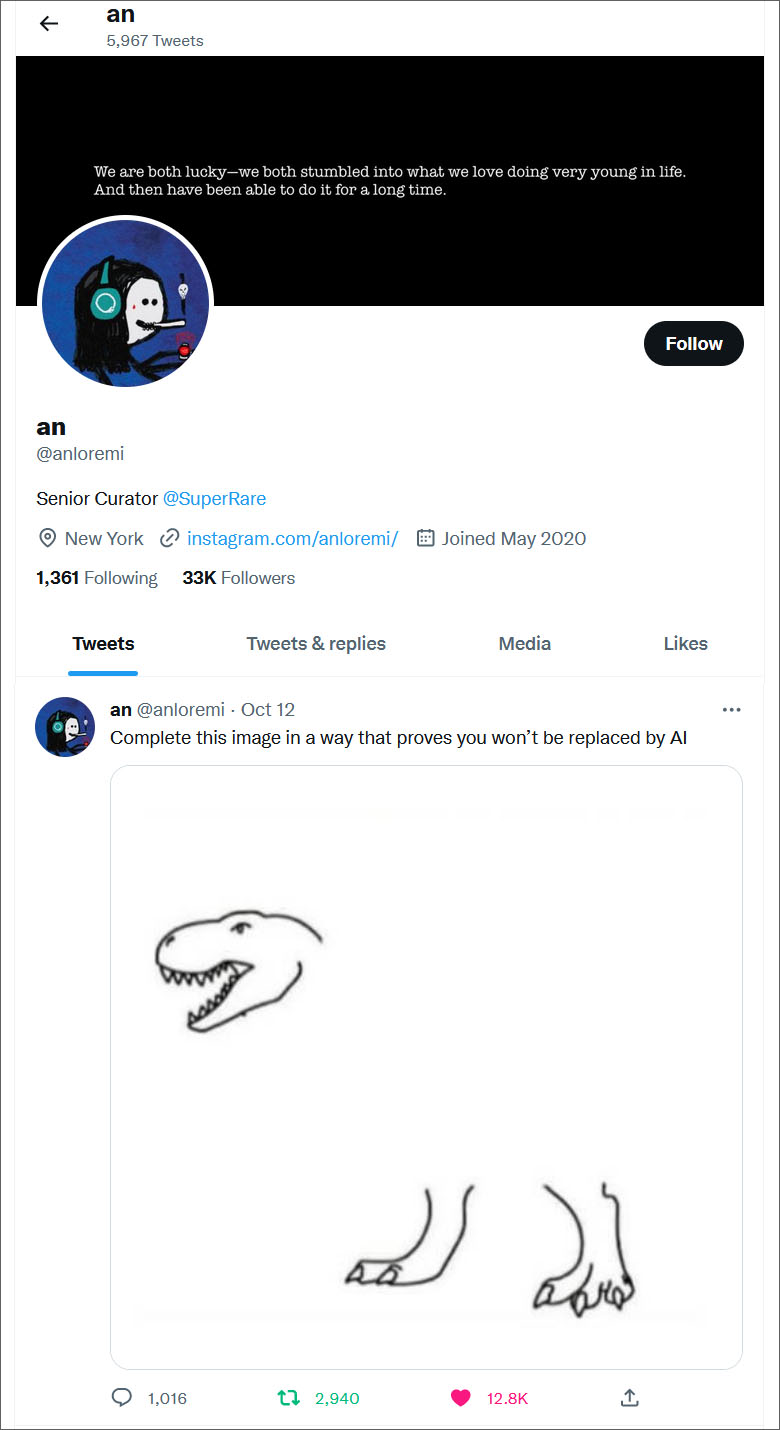
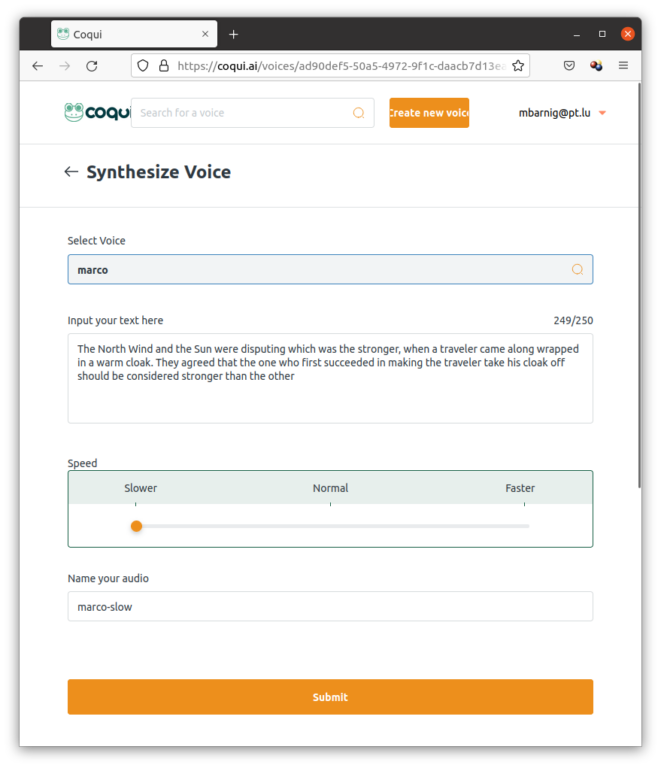
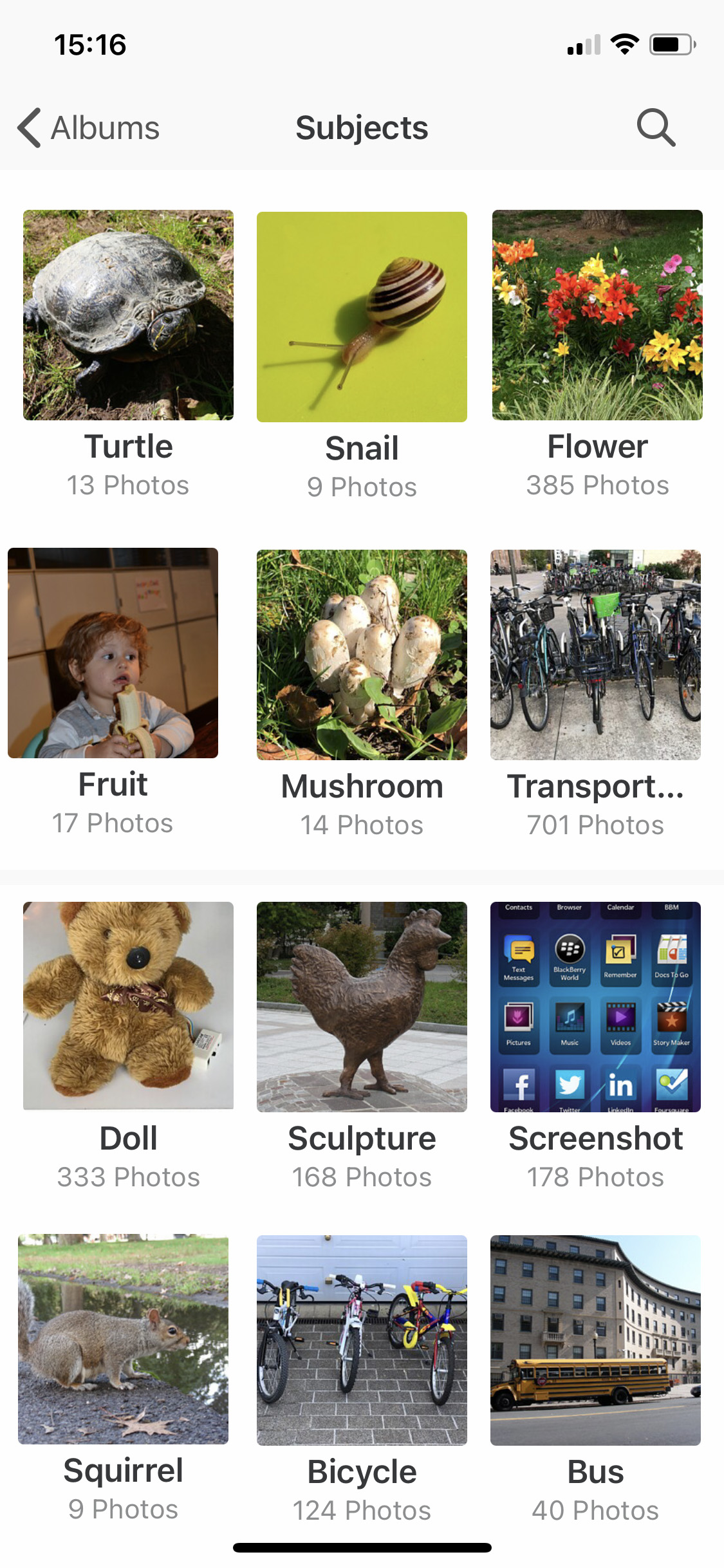
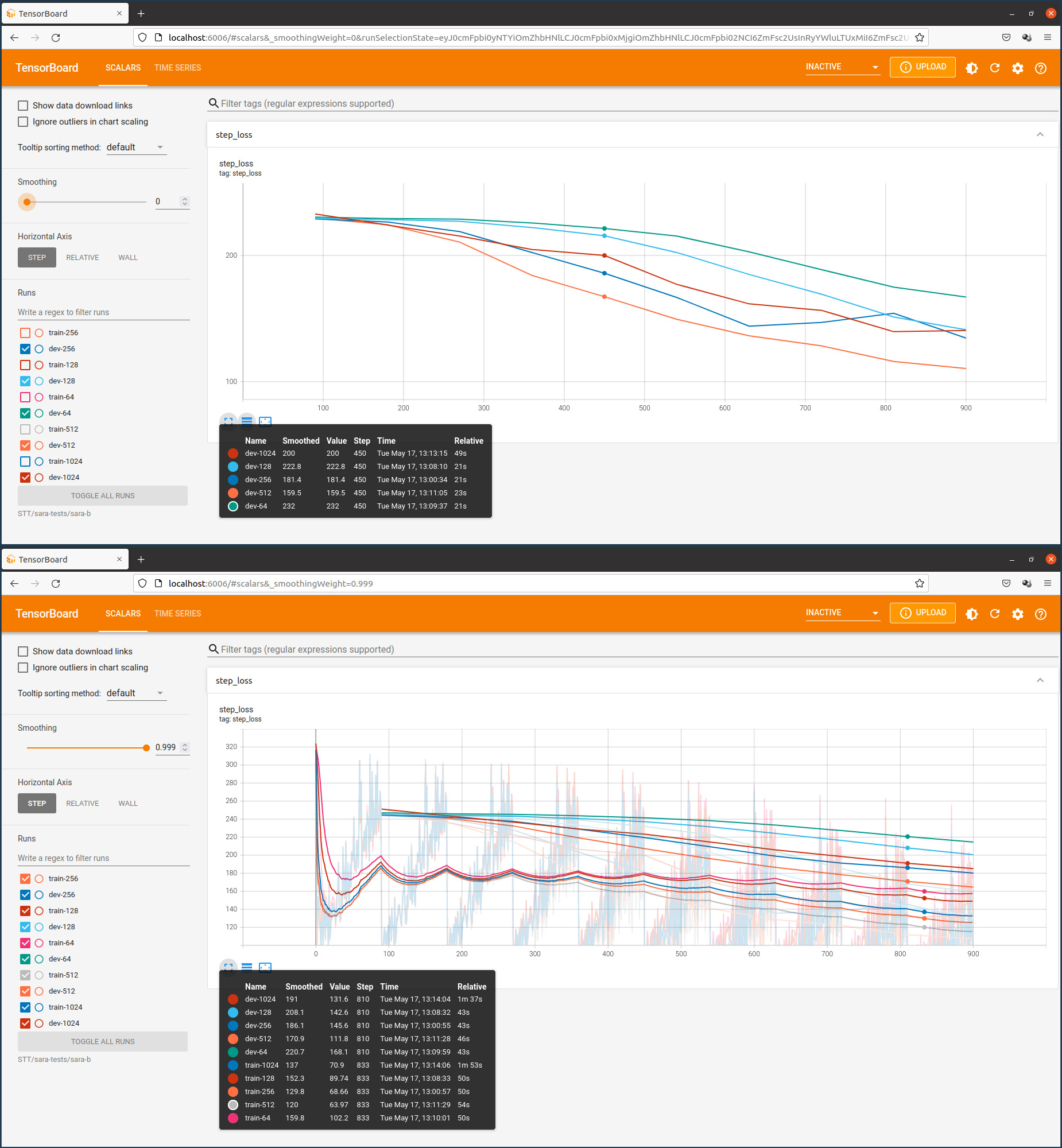
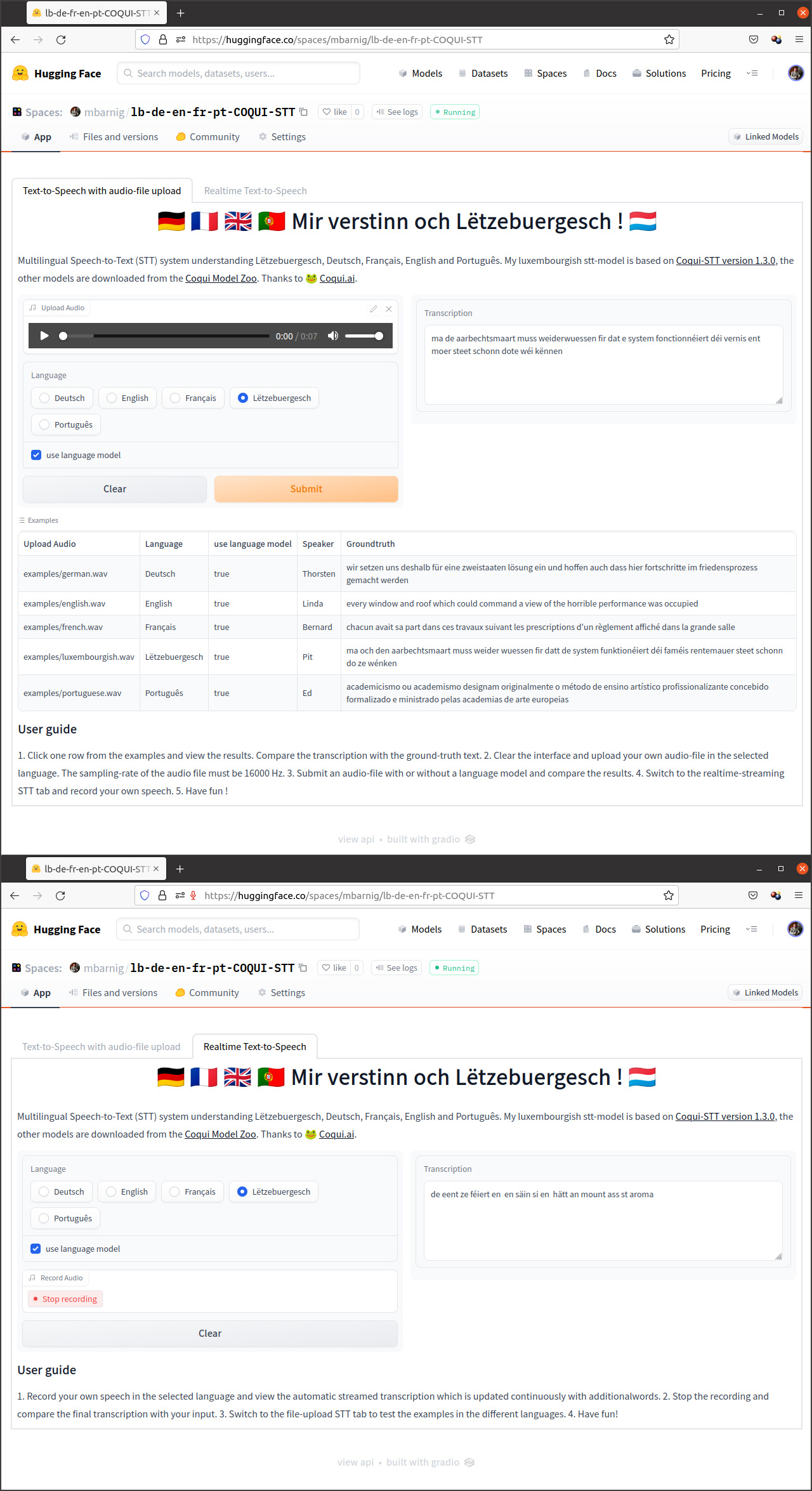
Le 12 octobre 2022 An Rong a publié le tweet suivant sur Twitter pour inviter le public à compléter un dessin d’une tête et de pieds d’un dinosaure de manière à prouver que l’image résultante n’a pas été générée par une intelligence artificielle (AI).
Le Tweet a connu un grand succès avec 12.800 Likes, presque 3000 retweets et plus que 1000 réponses, incluant de nombreuses créations d’images. Le tweet a été lancé dans le contexte des modèles neuronaux d’art génératif, basés sur la technologie Stable Diffusion et supportant la fonction inPainting.
An Rong à obtenu en 2019 son diplôme d’études muséales à l’Université de New York. Son travail de fin d’études portait sur l’art et les blockchains. Après ses études elle a joint la start-up SuperRare où elle est actuellement directeur des arts et des programmes culturels. Elle considère que pouvoir travailler chaque jour avec du CryptoArt et des NFTs et de faire la connaissance de jeunes artistes brillants dans le domaine de l’art digital est un poste de rêve.
An Rong est rédactrice du magazine SuperRare et du bulletin d’information correspondant. En mai 2022 elle a présenté à SoHo, New York, la première galerie éphémère brique et mortier de la plateforme NFT SupeRare. Elle était également curateur de l’exposition Invisible Cities en 2021, ensemble avec Elisabeth Johs, et de l’exposition Un-Realism en 2022, ensemble avec Fabio Giampietro et Skygolpe.
Invisible Cities : Emiris – the forgotten city, by Mari.K (MadMaraca), 2021, Unique Non- Fungible Token
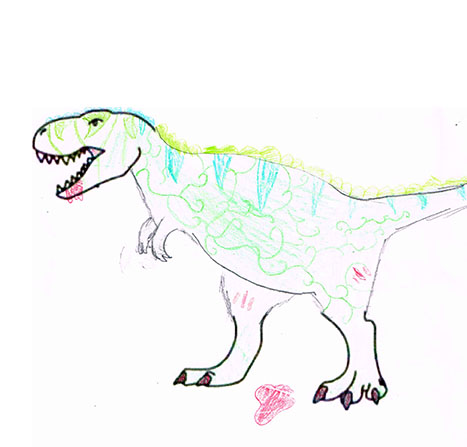
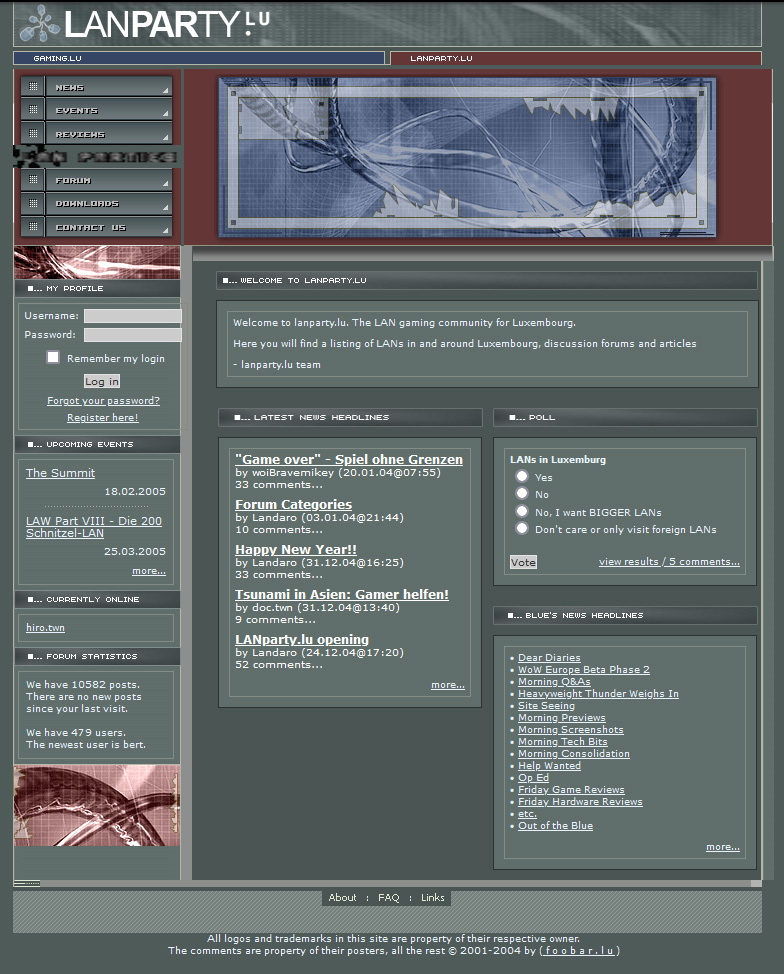
En ce qui concerne l’image du dinosaure à compléter, mes petits-enfants ont ajouté les contours du corps et coloré le dessin. Le dinosaure du milieu vient de dévorer une proie, les taches rouges sont du sang qui a coulé.
TessaCapucineBoma & Capucine
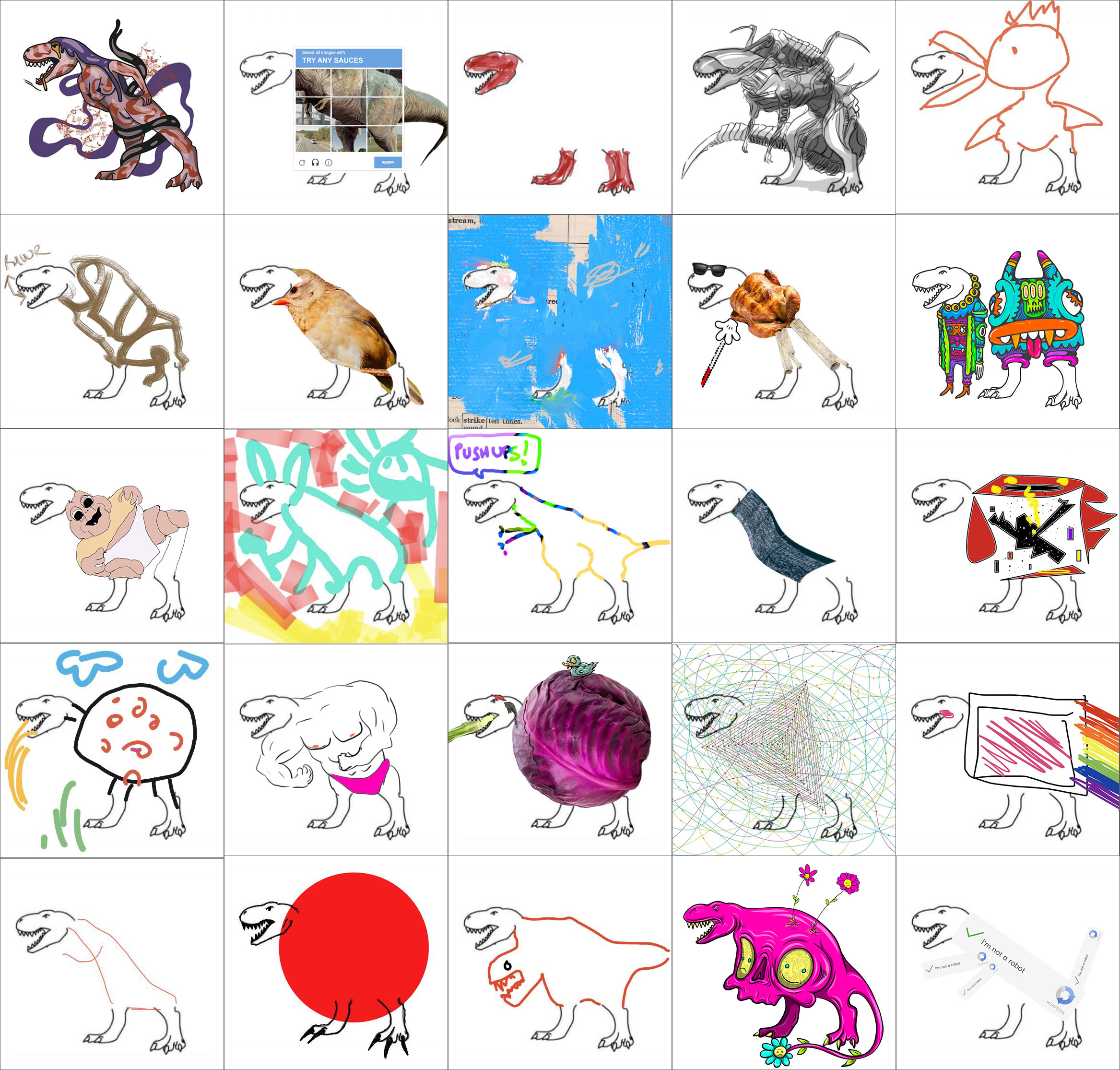
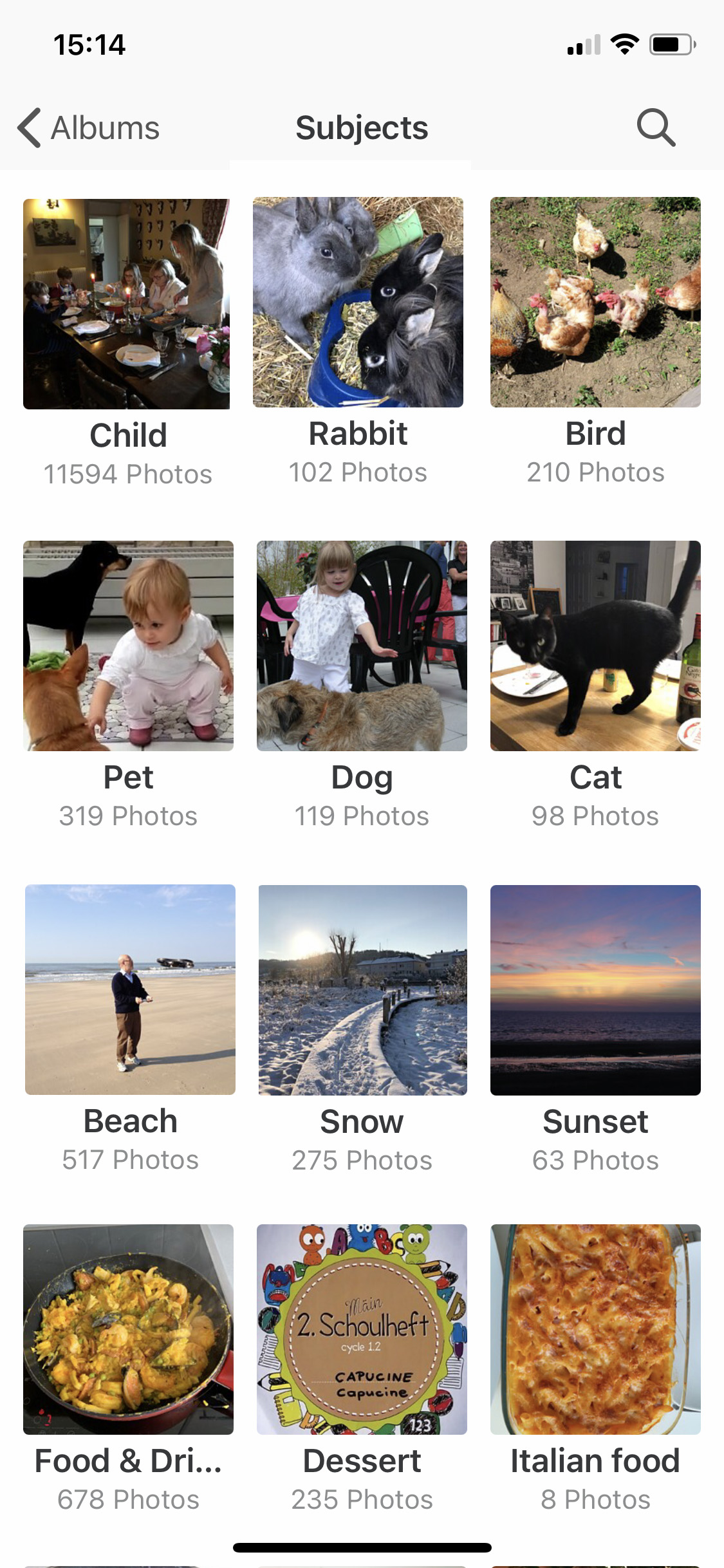
Les images complétées par des adultes, suite à l’invitation de An Rong, sont plus astucieuses. J’ai assemblé ci-après un collage avec 30 dessins en noir et blanc. On peut retrouver les noms des artistes afférents sur Twitter dans les réponses au tweet original.
Assemblage de 30 images n/b d’un dinosaure dessinées par des humains (cliquez pour agrandir)
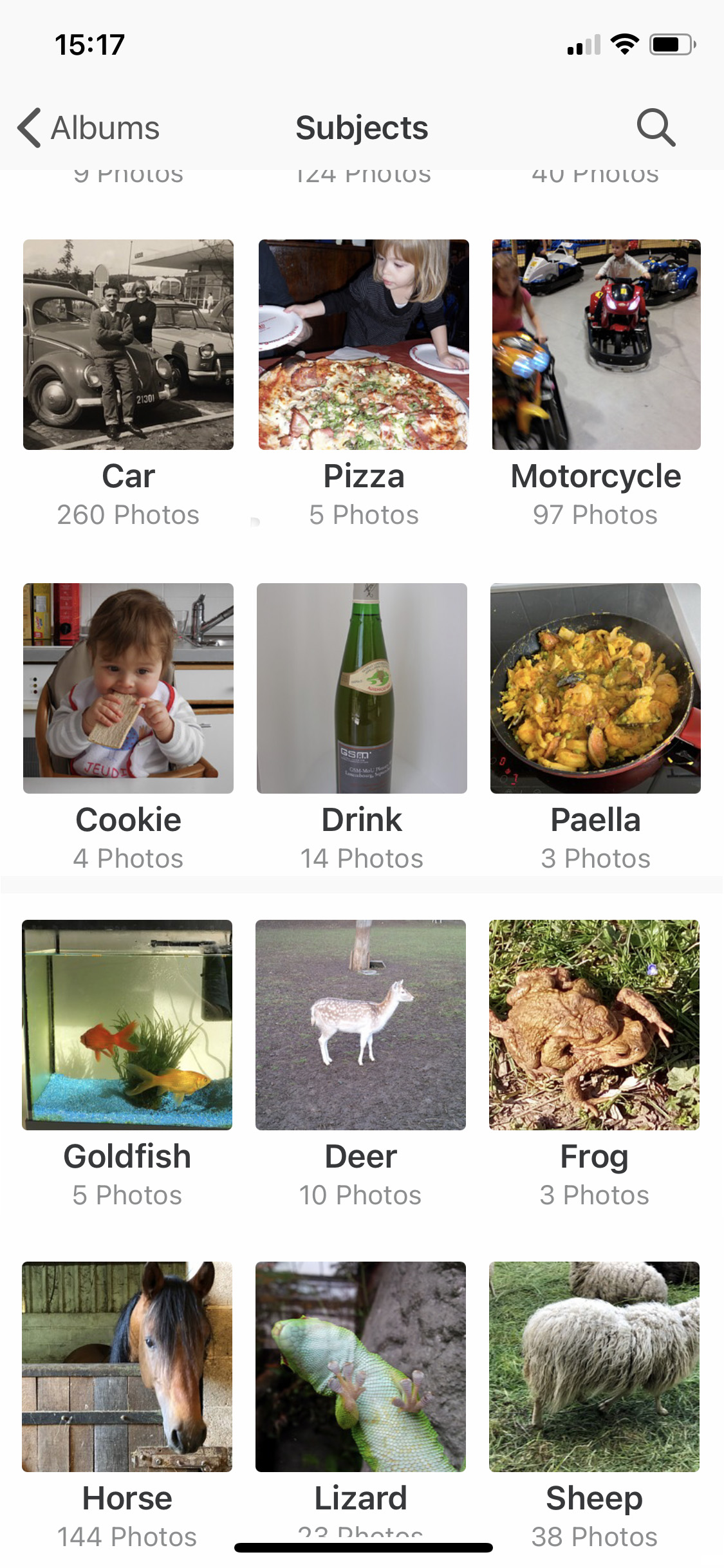
L’affichage qui suit montre 25 dessins complétés supplémentaires, mais cette fois en couleur. Comme expliqué ci-avant, le lecteur intéressé trouve les noms des artistes sur Twitter.
Assemblage de 25 images colorées d’un dinosaure dessinées par des humains (cliquez pour agrandir)
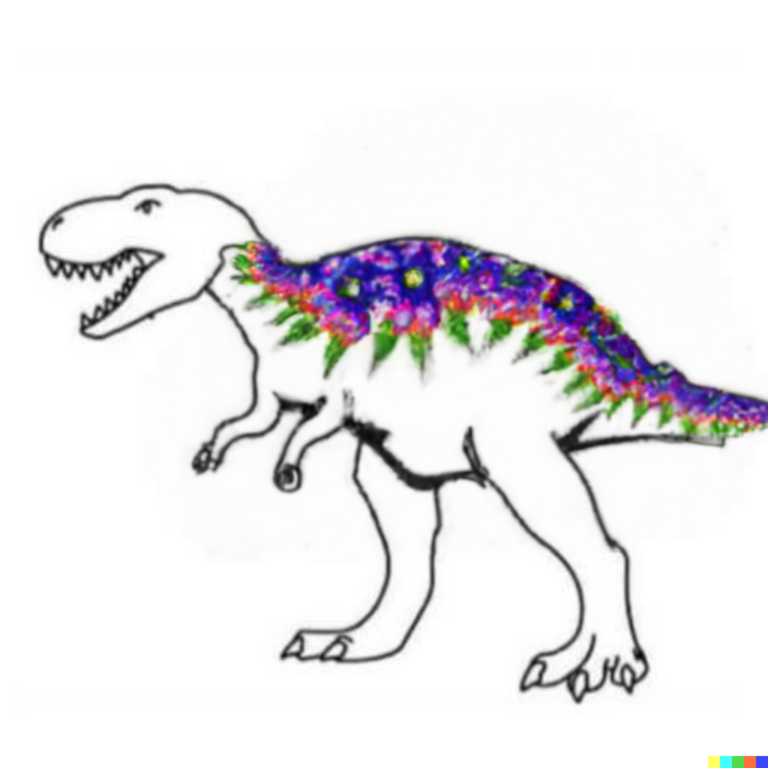
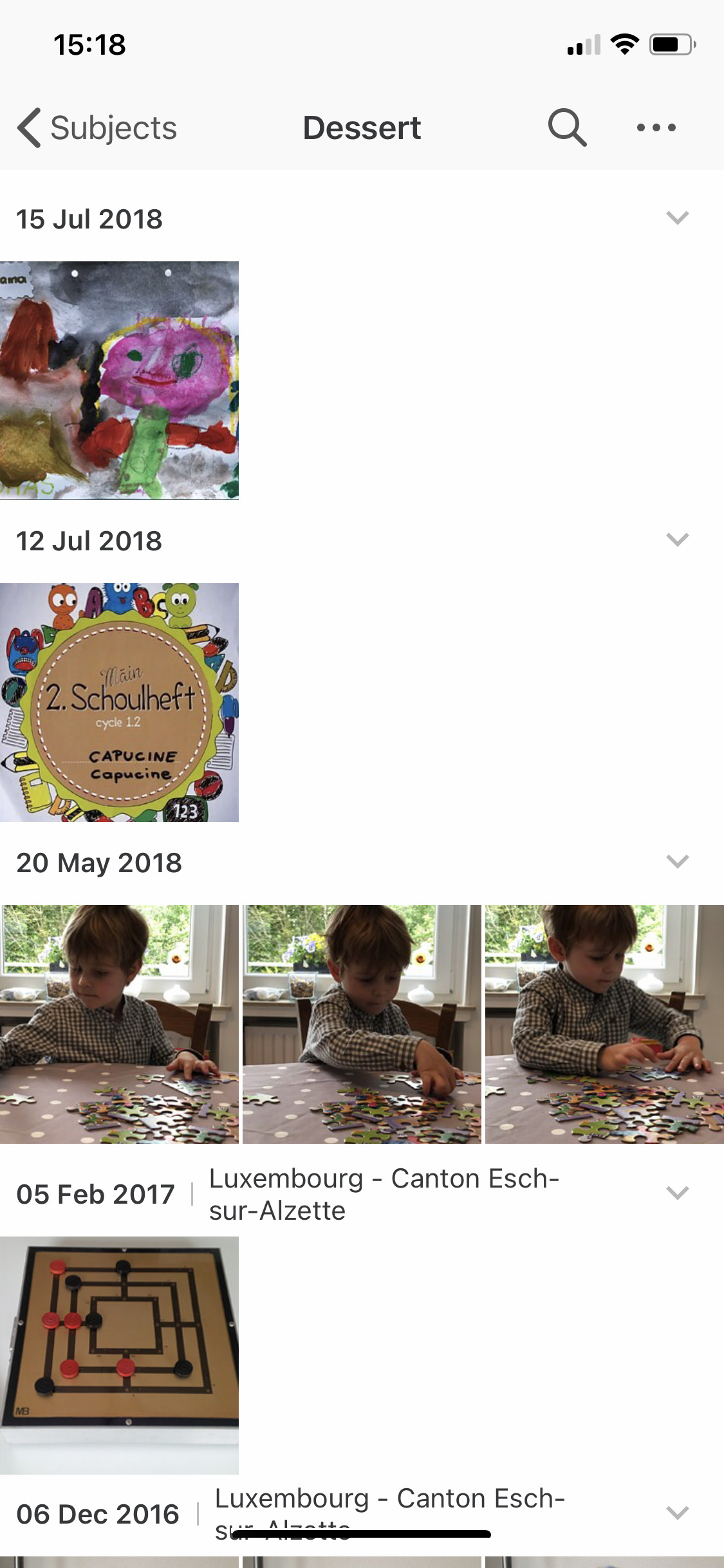
Et pour ceux qui se demandent quels types de dessins sont générés par un modèle AI, j’ai assemblé ci-après quelques images de dinosaures complétées par DALLE*2, avec la description entrée “dinosaur with flowers” :
Images complétées avec le modèle DALLE*2 de OpenAi
Depuis plusieurs années on lit ou entend de plus en plus souvent un terme mystérieux: NFT (non-fungible token) ou JNF (jeton non fongible). Il s’agit d’une donnée cryptée qui représente un objet numérique auquel est rattachée une identité numérique, c.à.d. un propriétaire. Cette donnée est stockée et authentifiée grâce à un protocole de chaîne de blocs (blockchain), c.à.d. un registre numérique public et décentralisé. Un NFT est payé avec des unités de crypto-monnaie qui sont gérées, ensemble avec les NFTs, dans un portefeuille numérique.
Avant de présenter en détail ces différentes technologies, je vais les introduire moyennant deux cas concrets, l’achat et la vente d’une oeuvre d’art numérique sur Internet. Les NFTs ne sont pas limités au domaine de l’art, mais sont utilisés surtout dans différents secteurs professionnels. Comme une oeuvre d’art digitale est quelque chose de tangible, elle se prête bien pour expliquer le concept à l’homme de la rue qui sera confronté probablement de plus en plus souvent avec des NFTs, suite à l’explosion récente des générateurs d’art neuronaux basés sur l’intelligence artificielle (images, vidéos, littérature, musique, …).
2. The Happyness Amplified
NFT “The Happyness Amplified” de l’artiste Raphaël Laventure
L’image animée GIF ci-dessus est une oeuvre d’art numérique créée par l’artiste français Raphaël Laventure. L’oeuvre a été frappée le 17 mai 2022 par l’agence marketing luxembourgeoise The Dots, fondée en 2021 par Kamel Amroune. L’oeuvre est mis en vente sur la place de marché objkt.com au prix de 115 ꜩ (Tezos), ce qui correspond à environ 200 €. Elle fait partie d’une collection de 4 NFTs et porte le nom de The Happiness Amplified. En janvier 2022, lors de la présentation de l’événement Metavers Month, l’agence The Dots avait annoncé la création d’un NFT en collaboration avec l’artiste Raphaël Laventure. Quelques mois plus tard, The Dots a confirmé dans son service phare Techsense que le NFT était prêt.
La frappe NFT (minting) est le processus de conversion d’un fichier numérique en un objet de collection crypto. Après la frappe il est impossible de supprimer, d’éditer ou de modifier l’identité numérique ou le fichier afférent stocké sur la chaîne de blocs correspondante.
L’acheteur d’une NFT comme The Happiness Amplified peut la mettre dans un cadre numérique installé dans son salon ou l’afficher sur un grand écran attaché au mur de son salon. Tout comme chacun peut s’accrocher une copie, une affiche ou une impression d’une célèbre peinture dans son salon, il n’existe qu’un seul original dont l’authenticité est certifiée en général par le musée qui détient cette oeuvre. Dans le cas d’une NFT ce n’est pas différent. Un surfeur sur Internet ayant quelques notions techniques peut cloner ou copier l’objet numérique, mais il ne peut pas falsifier l’identité numérique contenue dans la chaîne de blocs qui authentifie l’origine et le propriétaire de l’objet.
Dans une première phase j’ai été tenté d’acquérir une édition de cette oeuvre pour démarrer mes expériences NFT, mais j’ai hésité ensuite pour engager une somme relativement élevée dans une aventure que je ne maîtrise pas encore et qui porte certains risques. Dans un article écrit pour Delano et traduit pour Paperjam, l’artiste luxembourgeois de renom Sumo a confessé qu’il a mis environ un an pour comprendre qu’un NFT n’est pas seulement un jpeg. Dans la suite il est devenu un grand fan des jetons non fongibles.
Un deuxième témoignage, celui de Jil Haberstig, consultant, artiste et fondatrice du Lux NFT Club, va dans le même sens. Dans un entretien publié sur le site web siliconluxembourg en janvier 2022, intitulé Selling NFTs Is Almost A Full-Time Job, Jil Haberstig a déclaré
It requires a lot of technical knowhow. It took me almost a year to have a sense of what I’m doing (laughs) and I still feel that every day. It’s evolving very fast and before you can enter the NFT market or get involved, first of all you have to understand the crypto market, otherwise you’re not able to sell or buy NFTs. If you’re not in the crypto market NFT is just a word.
J’ai donc compris que acheter et vendre ses premiers NFTs n’est pas l’affaire d’une journée et qu’il faut aller en douceur.
N.B. Le 2 novembre 2022 Meta a annoncé qu’elle va bientôt supporter la vente de NFTs à partir de Instagram, ce qui peut faciliter les démarches dans l’avenir. Meta avait démarré en mai 2022 un projet pilote afférent aux Etats-Unis avec quelque artistes sélectionnés.
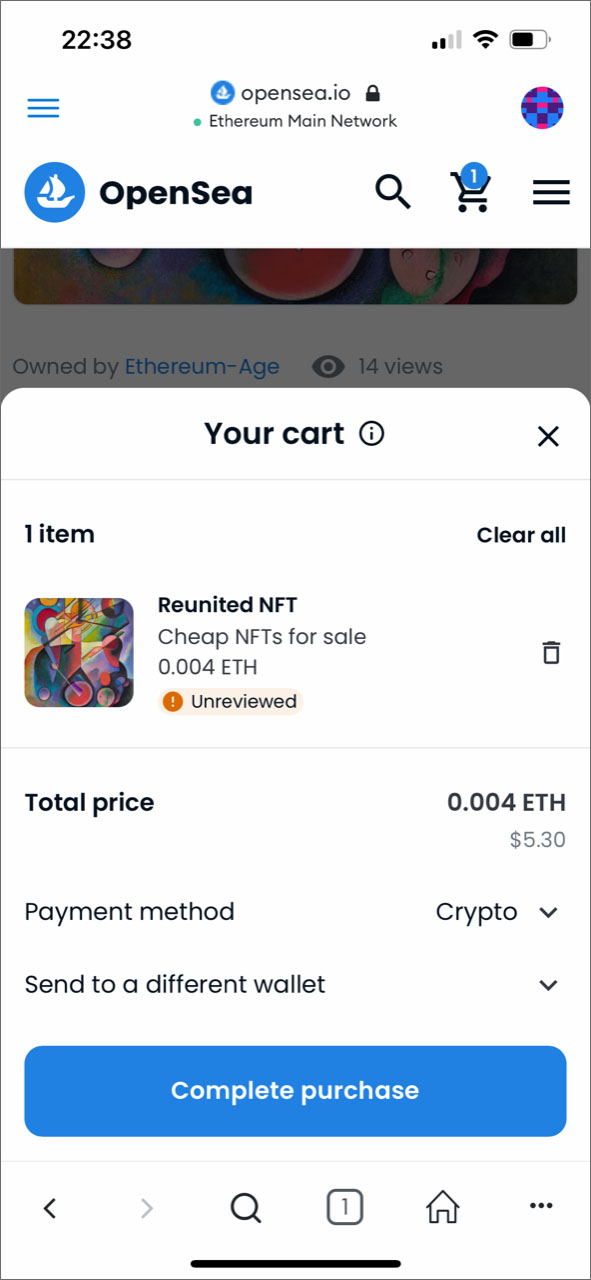
3. Reunited NFT
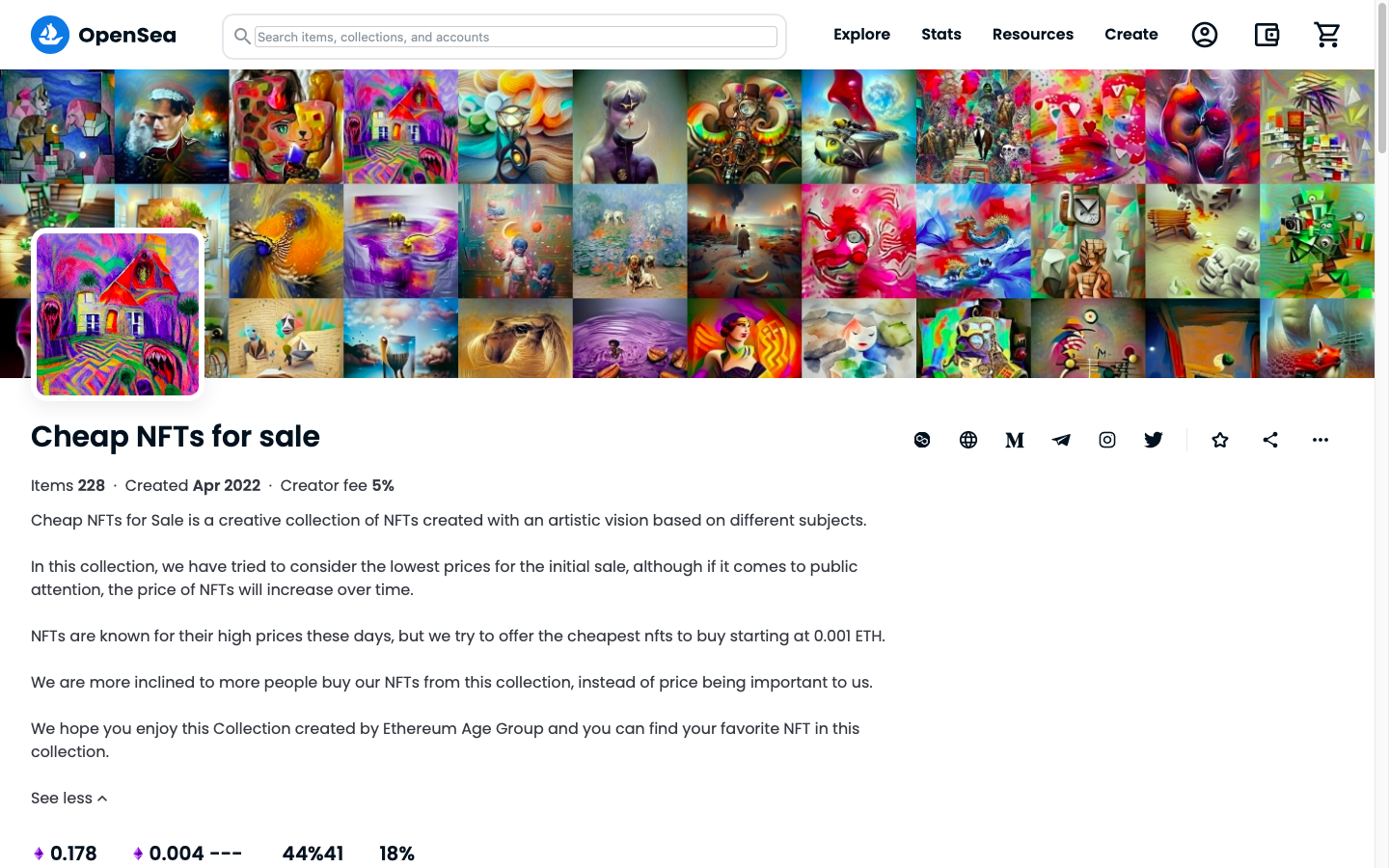
Suite à quelques recherches sur Google, j’ai appris que Opensea est la place de marché NFT la plus connue et qu’elle couvre surtout le domaine de l’art. J’ai commencé à explorer cette plateforme et j’ai rapidement trouvé une collection au nom de Cheap NFTs for Sale.
Collection “Cheap NFTs for sale” sur la place de marché Opensea
Les artistes qui créent des oeuvres numériques pour cette collection affirment que leur objectif n’est pas de gagner de l’argent, mais de faciliter l’accès à ces nouvelles technologies à l’homme de la rue. C’est parfait, c’est ce qu’il me faut. Il faut dire que la qualité des images numériques de cette collection n’est pas fameuse. Comme mon souhait n’était pas d’acquérir un chef-d’oeuvre, mais de me familiariser avec la technique NFT, j’ai choisi un objet au nom de Reunited NFT au prix affiché de 0.004 ETH sur la chaîne de blocs Polygon. Ce prix correspondait à environ 6 €. Voilà cette image:
Oeuvre d’art numérique “United NFT”
4. Guide NFT pour les débutants
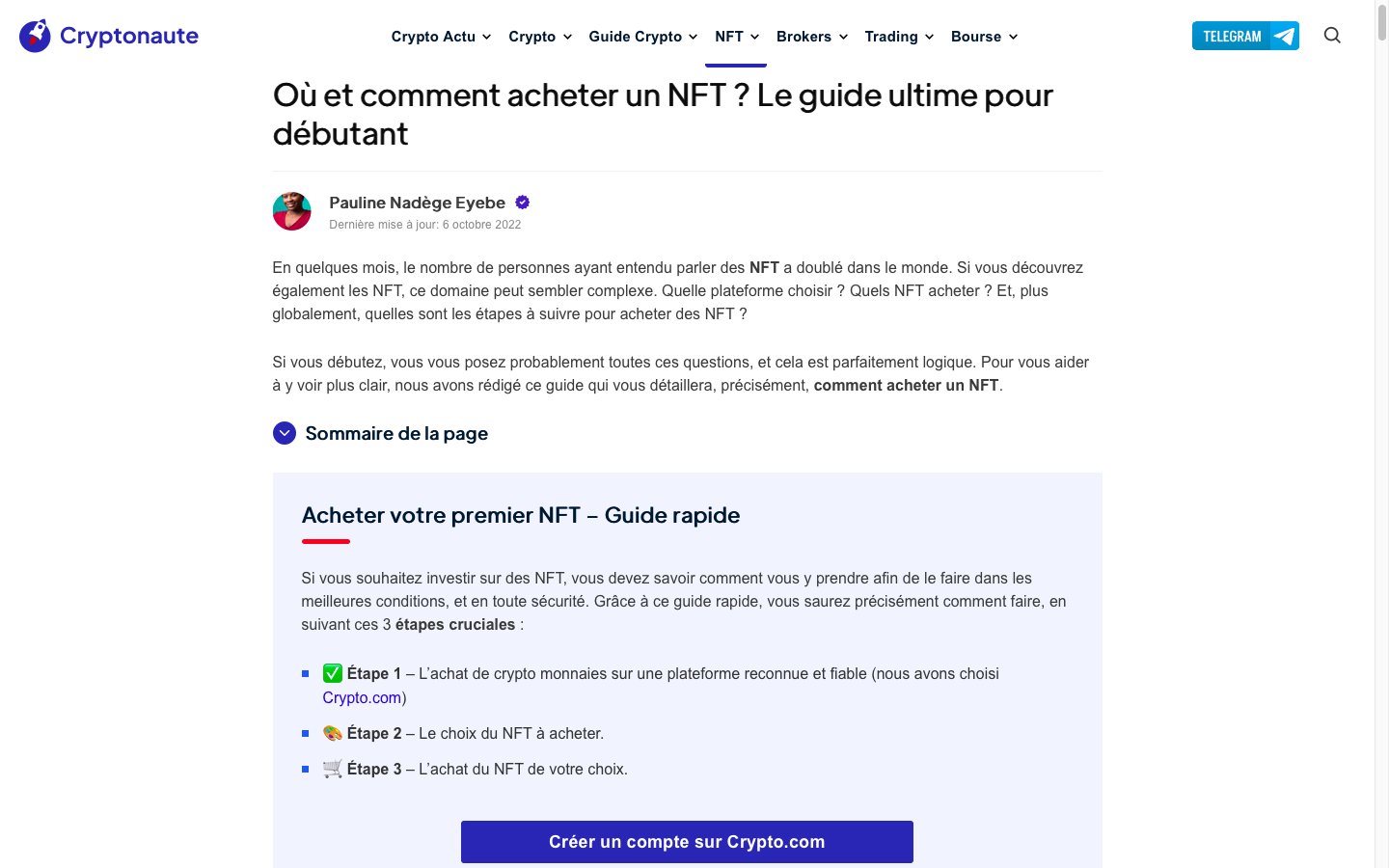
Pour progresser avec l’achat de mon NFT sélectionné, j’ai cherché des guides et tutoriels afférents sur le web moyennant Google Search. L’article Où et comment acheter un NFT ? Le guide ultime pour débutant, publié le 6 octobre 2022 sur la page web cryptonaute.fr, me paraissait sérieux. J’ai appris que la première étape consiste à acheter de la crypto-monnaie sur une plateforme reconnue et fiable. On me proposait de cliquer sur un bouton vert pour créer un compte sur Crypto.com, ce que j’ai fait.
guide cryptonaute cliquez pouragrandirredirection compte crypto.com cliquez pour agrandir
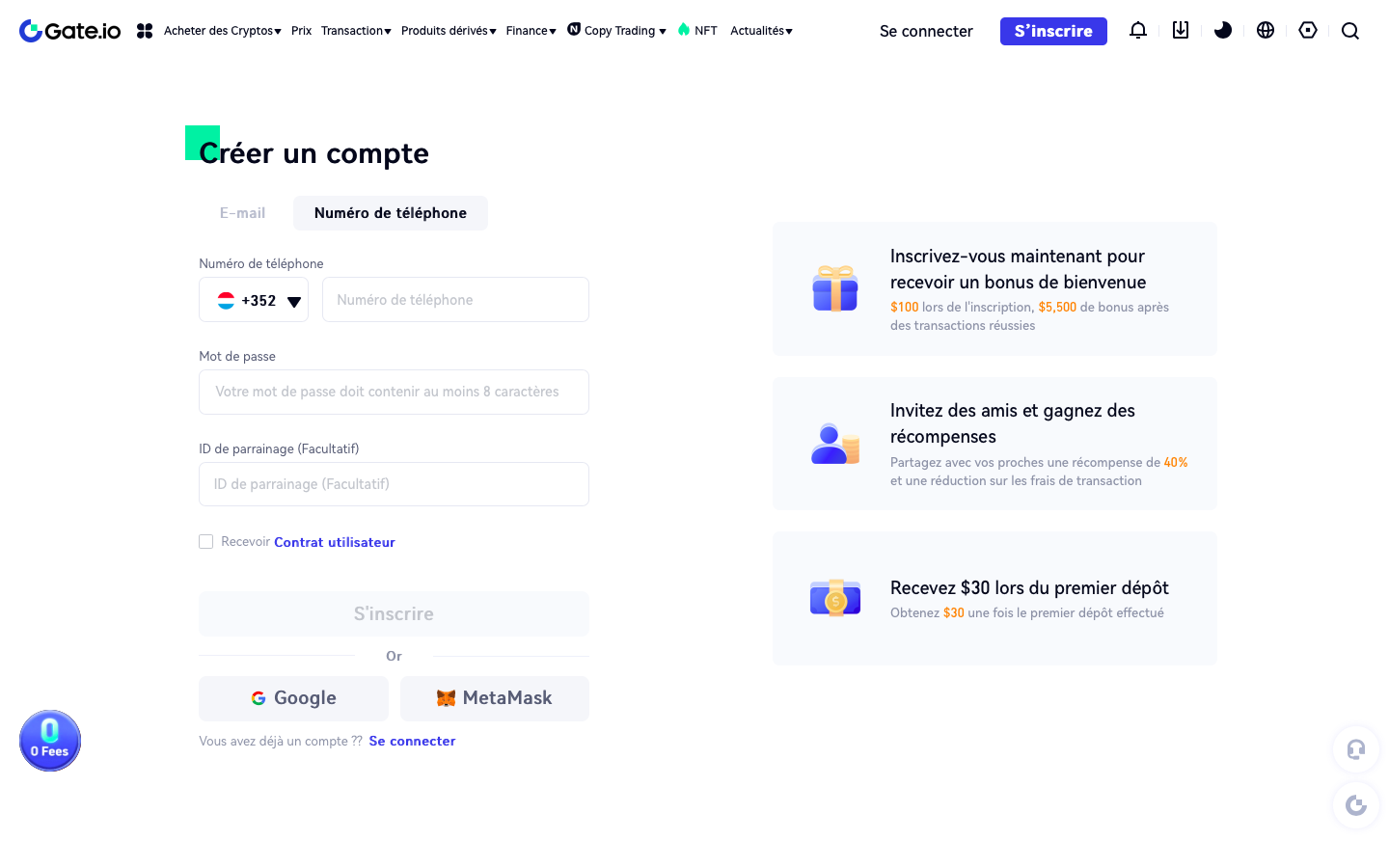
J’étais étonné de voir qu’après plusieurs redirections je me suis retrouvé sur une page gate.io pour ouvrir ce compte (voir copies-écran ci-dessus). J’étais en outre intrigué au sujet des propositions de m’offrir un cadeau de bienvenu de 100 € lors de l’inscription et un bonus de 5.500 € lors de transactions réussies. Je me suis méfié de ne pas voir des prix ou des conditions générales sur cette page. Probablement c’est ca le monde des NFTs ? Avec une certaine prudence j’ai entré le soir du dimanche 9 octobre 2022 mon numéro mobile et les autres données requises sur la page web de création du compte. A la fin j’étais informé que le minimum d’achat de crypto-monnaie était de 250 €, ce qui m’a amené à interrompre le processus d’inscription. J’ai décidé de m’informer davantage sur le monde NFT avant de continuer.
Le lendemain tôt le matin, une dame m’appelait sur mon mobile pour m’offrir son support à changer ma vie. Elle avait vu que j’avais abandonné la soirée précédente le processus de création d’un compte sur crypto.com. Elle essayait par tous les moyens de me convaincre de compléter mon inscription et ses conseils se ont transformés rapidement dans un vrai harcèlement. J’étais obligé d’interrompre l’appel par la force. Décidément le monde des NFT est particulier !
5. Plateforme Coinbase
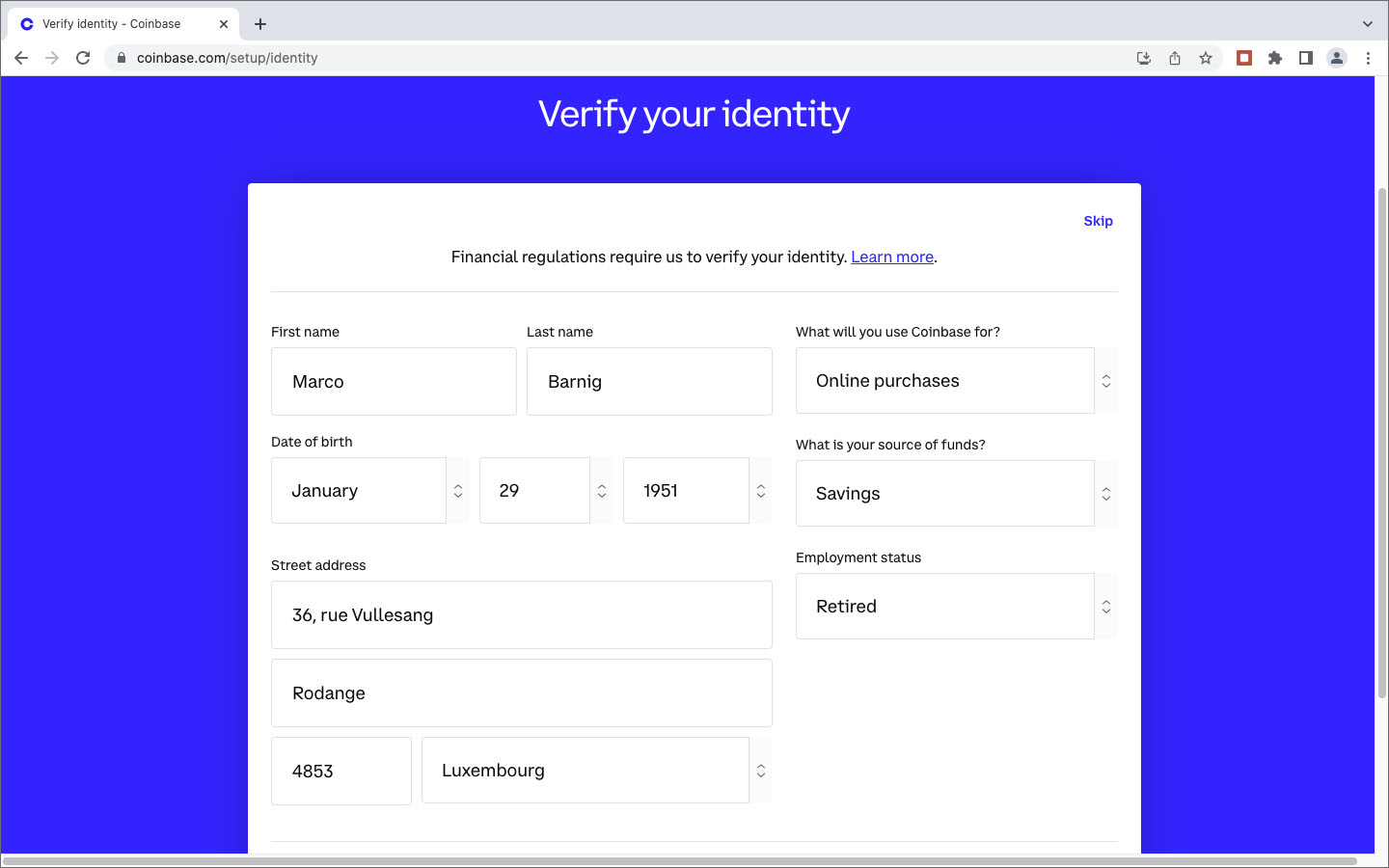
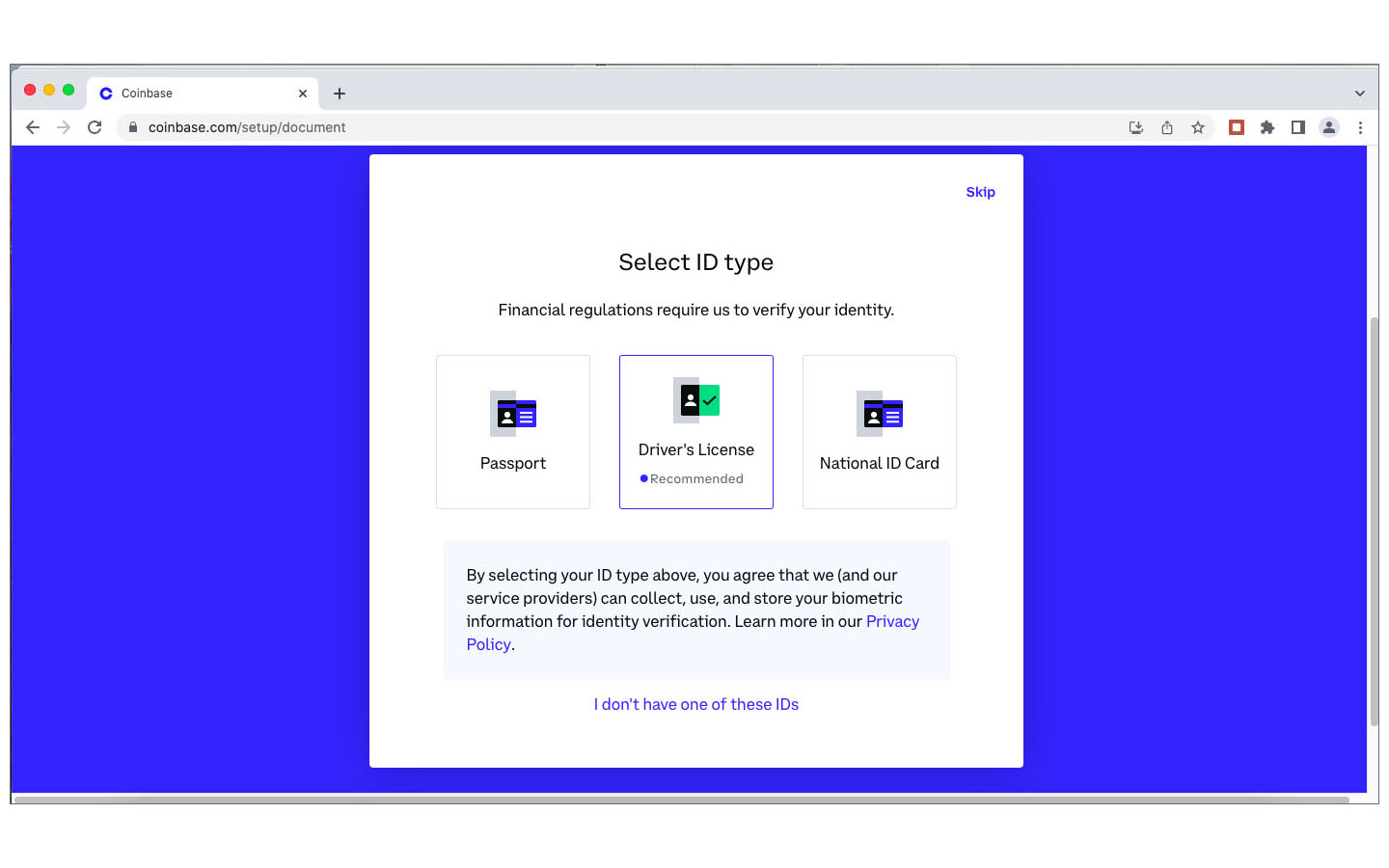
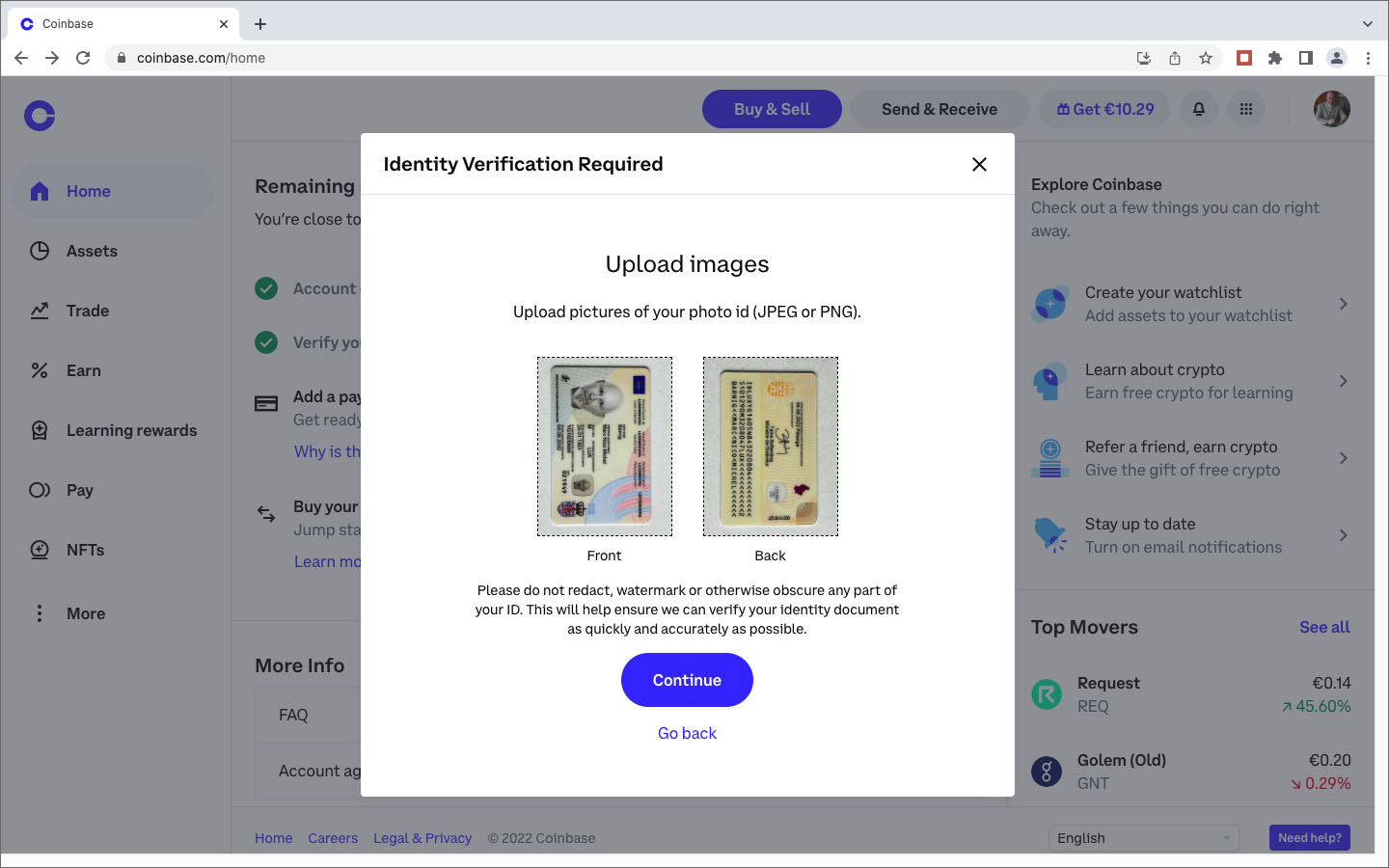
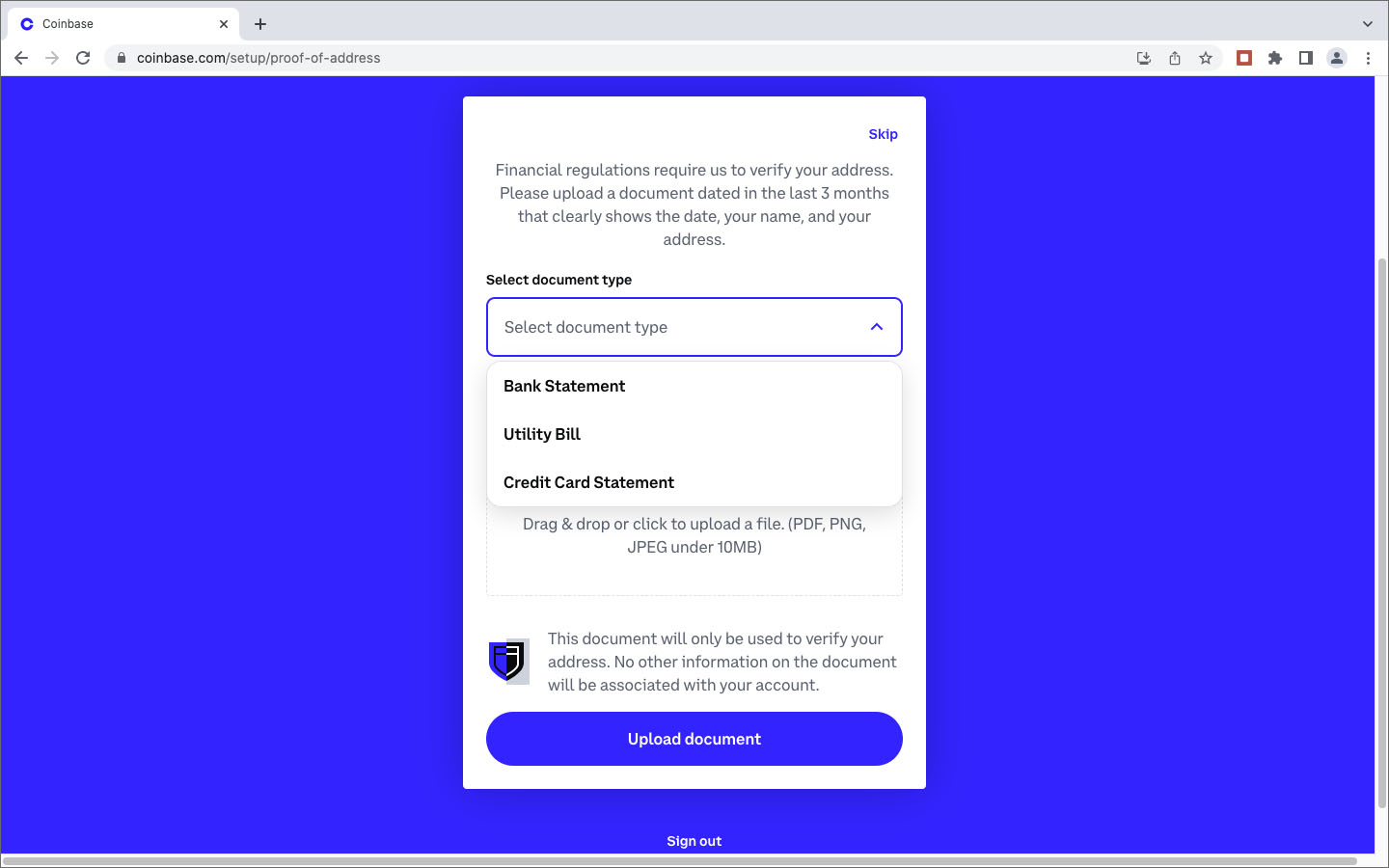
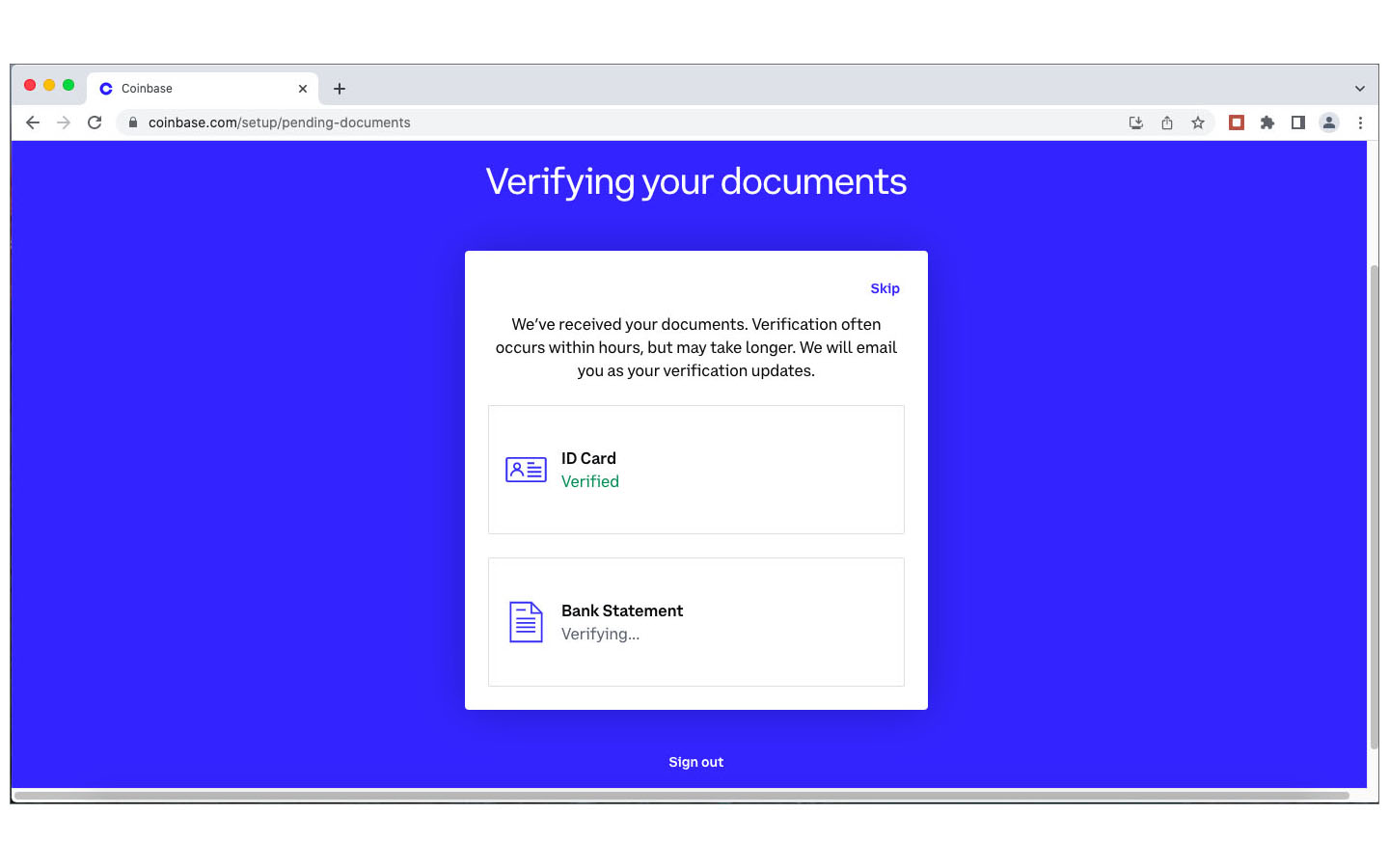
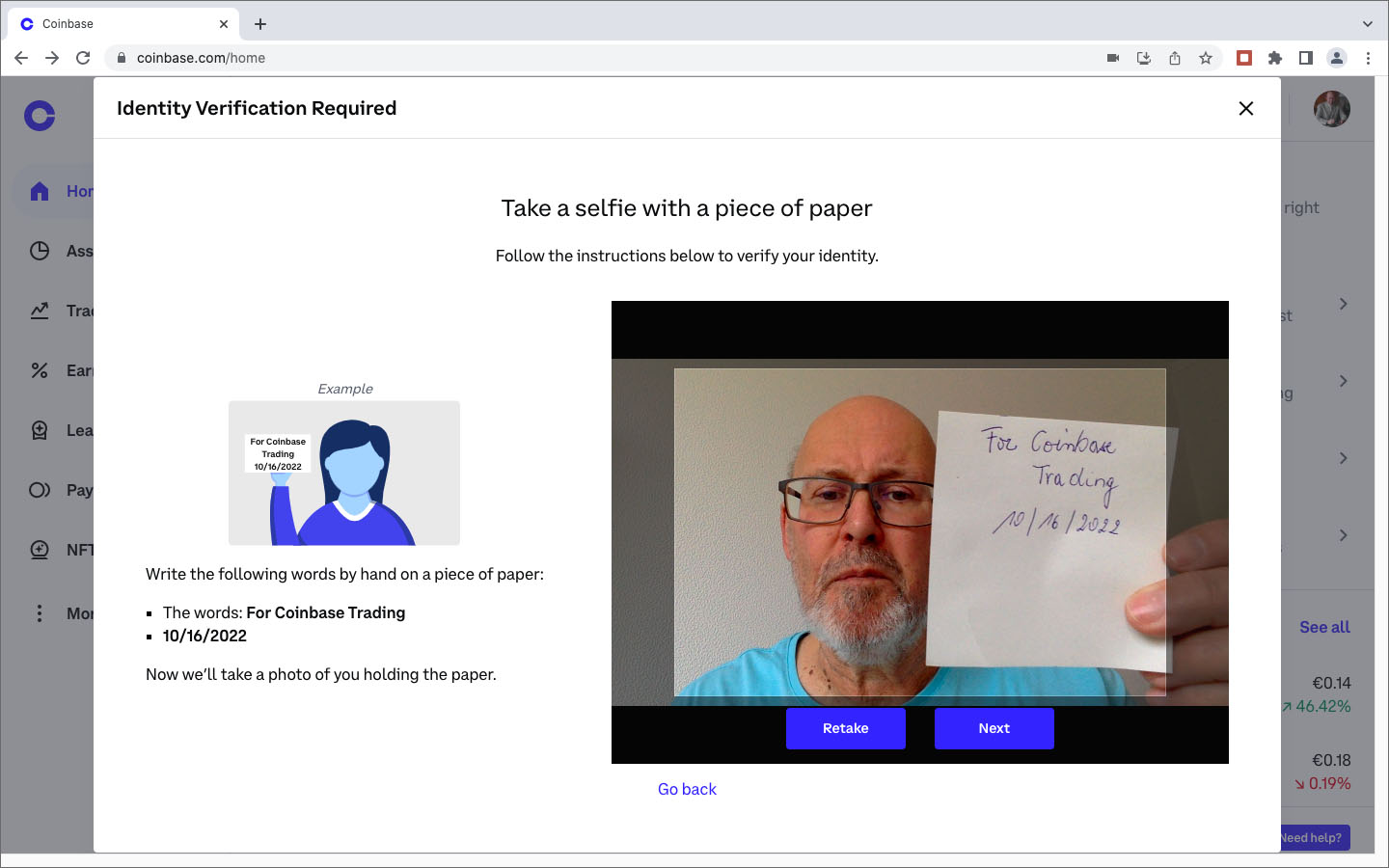
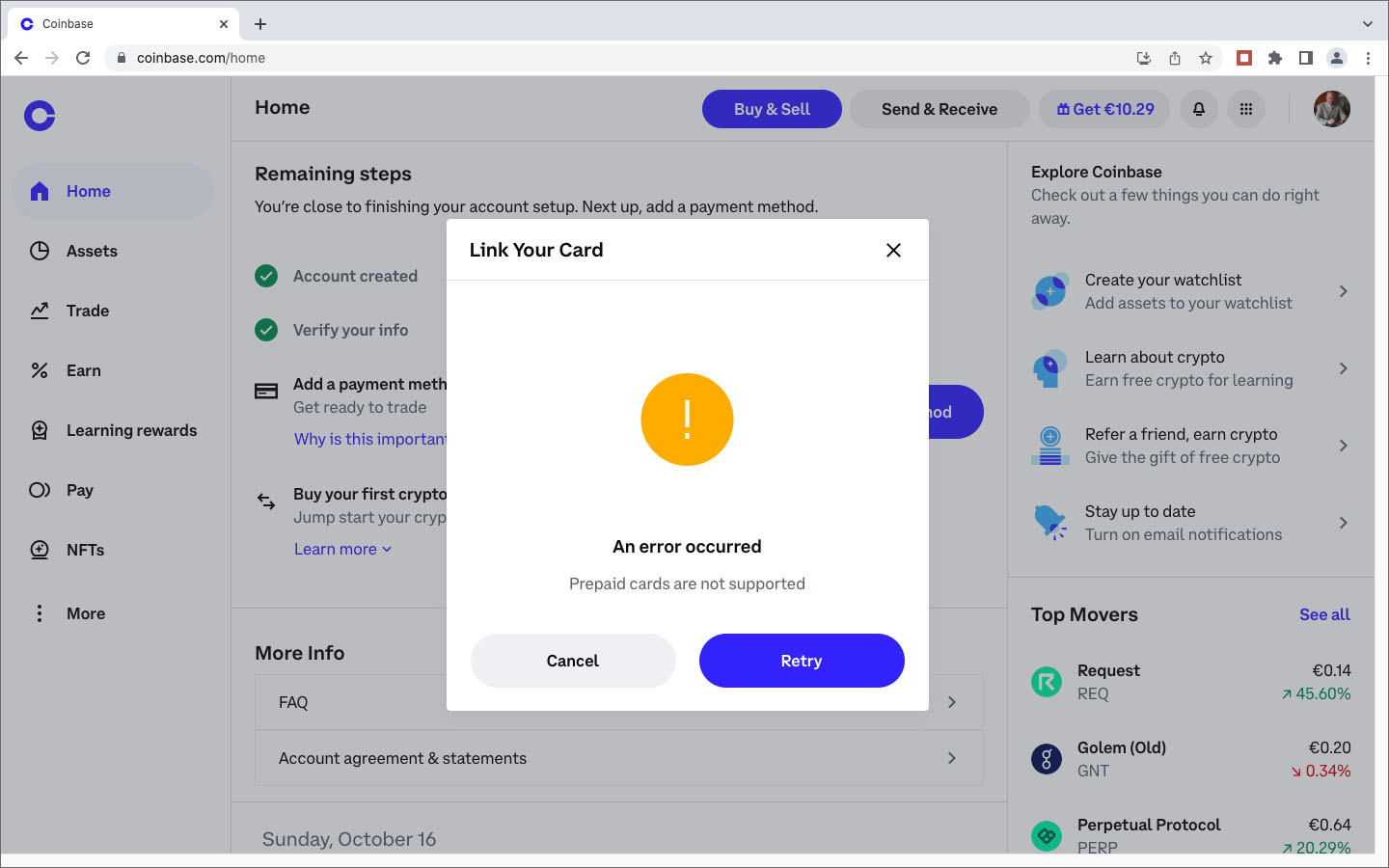
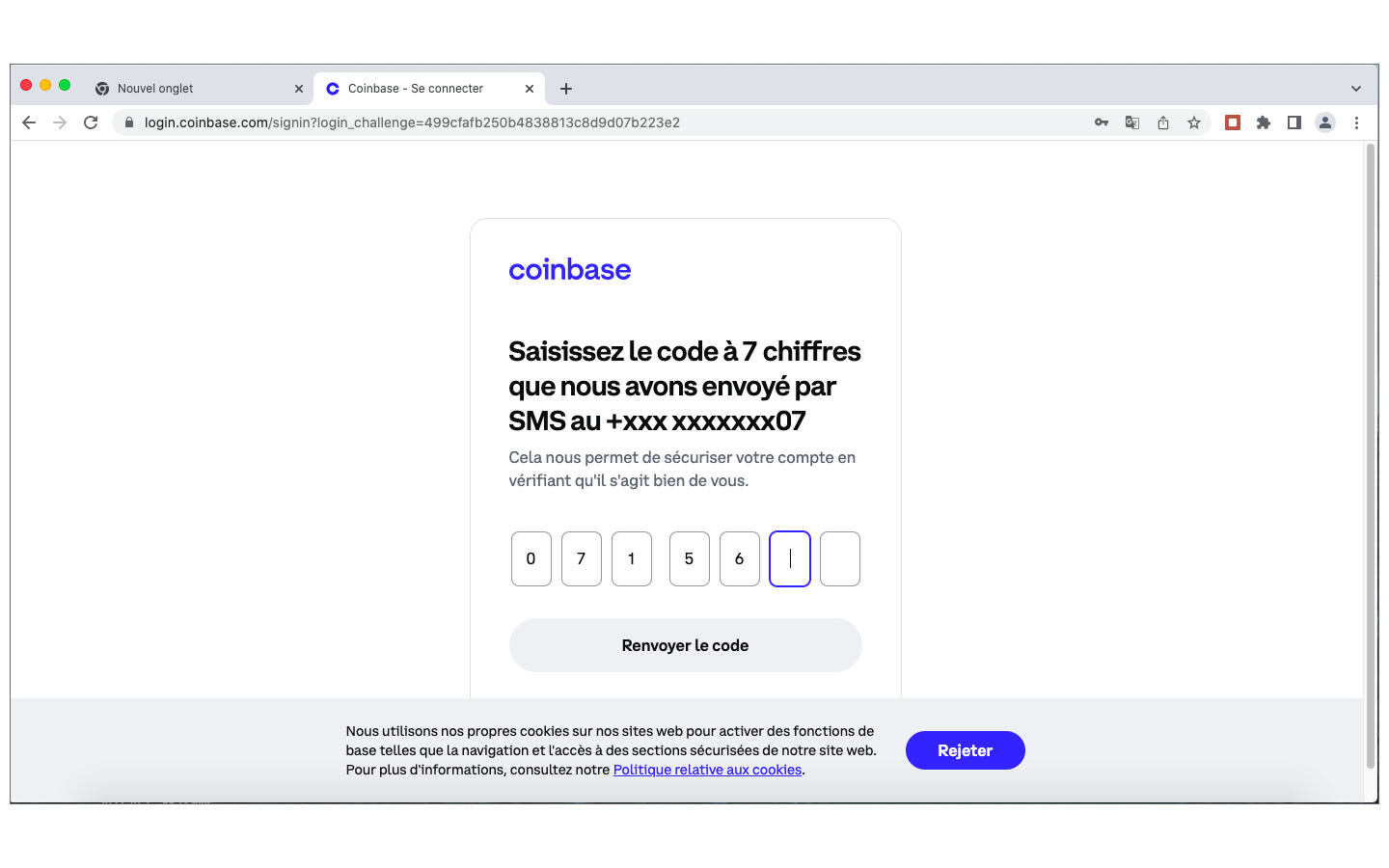
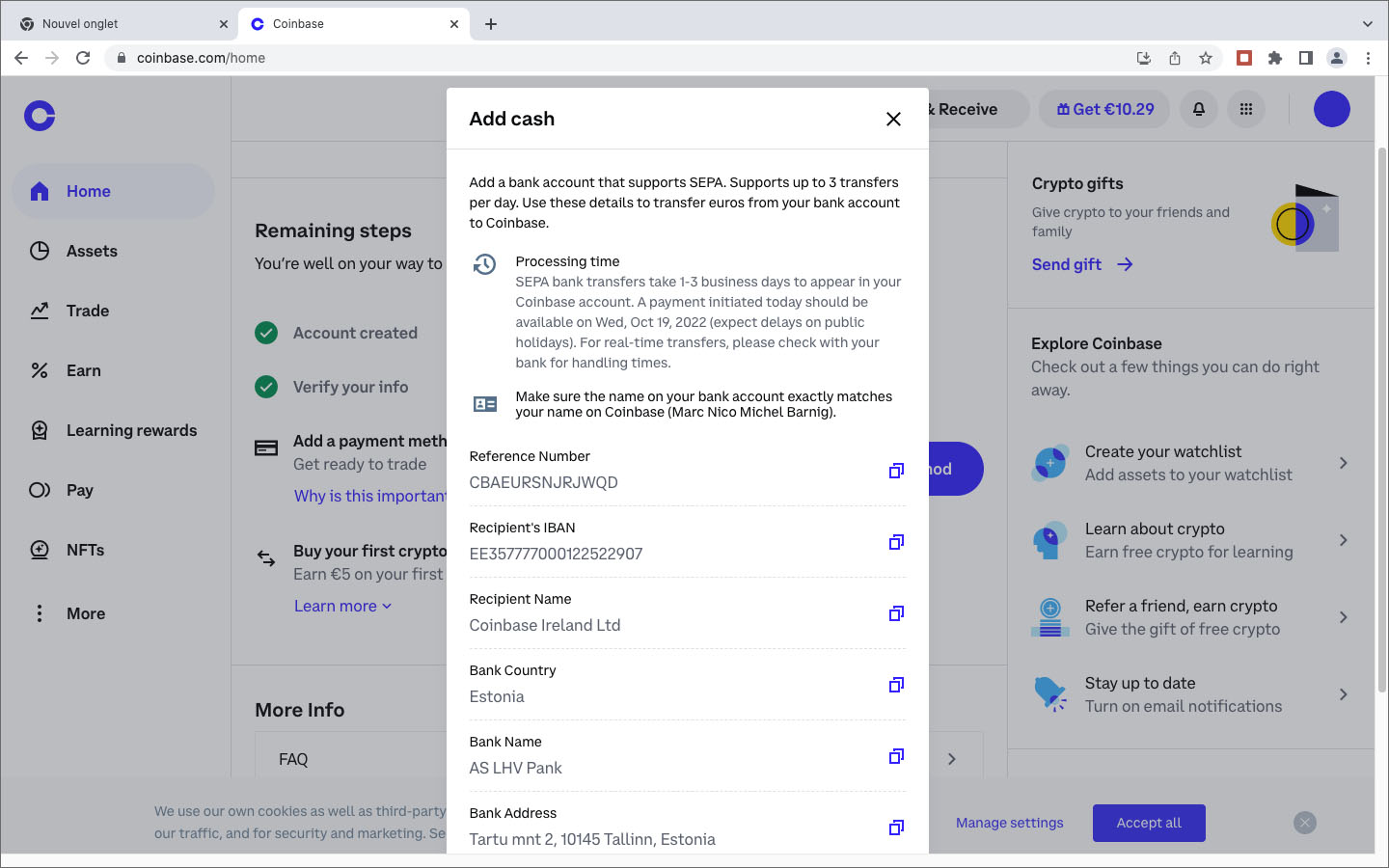
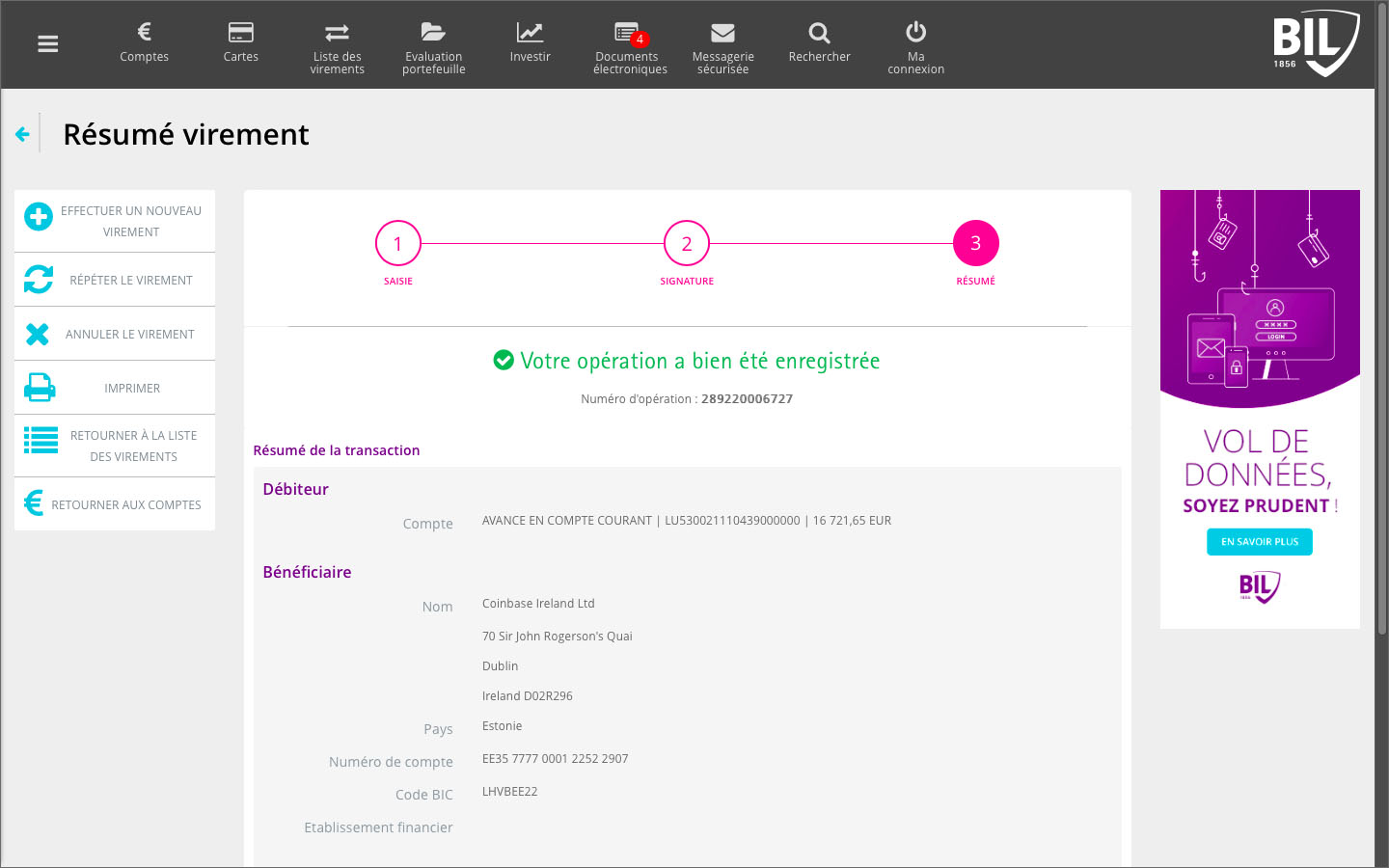
Après des recherches et investigations supplémentaires, j’étais persuadé que la société Coinbase, fondée en 2012, était un acteur fiable et j’ai décidé de lancer une deuxième tentative d’achat de crypto-monnaie auprès de ce marchand. Lors de la demande des coordonnées de ma carte de crédit, j’ai indiqué, avec la prudence voulue, les numéros et dates de ma carte Easy VISA prépayée de POST Luxembourg. Quelle était ma stupeur en lisant le message d’erreur que les cartes de crédit prépayées ne sont pas acceptées. Comme l’utilisation de ma carte de crédit standard sur des sites Internet, avec lesquels je n’ai pas de relations établies, me semblait trop risquée, j’ai opté pour une autre méthode de paiement proposée par Coinbase: un virement international SEPA. Sur BIL Online j’ai effectué un virement de 25€ sur une banque en Estonie, au profit d’une société domiciliée en Irlande, à l’attention de Coinbase . Le monde NFT est vraiment international ! Et c’était un succès. Trois jours plus tard j’étais le détenteur d’un compte Coinbase avec un dépôt de 25€. Les images ci-après documentent différentes étapes de mon processus de création de ce compte : téléchargement d’une copie de la carte d’identité, téléchargement d’un document récent de la banque avec mon nom et mon adresse postale, sauvegarde d’une photo selfie avec une notice “For Coinbase Trading 16.10.2022” dans la main, contrôle des données, réception d’un code de vérification par SMS, messages de confirmation, virement etc.
Cliquez sur une image pour l’agrandir
6. Portefeuille MetaMask
Pour convertir le dépôt sur Coinbase en crypto-monnaie il faut disposer d’un portefeuille numérique (wallet en anglais). Coinbase dispose de son propre portefeuille Coinbase Wallet, mais il est recommandé d’utiliser un portefeuille numérique non affilié à un marchand de crypto-monnaie. Dans la documentation sur les NFTs sur le web un nom d’un portefeuille indépendant est souvent référencé: MetaMask, avec comme logo une icône d’une tête de renard.
Portefeuille Metamask
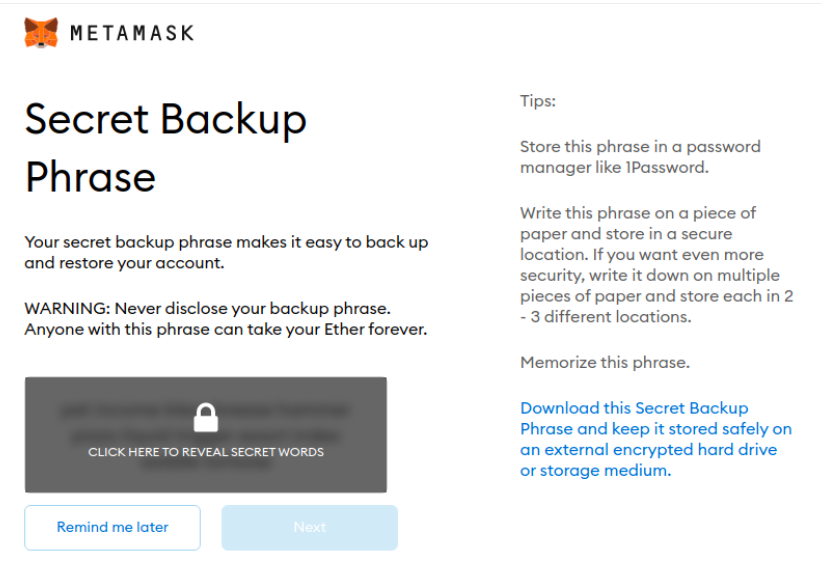
Le portefeuille existe en deux formats: comme extension pour un navigateur (web-browser) ou comme app pour les tablettes et mobiles. Bien que le navigateur Safari de mon MacBook n’est pas supporté par MetaMask, j’ai opté pour démarrer avec l’option extension navigateur. De toute façon je préfère utiliser le navigateur Chrome sur MacBook, car j’avais remarqué que de nombreuses pages web, en relation avec les NFTs, ne sont pas affichées correctement dans Safari. L’installation de l’extension MetaMask dans Chrome a été effectuée avec succès, moyennant quelques clics. La première étape consistait à valider une phrase secrète de 12 mots. Si on ne dispose plus de cette phrase, il n’y a aucun moyen pour récupérer son portefeuille.Une phrase secrète est proposé par MetaMask. L’image ci-après montre la fenêtre afférente:
Activation d’une phrase secrète de 12 mots pour créer un portefeuille numérique
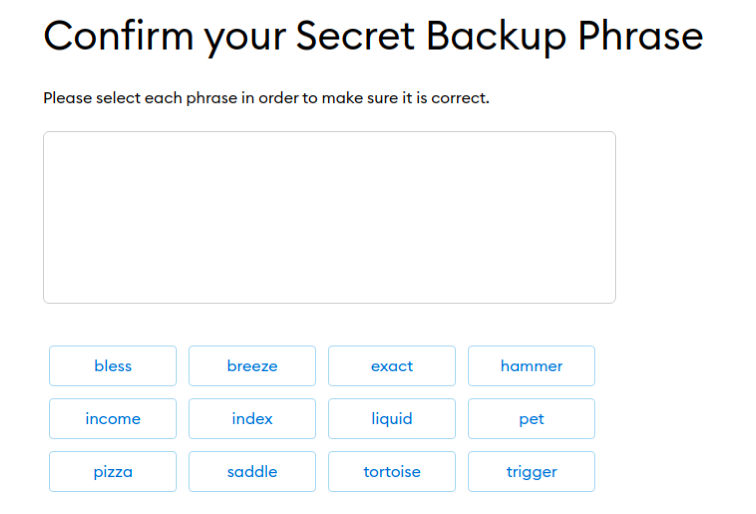
Pour confirmer il faut entrer les 12 mots dans le bon ordre dans la fenêtre qui suit:
Confirmation de la phrase secrète de 12 mots pour le portefeuille numérique MetaMask.
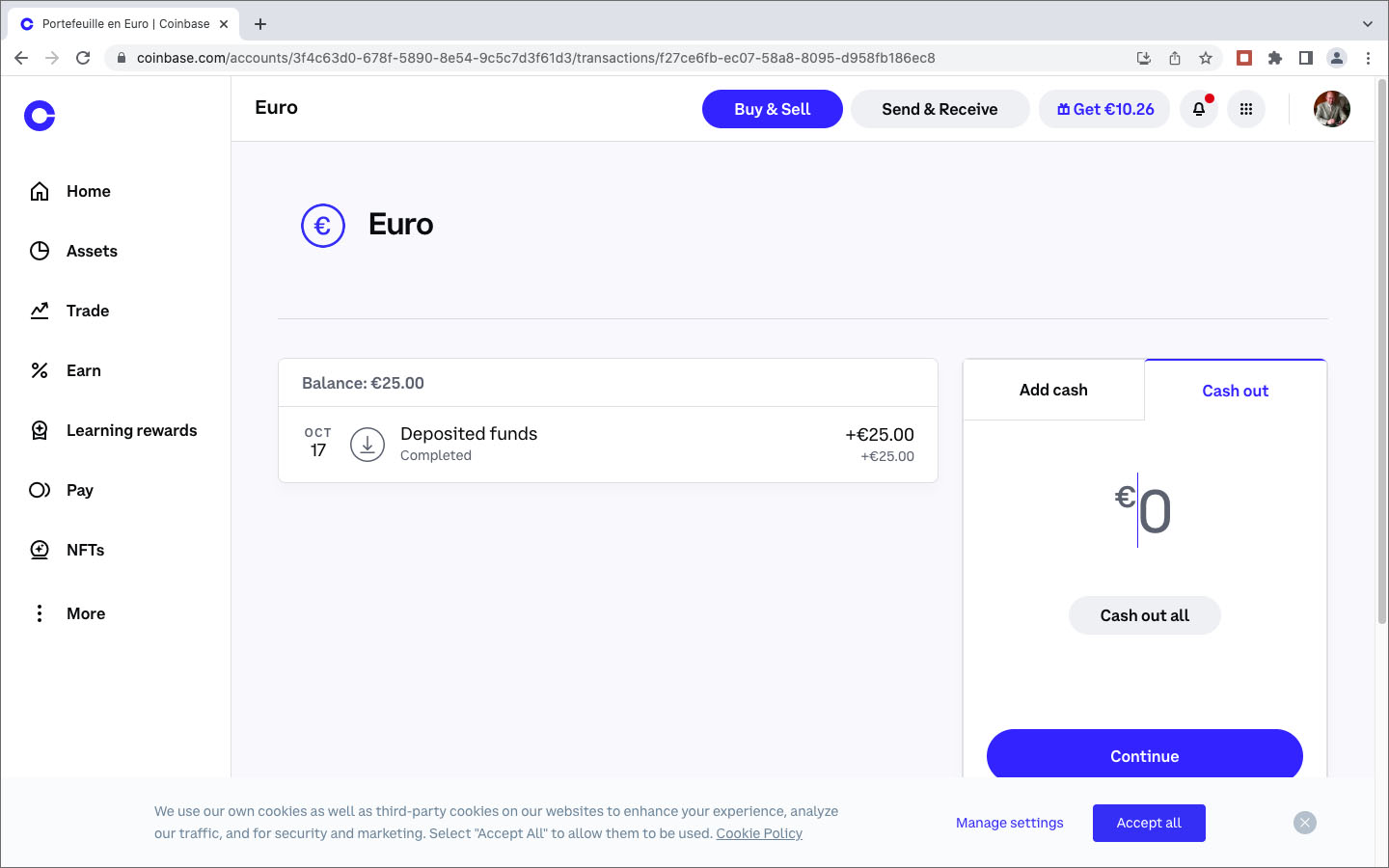
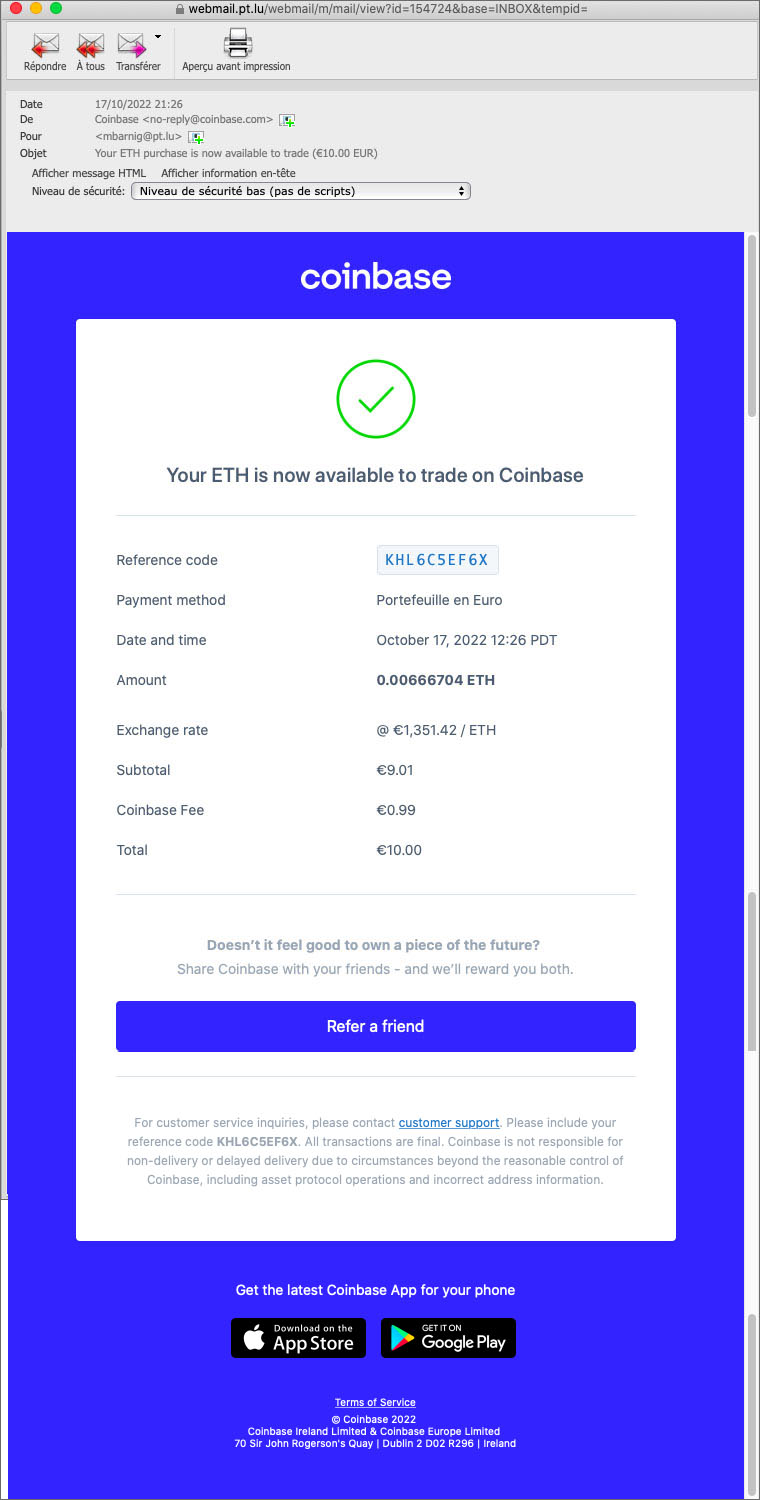
Il va de soi que la copie écran ci-dessus ne montre pas les vrais mots de mon portefeuille ! Après sauvegarde et confirmation de ma phrase de backup, le grand moment était venu pour convertir une partie de mon dépôt sur Coinbase en crypto-monnaie. J’ai commencé avec 10€. La conversion a pris un certain temps et Coinbase a retenu une commission de 0,99€.
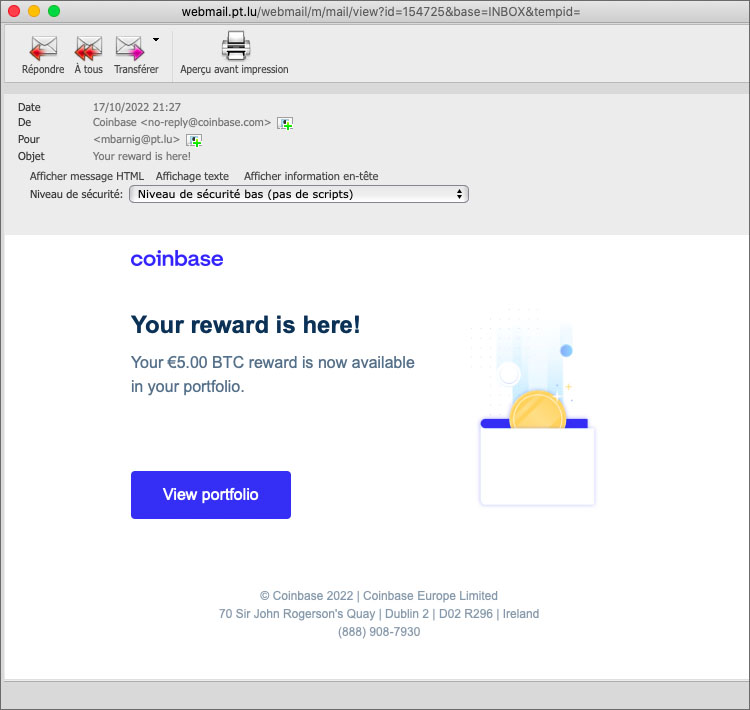
Le solde de 0,00665662 ETH, la crypto-monnaie de Ethereum, devait être suffisant pour payer mon NFT sélectionné au prix 0,004 ETH. En plus, j’ai reçu une récompense de 5€.
7. Premières tentatives d’achat d’une NFT
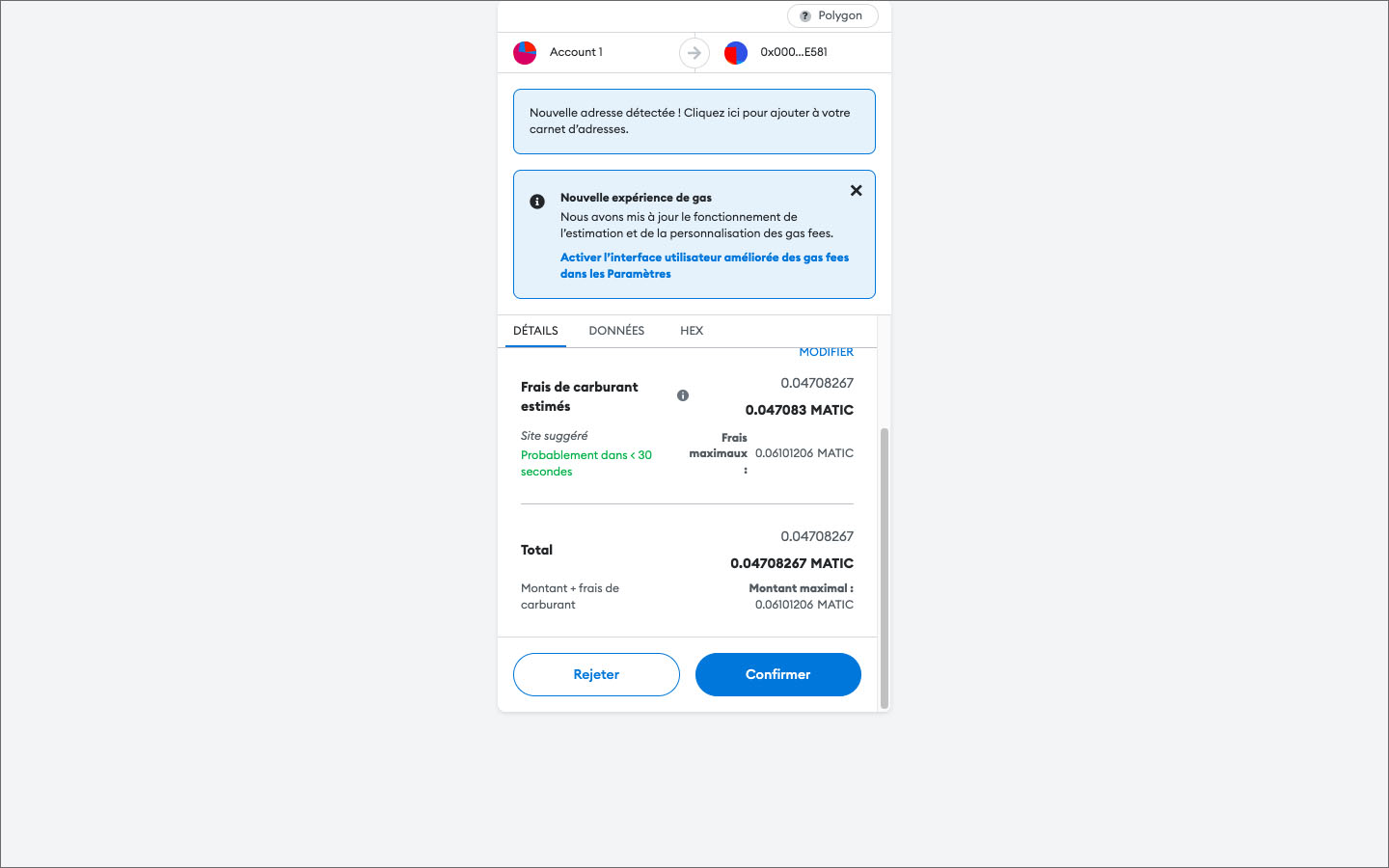
Pour acheter le NFT choisi, je retournais sur le site web Opensea et j’ai ajouté l’objet d’art dans mon caddie virtuel. J’ai été redirigé vers mon portefeuille MetaMask, j’ai confirmé l’achat et après plusieurs heures j’ai été informé que l’achat avait échoué. J’ai pensé que j’avais probablement effectué une mauvaise manipulation et je me suis lancé dans une deuxième tentative. Comme le montant des ETH dans mon portefeuille avait toutefois sensiblement diminué et était même inférieur à 0.001 unités, j’ai d’abord dû convertir le reste de mes 25€, virés sur Coinbase, en crypto-monnaie. Pour le deuxième essai d’achat j’ai soigneusement vérifié chaque pas et j’ai lu en détail toutes les informations affichées dans la séquence des fenêtres qui s’ouvraient après chaque clic sur un bouton de confirmation. Hélas ma deuxième tentative, ainsi qu’une troisième, ont également échoué et à la fin je me suis retrouvé sans NFT et presque sans ETHs restants. Pour me consoler, je me suis dit que la dépense des 25€ constituait un investissement dans mon apprentissage. J’ai passé les jours qui suivaient avec la recherche et la lecture de contributions sur Internet au sujet de l’achat de NFTs. A la fin j’étais conscient que j’avais commis plusieurs erreurs :
J’avais converti mes € en unités de crypto-monnaie ETH sur la chaîne de blocs Ethereum main au lieu de la chaîne Polygon. Il faut donc utiliser un pont (bridge) pour les transférer sur la chaîne dans laquelle le NFT sélectionné a été frappé.
Je n’avais pas pris note que le la version actuelle de l’extension MetaMask ne comporte pas de support natif des NFTs, mais qu’il est recommandé d’utiliser l’application pour mobiles pour gérer les achats.
J’avais sous-estimé les coûts des transactions en relation avec des chaînes de blocs. Pour chaque transaction il faut payer du gaz (ou du carburant; ce sont vraiment les termes techniques de ces opérations) pour les opérateurs qui gèrent d’une façon décentralisée les chaînes de blocs. Et même l’homme de la rue sait aujourd’hui que le gaz est cher ! En cas d’échec d’une transaction, les dépenses pour le gaz ne sont pas remboursées.
A coté des commissions encaissées par les marchands, mon dépôt de 25€ a donc surtout été utilisé pour brûler du gaz.
8. Première réussite d’acquisition d’une NFT
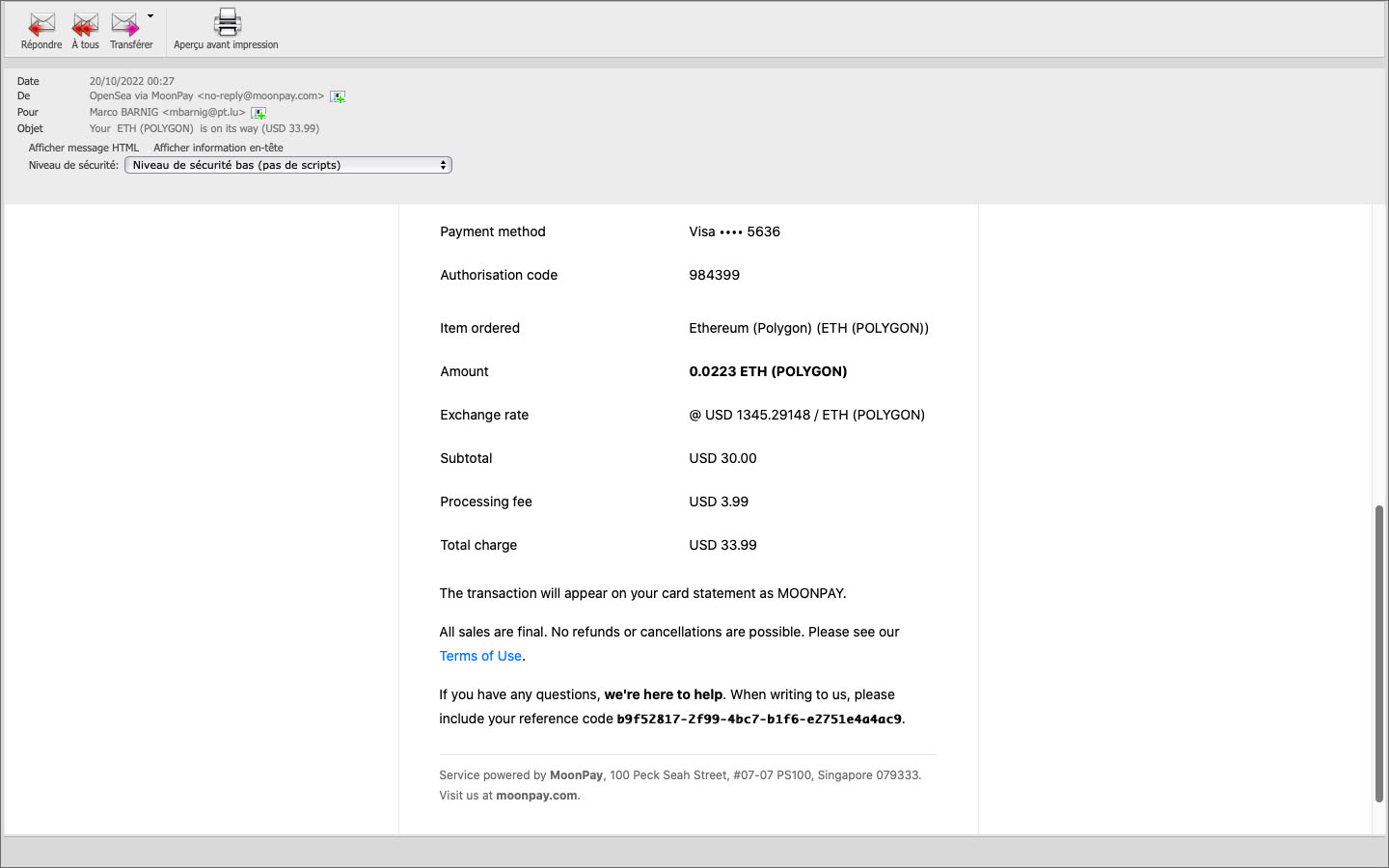
Pour progresser, j’ai d’abord téléchargé et installé l’application mobile MetaMask depuis l’AppStore d’Apple sur mon iPhone. Ensuite j’ai configuré et personnalisé cette app moyennant la saisie de ma phrase secrète à 12 mots. Comme je ne disposais plus de crédits, la prochaine étape consistait à recharger mon portefeuille. Lors de mes derniers recherches sur le web, j’avais appris qu’il était possible d’ajouter des fonds à partir de MetaTask, via le marchand Moonpay, avec une carte de crédit. Le minimum d’achat était de 30€, la commission de Moonpay était le triple (3,33€ pour 30€) de celle de Coinbase, mais en revanche ma carte de crédit prépayée Easy VISA a été acceptée.
Message de confirmation de paiement avec Moonpay
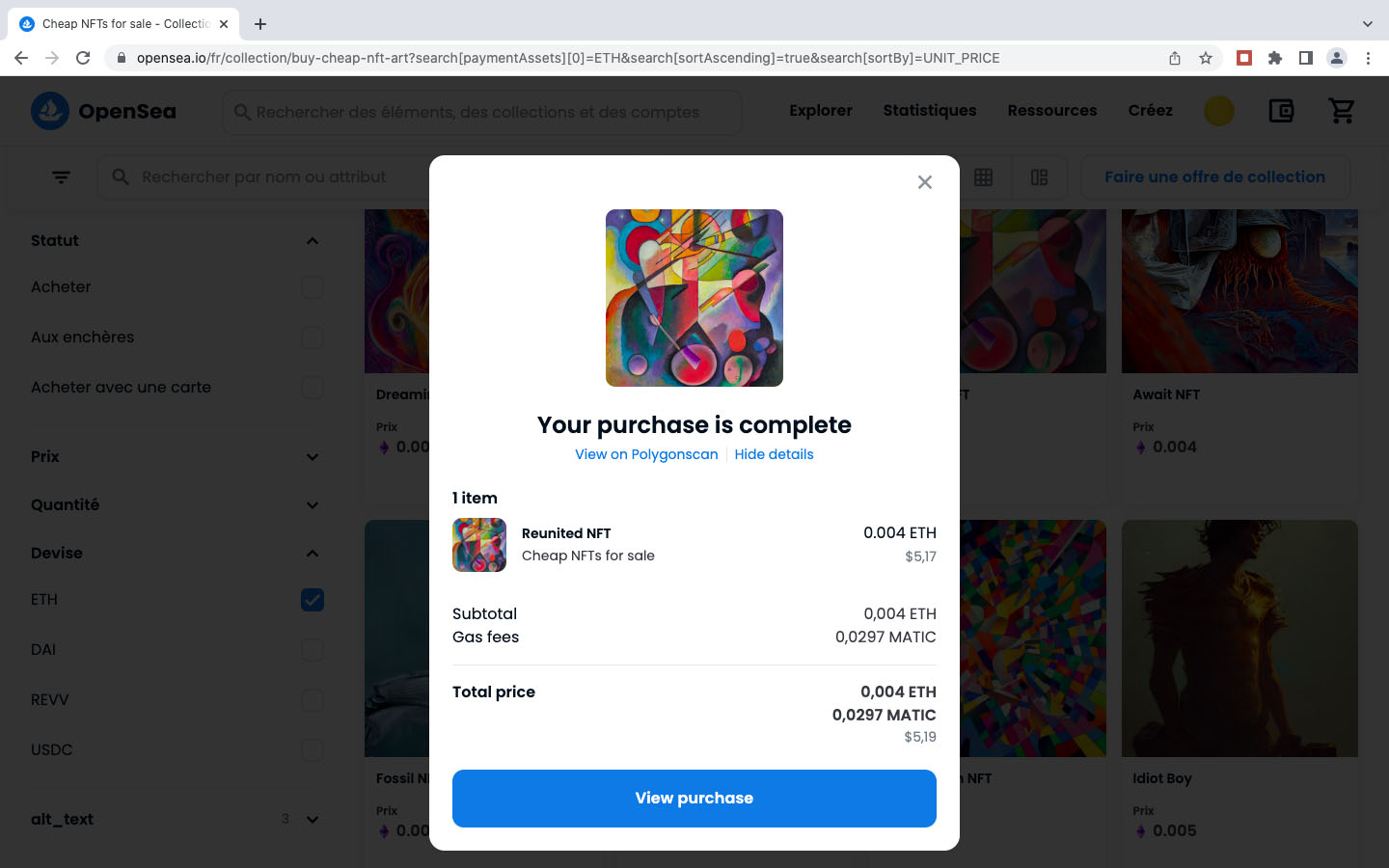
Après la réception d’un montant de 0.0223 ETH (Polygon), j’ai remis le NFT sélectionné dans mon caddy sur Opensea et ajusté le prix maximal à payer pour le gaz de la transaction. Après une dernière vérification de tous les éléments, jai confirmé l’achat. Quelques heures plus tard j’étais l’heureux propriétaire de l’oeuvre d’art numérique United NFT. La galerie d’images qui suit présente quelques copies écran du processus exécuté sur mon iPhone.
Cliquez sur une image pour l’agrandir
9. Création de mon premier NFT
Après ce succès d’achat d’un premier NFT, je me suis dit qu’il convient maintenant de vendre mon premier NFT. Mais avant de le vendre il faut le créer. J’étais d’avis qu’une simple image statique était trop banale et qu’il fallait présenter quelque chose qui bouge, par exemple une animation ou une vidéo. J’ai donc fouillé dans mes archives et j’ai trouvé une animation que j’avais réalisé il y a quelques années pour montrer une partie d’un jeu de moulin où une personne joue contre un ordinateur. J’ai développé et programmé ce tablier électronique d’un jeu de moulin (Elektronesch Millchen) en 1977.
Les 24 intersections du tablier contiennent chacune une photodiode et une LED. L’ordinateur joue avec des pions rouges et il signale par une LED clignotante où il souhaite poser son pion. Son adversaire humain pose un pion rouge sur la position indiquée et l’ordinateur acquitte la manoeuvre correcte en allumant la LED en permanence. Un pion posé par le joueur humain est reconnu par l’ordinateur via la photodiode et l’acquittement se fait également par l’allumage continue de la LED. Le clignotement de deux LEDs signale un changement de position d’un pion rouge voulue par l’ordinateur, tandis que le clignotement à côté d’un pion noir veut dire qu’il faut l’enlever, suite à un moulin fermé par l’ordinateur. Dans la présente animation le jeu se termine par un blocage de l’ordinateur et l’humain sort comme vainqueur. J’ai convertie l’animation en vidéo mp4 et je l’ai hébergée sur Youtube.
Certes cette animation n’est pas un chef-d’oeuvre artistique, mais elle se distingue par trois particularités. C’est d’abord un prédécesseur des systèmes actuels d’intelligence artificielle et un NFT afférent constituerait un témoignage historique. C’est également un objet numérique qui se prête pour former un élément unique parmi une collection de parties du jeu de moulin. Chaque partie serait basée sur une autre stratégie de jeu et chaque animation serait donc unique. Last not least c’est un projet artistique handmade. J’ai pris une photo du tablier après chaque changement de position d’un pion et j’ai retouché la couleur des LEDs dans Photoshop. Ensuite j’ai assemblé la centaine de photos dans une image animée GIF, avec une conversion finale en vidéo.
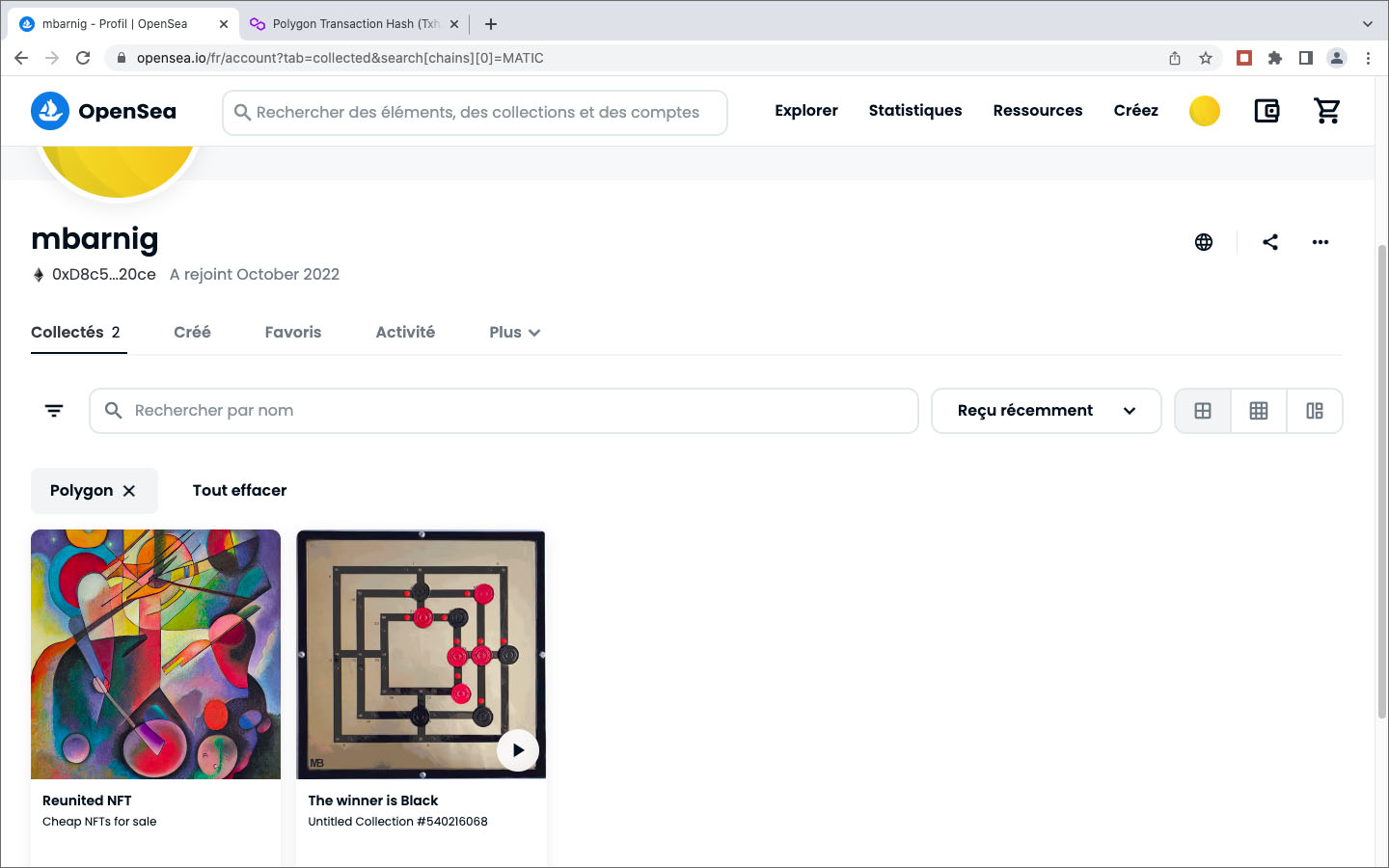
La création du NFT était facile et a été exécutée sans frais. J’ai téléchargé le fichier vidéo sur mon compte Opensea, j’ai spécifié la phrase The Winner is Black comme nom du NFT et j’ai définie comme prix de vente le même montant que celui de mon premier NFT acheté, c.à.d. 0.004 ETH (Polygon). La copie écran de ma page personnelle sur Opensea ci-après montre le résultat:
10. Vente de mon premier NFT
Pour forcer la vente (fake is in !) de mon NFT “The Winner is Black” j’ai invité mon ami virtuel Lutz Basel à faire l’achat. Pour ce faire il devait disposer de son propre portefeuille MetaMask. Comme on peut seulement installer un seul portefeuille comme extension d’un navigateur, ou comme application sur un mobile, Lutz a utilisé le navigateur Firefox, au lieu de Chrome, sur mon MacBook. Au lieu de mon iPhone il a pris mon mobile Android (Nokia 2.3) pour installer l’application MetaMask à partir du Google PlayStore.
En profitant de mon expérience concernant la configuration du portefeuille MetaMask, Lutz a vite réussi à confirmer une phrase backup de 12 mots pour initialiser son portefeuille. Je souhaitais transférer les frais d’achat de mon portefeuille sur celui de Lutz. C’était facile, au lieu de saisir le code d’identité du portfeuille de Lutz, composé d’une séquence de 42 caractères et chiffres, j’ai pu capter le code QR afférent avec la caméra de mon iPhone. Avec le gaz nécessaire, la transaction a été rapidement exécutée. Il restait à Lutz de chercher son objet d’art sur Opensea, de le mettre dans son caddy, de confirmer l’achat, sans oublier le gaz, et le NFT changait de propriétaire. Ma première vente d’un NFT était une réussite ! Comme d’habitude, je joins ci-après quelques copies écran pour illustrer le processus sur mon mobile Nokia.
Cliquez pour agrandir les images
11. Inspection de la chaîne de blocs
Pour m’assurer que l’achat et la vente de mes NFT sont correctement enregistrés, je souhaite inspecter la chaîne de blocs correspondante. L’outil pour ce faire s’appelle blockchain explorer. En principe chaque chaîne de blocs dispose de son propre explorateur, mais il y a quelques outils qui supportent plusieurs chaînes. Mes propres transactions pour l’achat et la vente d’un NFT ont été exécutées sur la chaîne de blocs Polygon et l’outil d’exploration afférente s’appelle Polygonscan. Pour trouver une transaction spécifique, on peut spécifier l’identité d’un portefeuille, le numéro d’un bloc, le hash de la transaction, etc, comme critère de recherche. Souvent on connaît seulement l’identité du portefeuille utilisé:
Marco Barnig, ID : 0xD8c59cb936Db3767b6d7079563D7BEa9a75720ce
Je commence avec mon ami virtuel Lutz Basel qui a effectué 3 transactions: la première est liée à mon transfert de fonds, la deuxième constitue l’approbation de la réception de ces fonds et la troisième se réfère à l’achat de mon NFT. La copie écran qui suit montre les résultats de recherche avec l’ID du portefeuille de Lutz Basel.
Transactions effectuées par Lutz Basel
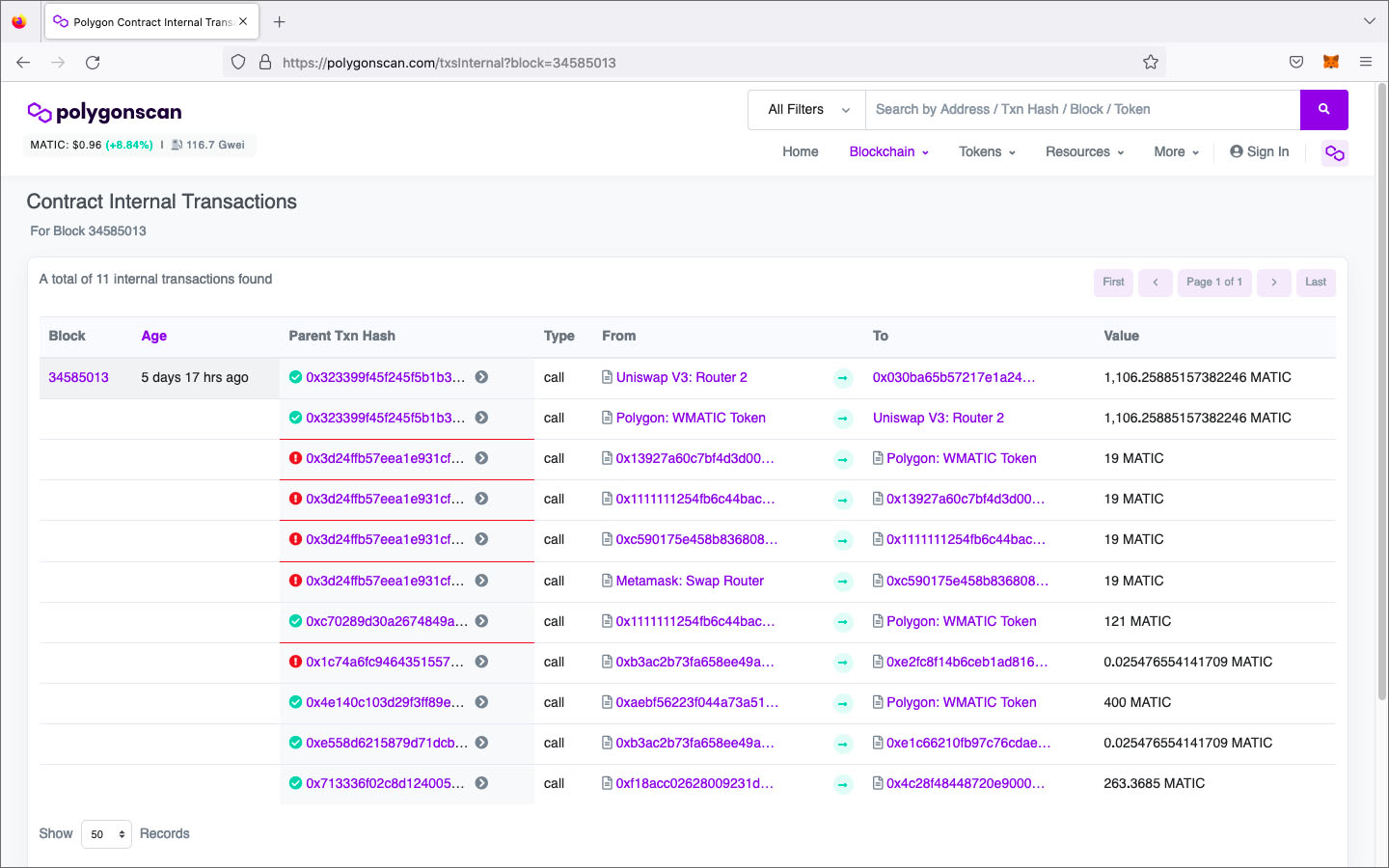
Les trois transactions sont relevées en bas de la page web. Si on clique sur le numéro du bloc d’une transaction, les détails de ce bloc sont affichés dans une nouvelle fenêtre. L’image qui suit montre un exemple, il s’agit du bloc No 34585013 affilié à l’achat du NFT.
Contenu du bloc No 3458013
On constate que le bloc en question contient 53 transactions internes et 11 transactions liées à un contrat interne. Un bloc rassemble plusieurs transactions lancées par différents usagers. Les images qui suivent montrent des extraits des listes détaillées de ces transactions qui sont affichées si on clique sur les liens inclus dans la ligne intitulée Transactions.
Liste des transactions intégrées dans le bloc No 3458013
Avec le hashtag de la transaction on peut rechercher les données dans le bloc en question. Je l’ai marqué en jaune dans la liste des 53 transactions internes incluses dans le bloc No 3458013.
Pour comprendre le contenu des autres données enregistrées dans le bloc il faut être expert et les explications à ce sujet dépasseraient le cadre de la présente contribution. Je laisse le plaisir aux lecteurs avertis d’explorer les autres blocs, ainsi que les blocs associés à mon propre portefeuille. Ces blocs contiennent également toutes les transactions échouées lors de mes premiers essais.
Si vous éprouvez des problèmes de compréhension, vous devez vous rappeler les témoignages des deux artistes au début de mon article au sujet de la complexité de la technologie NFT et de la durée d’apprentissage d’une année. Ce rappel termine la première partie de la présente. Dans les prochains chapitres je vais ajouter quelques généralités sur les techniques en mettant le focus sur la situation au Luxembourg.
12. Les fondations des NFTs
Dans la première partie de cet article j’ai introduit les technologies qui constituent les fondations des NFTs. Dans la suite je vais compléter la description des éléments suivants:
crypto-monnaie (crypto currencies)
chaîne de blocs (blockchain)
jetons (tokens) et transactions (transactions)
portefeuilles (wallets)
blocs (blocks) et carburant (gas)
plateformes de marché NFT
12.1 Crypto-monnaie
Wikipedia fournit la définition suivante de la crypto-monnaie :
Une crypto-monnaie, dite aussi cryptoactif, cryptodevise, monnaie cryptographique ou encore cybermonnaie, est une monnaie numérique (actif numérique) émise de pair à pair, sans nécessité de banque centrale, utilisable au moyen d’un réseau informatique décentralisé. Elle utilise des technologies de cryptographie et associe l’utilisateur aux processus d’émission et de règlement des transactions.
Comme il n’y a pas de régulateur de la crypto-monnaie, on ne dispose pas de chiffres exactes sur ce marché. La société CoinMarketCap, fondée en 2013 par Brandon Chez, maintient le site web le plus référencé dans ce domaine. On estime qu’en 2022 plus de 20.000 monnaies différentes existent, mais dont la moitié n’est plus marchandé. La valeur totale du marché dépasse 10.000 milliards €.
Dans la première partie de l’article nous avons fait connaissance de quatre crypto-monnaies: Tezos, ETH (main), ETH (Polygon), MATIC. Le Bitcoin (BTC) était la première monnaie cryptographique, présentée dans un livre blanc en 2008, par une personne au pseudonyme de Satoshi Nakamoto. Le code source de l’implémentation de référence a été publié en 2009. Le Bitcoin est toujours la crypto-monnaie la plus connue. Parmi la multitude des monnaies il convient de citer les autres représentants populaires suivants : Tether (USDT), BNB, XRP, Cardano (ADA), Solana (SOL), Dogecoin (DOGE) et Polkadot (DOT).
La valeur d’une crypto-monnaie par rapport aux $ ou € peut varier d’une seconde à l’autre. Les images qui suivent montrent la valeur de mon portefeuille à une intervalle de 24 heures. L’ETH a perdu de 3,6% en valeur.
Valeurs du 27.10.2022Valeurs du 28.10.2022Cliquez pour agrandir les images
Les fluctuations de la valeur de l’ETH pendant une journée sont affichées ci-après :
Fluctuations de la valeur de l’ETH
Pour certains internautes le marchandage de crypto-monnaie est devenu une drogue. Certains gagnent gros, mais la majorité fait des pertes. Il faut être conscient que ceux qui gagnent dans tous les cas sont les marchands professionnels avec les commissions et les mineurs avec la vente du gaz.
On ne compte pas seulement des milliers de crypto-monnaies, mais également des milliers de plateformes pour acheter ou vendre des crypto-monnaies.
12.2 Chaînes de blocs (Blockchains)
Dans la première partie de la présente trois blockchains ont été présentées : Tezos, Ethereum et Polygon. Mais il y a des centaines, voire des milliers de chaînes différentes. On distingue quatre types:
blockchains publiques
blockchains privées
blockchains de consortium
blockchains hybrides
A coté des blockchains référencées ci-avant (Bitcoin, Ethereum,Tezos et Polygon), quelques autres plateformes de renom sont relevées ci-après :
Le Luxembourg est bien positionné dans le domaine de ces nouvelles technologies. Sur le site web luxembourg.public.lu on peut lire que le Luxembourg se veut pionnier européen dans le monde du blockchain.
Luxembourg Blockchain
La définition suivante du blockchain est fournie sur ce site :
Décentralisation, transparence et immutabilité sont les mots clé du blockchain. Au Luxembourg les piliers ont été construits pour définir la bonne stratégie de développement de ces chaînes logistiques. En route maintenant pour favoriser l’adoption à grande échelle et pour le bien général du pays.
Un blockchain est un enregistrement numérique des transactions. Son nom vient de sa structure, dans laquelle les enregistrements individuels, appelés blocs, sont reliés entre eux dans une liste unique, appelée chaîne. Aujourd’hui, les chaînes de blocs sont utilisées principalement dans le secteur financier, mais l’identification numérique, la preuve de la propriété foncière, la gestion de la chaîne logistique et même le vote ne sont qu’une fraction des applications potentielles qui seraient d’intérêt pour le secteur public aussi.
Son fonctionnement décentralisé permet en outre de résoudre des problèmes liés à des points d’échec unique en cas de sinistres ou d’attaques et porte ainsi le potentiel d’aider les acteurs publics et les entreprises à réduire la fraude et les erreurs ou à améliorer la transparence de leurs données et transactions.
LIST (Luxembourg Institut of Science and Technology)
SnT (Interdisciplinary Centre for Security, Reliability and Trust de l’Université du Luxembourg)
Luxembourg Blockchain Lab
Les cinq acteurs ont fondé le Luxembourg Blockchain Lab (LBL) pour créer un large écosystème du blockchain au Luxembourg. Le laboratoire a organisé une première semaine Blockchain (blockchainweeks) du 26 au 30 avril 2021 au Luxembourg. Une deuxième édition des blockchainweeks a eu lieu du 3 au 7 octobre 2022.
L’unité de données stockée dans une chaine de blocs, qui est unique, est appelée jeton (token en anglais). On distingue les jetons fongibles et les jetons non-fongibles. Un jeton fongible appartient à une même catégorie et ne se distingue pas des autres jetons appartenant à cette catégorie. Par exemple, un bitcoin ne possède pas d’identité propre et ne peut pas être tracé. Un bitcoin vaut toujours un autre bitcoin et peut être remplacé par n’importe quel autre bitcoin. On dit qu’il est interchangeable, c.à.d. fongible. La majorité des crypto-monnaies, et toutes les monnaies réelles, sont fongibles.
Les unités de données stockées dans une chaine de blocs qui disposent d’une identité numérique sont appelés jetons non-fongibles (NFT : Non-Fungible Token). Ils ne peuvent pas s’échanger, même s’ils appartiennent à une même catégorie. L’identité numérique constitue un genre de certificat infalsifiable qui atteste de l’authenticité et de la propriété d’un objet virtuel. Nous avons déjà vu les exemples des objets numériques appartenant à la catégorie de l’art contemporain et les contrats des aides financières luxembourgeoises pour les études supérieures. Les domaines d’utilisation des NFT sont innombrables. Par exemple des vignerons utilisent les NFT moyennant des codes QR ou des puces NFC dans les bouchons pour lutter contre la contrefaçon des vins de renom. Au Luxembourg c’est surtout le marché financier qui applique la technologie NFT, mais la société italienne Guala Closures Group, qui produit des bouchons NFC, a installé en 2017 son cinquième centre de recherche dans le monde au Luxembourg. Grâce à une collaboration avec la société luxembourgeoise Compellio les clients peuvent créer leurs propres caves de vin virtuelles avec la technologie NFT.
Wine Developers avec bouchons NFC
Toute manipulation d’un jeton, fongible ou non-fongible, est documentée dans une transaction qui est enregistrée dans un bloc d’une blockchain spécifique.
12.4 Portefeuilles numériques
Pour conserver et gérer ses jetons il faut disposer d’un portefeuille numérique (eWallet). Nous avons déjà fait la connaissance des portefeuilles MetaMask et Coinbase Wallet. Mais il y a une multitude d’autres exemplaires pour tous les goûts. D’abord il faut distinguer les différents supports de portefeuilles numériques:
logiciel
matériel
papier
Les portefeuilles basés sur du matériel procurent la meilleure sécurité. Ceux en forme de logiciel sont les plus flexibles. On distingue des extensions pour navigateurs, des programmes pour ordinateurs ou des applications pour tablettes ou mobiles. On fait encore la différence entre portefeuilles chauds (hot wallets) qui sont toujours connectés à Internet et les portefeuilles froids (cold wallets) qui fonctionnent hors ligne. Les meilleurs combinent et les NFT et les crypto-monnaies et supportent plusieurs blockchains. Les plus simples sont spécialisés pour une seule tâche ou une catégorie NFT déterminée. Des critères de sélection sont bien sûr la sécurité, mais également la facilité de configuration et d’utilisation ainsi que la compatibilité. Les usagers qui veulent éviter tout risque de piratage peuvent revenir au bon vieux papier. Parmi les milliers de portefeuilles proposés sur Internet, quelques exemples populaires sont relevés ci-après:
Le lecteur sait désormais que toute transaction de jetons est enregistrée dans un bloc qui fait partie d’une chaîne gérée dans un réseau blockchain d’une façon décentralisée. La création d’un nouveau bloc fait référence à une technique ancienne: le minage. Le réseau du type pair-à-pair sur Internet est constitué de serveurs qui fonctionnent grâce à un logiciel dédié. Dans le cas du Bitcoin ce logiciel est Bitcoin-Core. Chaque noeud du réseau dispose d’une copie de la blockchain en question.
Qui sont les gestionnaires de ces réseaux ? Ce sont des individuels, collectifs ou entreprises, appelés mineurs, qui exploitent un noeud de ce réseau. Chacun peut le faire à condition de disposer d’un ordinateur performant, car les calculs cryptographiques à exécuter demandent des puissances de calcul très importantes et des mémoires de taille. En contrepartie les mineurs sont rémunérés pour leurs efforts. Prenons l’exemple de mon transaction pour transférer 15€ à mon ami virtuel Lutz Basel. Le processus se déroule en plusieurs étapes:
Je déclenche la transaction en poussant le bouton confirmation dans mon portefeuille.
La transaction est diffusée dans le réseau par le logiciel du portefeuille MetaMask et placée dans un pool de transactions non confirmées.
Les mineurs sont connectés à ce pool et essayent de rassembler plusieurs transactions du pool pour les intégrer dans un nouveau bloc candidat. Il est probable que mon transaction soit incluse dans des blocs candidats de différents mineurs.
La validité de ma transaction est contrôlée par les mineurs en vérifiant si mon portefeuille dispose des fonds ou jetons suffisants et si toutes les obligations sont respectées.
Les blocs candidats reçoivent une signature nommée preuve de travail en résolvant un problème mathématique très complexe, unique à chaque bloc de transactions. Cette étape est appelée processus de minage.
Le mineur qui a calculé le premier la signature du nouveau bloc candidat diffuse ce blog et la signature à tous les autres noeuds du réseau.
Les autres mineurs vérifient la légitimité de la signature. En cas de validité ils confirment que le bloc peut être ajouté à la chaîne. Ils doivent être tous d’accord, on appelle le processus algorithme de consensus.
Le mineur dont le bloc a été validé reçoit une récompense fixe pour le bloc et une récompense variable (frais de transaction) pour chaque transaction incluse dans le bloc.
Les autres mineurs qui ont inclus mon transaction dans leur bloc candidat doivent recommencer à zéro et la retirer de leur bloc candidat, de même que les autres transactions qui sont déjà intégrées dans le dernier bloc ajouté à la chaîne.
Le succès des mineurs est conditionné par plusieurs facteurs: la performance de leur infrastructure de calcul, la stratégie de minage employée, le trafic et le nombre de noeuds actifs sur le réseau et la chance. Certains mineurs accordent une priorité aux transactions compliquées comportant des frais de transaction importants pour obtenir une meilleure rémunération. D’autres se spécialisent sur des volumes élevés avec des transactions à faible coûts. Le protocole de minage règle la complexité du problème mathématique en fonction des besoins pour maintenir un temps moyen constant entre chaque nouveau bloc.
Dans le cas ou deux nouveaux blocs sont minés simultanément, le protocole prévoit de retenir le bloc le plus long et l’autre est écarté. Après avoir saisi le fonctionnement et la complexité du minage, on comprend mieux la notion de carburant ou de gaz pour rémunérer le travail des mineurs. Si une transaction échoue, par exemple parce que les jetons dans le portefeuille sont insuffisants, les frais de transaction sont encaissés par les mineurs. Si on spécifie un plafond trop bas pour le gaz, les mineurs ont peu d’intérêt pour traiter la transaction en question et elle risque de rester longtemps en attente ou d’atteindre un time-out.
Le minage classique basé sur la preuve de travail a des inconvénients, notamment en ce qui concerne la consommation électrique qui est très conséquente au niveau mondial et qui le classe comme mauvais élève en termes climatiques. Pour pallier à ce problèmes, d’autres méthodes de minage ont été développées:
le minage par tiers de confiance: c’est le modèle privilégié des blockchains privés, mais c’est une véritable trahison du modèle original décentralisé.
le minage par consensus: des noeuds maîtres décident sur le consensus d’une façon certaine et déterministe; le réseau est donc partiellement centralisé, même si le nombre de noeuds maîtres est élevé.
le minage par preuve d’enjeu: des mineurs sont désignés d’une façon pseudo-aléatoire en fonction de leur fortune détenue sur le blockchain pour décider sur le consensus.
Il y a de plus en plus de pays qui envisagent d’interdire le minage par preuve de travail pour des raisons écologiques. Dans le prochain chapitre nous allons nous intéresser pour les plateformes de marchandage, de marché et d’échange.
12.6 Plateformes de crypto-monnaies et de NFTs
Les plateformes de crypto-monnaies Crypto, Coinbase et Moonpay ont été introduites dans la première partie de la présente contribution, de même que les places de marché FNT objkt.com et Opensea.
Quelques autres plateformes de crypto-monnaies sont:
Comme le marché des plateformes de crypto-monnaies et de jetons non-fongibles est très volatil, il importe de se renseigner sur la situation actuelle avant de s’engager dans une plateforme déterminée.
13. Conclusions
Après avoir exploré en détail le monde des NFTs, j’ai l’impression de me retrouver 25 ans en arrière au moment de la bulle Internet. Je crains qu’on se trouve au début d’une bulle NFT et qu’à moyen terme on va se heurter aux mêmes débâcles qu’à la fin des années 1990: endettements, faillites, consolidations, dépréciations, restructurations, démissions, poursuites judiciaires etc.
En tout cas il importe de se familiariser avec la technologie NFT avant de faire des investissements risqués.
Le titre de ma présente publication est le résultat d’une traduction automatique française -> allemande du début de la phrase “La bise et le soleil se disputaient, chacun assurant qu’il était le plus fort, quand ils ont vu un voyageur qui s’avançait, enveloppé dans son manteau”.
C’est le début d’une fable d’Ésope, extraite d’un ensemble de fables en prose qu’on attribue à l’écrivain grec Ésope. Le texte de la fable La bise et le soleil est utilisé régulièrement par des linguistes dans le cadre de projets de recherche sur le traitement du language naturel (NLP: Natural Language Processing). Cette fable a été traduite dans des centaines de langues mondiales et régionales. Comme je vais me référer plusieurs fois sur cette fable, je vais d’emblée présenter l’intégralité du texte dans les versions française, allemande, anglaise et luxembourgeoise ci-après.
Fables d’Ésope
Les fables d’Ésope sont des centaines de textes et toutes sortes de récits qui circulaient oralement dans la Grèce antique et qui ont inspiré de nombreux auteurs comme Phèdre, Marie de France, Jean de la Fontaine. La fable d’Ésope La bise et le soleil est très courte, sa morale réside dans l’enseignement que la persuasion, plus lente, s’avère toutefois plus efficace que la violence.
Oeuvre d’art générée par le programme d’intelligence artificielle DALL*E2 avec l’introduction de la description “3D rendering of the fable The North Wind and the Sun were disputing which was the stronger, when a traveler came along wrapped in a warm cloak.”
La bise et le soleil
La bise et le soleil se disputaient, chacun assurant qu’il était le plus fort, quand ils ont vu un voyageur qui s’avançait, enveloppé dans son manteau. Ils sont tombés d’accord que celui qui arriverait le premier à faire ôter son manteau au voyageur serait regardé comme le plus fort. Alors, la bise s’est mise à souffler de toute sa force mais plus elle soufflait, plus le voyageur serrait son manteau autour de lui et à la fin, la bise a renoncé à le lui faire ôter. Alors le soleil a commencé à briller et au bout d’un moment, le voyageur, réchauffé, a ôté son manteau. Ainsi, la bise a dû reconnaître que le soleil était le plus fort des deux.
Norwind und Sonne
Einst stritten sich Nordwind und Sonne, wer von ihnen beiden wohl der Stärkere wäre, als ein Wanderer, der in einen warmen Mantel gehüllt war, des Weges daherkam. Sie wurden einig, daß derjenige für den Stärkeren gelten sollte, der den Wanderer zwingen würde, seinen Mantel abzunehmen. Der Nordwind blies mit aller Macht, aber je mehr er blies, desto fester hüllte sich der Wanderer in seinen Mantel ein. Endlich gab der Nordwind den Kampf auf. Nun erwärmte die Sonne die Luft mit ihren freundlichen Strahlen, und schon nach wenigen Augenblicken zog der Wanderer seinen Mantel aus. Da mußte der Nordwind zugeben, daß die Sonne von ihnen beiden der Stärkere war.
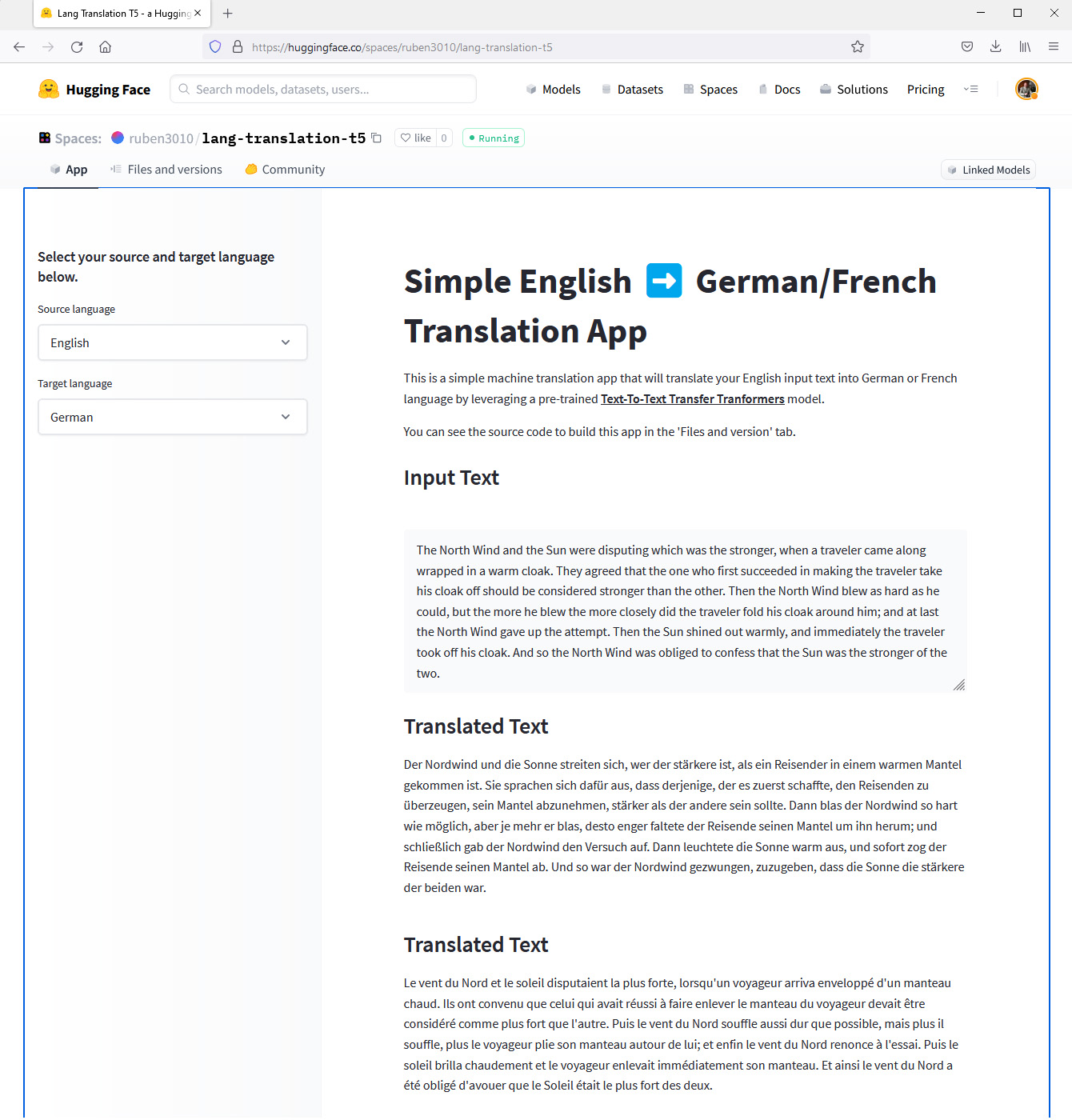
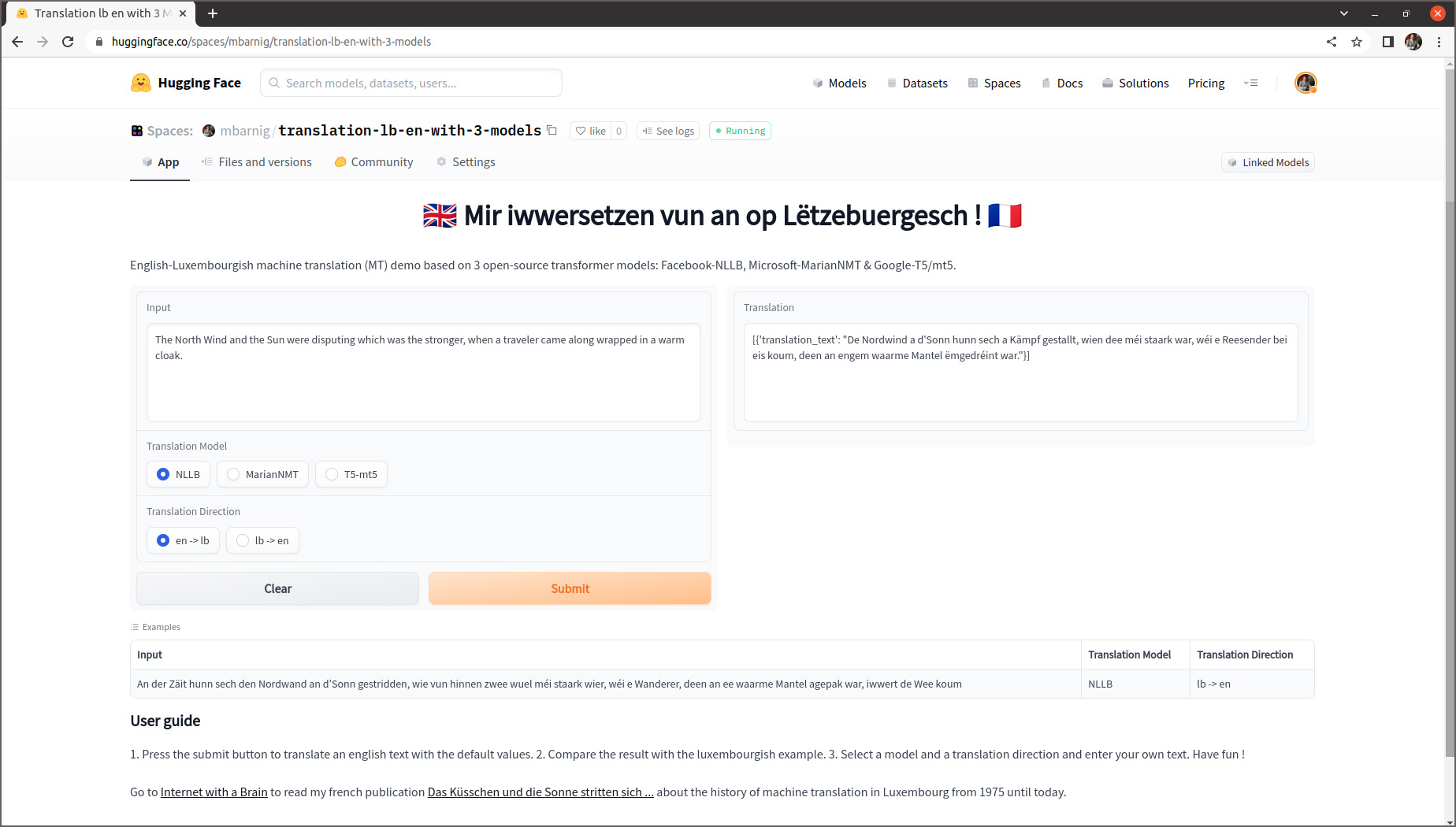
The northwind and the sun
The North Wind and the Sun were disputing which was the stronger, when a traveler came along wrapped in a warm cloak. They agreed that the one who first succeeded in making the traveler take his cloak off should be considered stronger than the other. Then the North Wind blew as hard as he could, but the more he blew the more closely did the traveler fold his cloak around him; and at last the North Wind gave up the attempt. Then the Sun shined out warmly, and immediately the traveler took off his cloak. And so the North Wind was obliged to confess that the Sun was the stronger of the two.
De Nordwand an d’Sonn
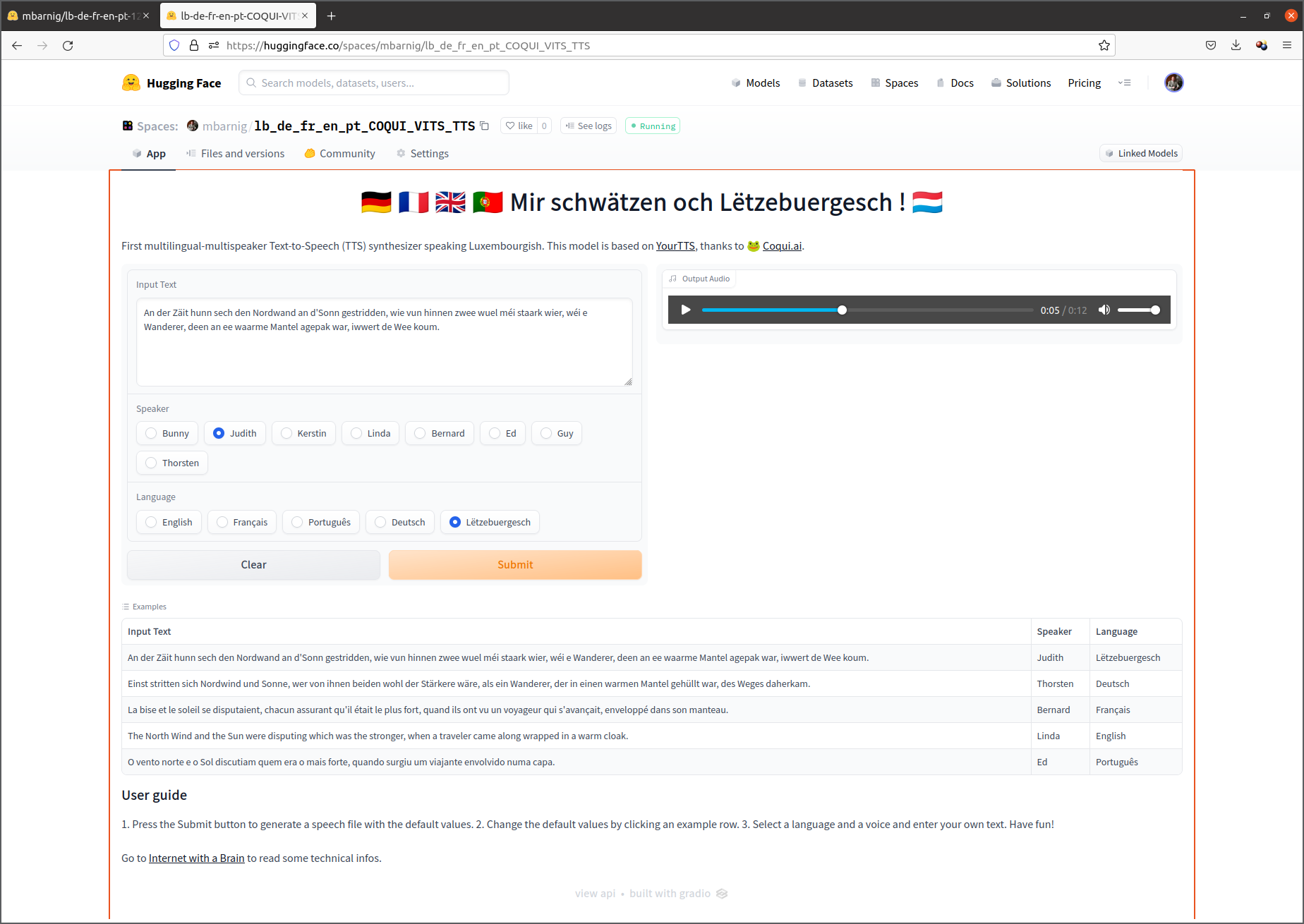
An der Zäit hunn sech den Nordwand an d’Sonn gestridden, wie vun hinnen zwee wuel méi staark wier, wéi e Wanderer, deen an ee waarme Mantel agepak war, iwwert de Wee koum. Si goufen sech eens, datt deejéinege fir dee Stäerkste gëlle sollt, deen de Wanderer forcéiere géif, säi Mantel auszedoen. Den Nordwand huet mat aller Force geblosen, awer wat e méi geblosen huet, wat de Wanderer sech méi a säi Mantel agewéckelt huet. Um Enn huet den Nordwand säi Kampf opginn. Dunn huet d’Sonn d’Loft mat hire frëndleche Strale gewiermt, a schonn no kuerzer Zäit huet de Wanderer säi Mantel ausgedoen. Do huet den Nordwand missen zouginn, datt d’Sonn vun hinnen zwee dee Stäerkste wier.
Histoire de la traduction automatique au Luxembourg et au delà
Le Luxembourg figure parmi les pionniers dans l’utilisation de la traduction automatique du fait que les nombreuses institutions européennes, ayant leur siège dans le pays, doivent gérer leurs documents dans les différentes langues officielles de la communauté européenne. Hélas, le luxembourgeois ne fait pas partie de ces languages et ce n’est que récemment que la langue luxembourgeoise est supporté par les systèmes de traduction automatique.
Tout a commencé au début des années 1950 avec la fondation de la Communauté européenne du charbon etde l’acier (CECA) par six nations européennes, dont le Luxembourg. La CECA a été dirigée par la Haute Autorité qui siégeait à Luxembourg et qui gérait quatre langues officielles: français, allemand, italien et néerlandais.
A la même époque, Warren Weaver, un mathématicien américain, concrétisait ses idées au sujet de la traduction automatique, communiquées en mars 1947 au cybernéticien Norrbert Wiener et publiées en juillet 1949 dans un mémorandum au sujet de la traduction. Sous l’influence de Warren Weaver dans sa qualité de directeur de la fondation Rockefeller, la première démonstration d’une traduction complètement automatique de 60 phrases russes en anglais a eu lieu en janvier 1954. Le développement a été conduit par l’Université de Georgetown, ensemble avec IBM.
La même année, les premieres recherches en traduction automatique ont débuté en URSS. Elles se distinguaient des recherches américaines par leur caractère théorique et le choix d’une méthode faisant appel a une langue intermédiaire. Aussi bien du côté américain que du côté russe, la traduction automatique était une arme de la guerre froide. Mais le développement de la traduction automatique ne progressait pas comme prévue et au début des années 1960 les crédits publics de recherche investis dans ce domaine ont été sensiblement réduits des deux côtés.
Retournons au Luxembourg. La Haute Autorité de la CECA fusionnait en 1965 avec les commissions de la Communauté économique européenne (CEE) créée en 1957, puis en 1967 avec la Communauté européenne de l’énergie atomique (Euratom), sur base du traité de fusion des exécutifs des trois communautés. En janvier 1969 l’Office des publications officielles des Communautés européennes, devenu en 2009 l’Office des publications de l’Union européenne, a été créé et domicilié à Luxembourg. L’Office des publications publie quotidiennement le Journal officiel de l’Union européenne dans les 23 langues officielles de l’Union et propose plusieurs services en ligne destinés et aux professionnels et au grand public du monde entier. Dans son rapport d’activités des années 1975 à 1977, la Direction Générale XIII de la Commission Européenne, en charge de la gestion de l’information et de l’innovation, dont le siège se trouvait également à Luxembourg, annonçait le démarrage d’un projet pilote de traduction automatique avec le logiciel SYSTRAN.
Pendant des dizaines d’années, la DG XIII et l’Office des Publications ont été le moteur de la traduction automatique au Luxembourg.
Systran
Le logiciel SYSTRAN a été développé par Peter Toma, né en juillet 1924 à Doboz, un petit village hongrois. Marqué par les misères de la deuxième guerre mondiale, il était persuadé que les barrières linguistiques constituaient un frein pour garantir la paix. Il voulait y remédier et apprenait le russe et l’anglais, à côté de l’hongrois et de l’allemand. Après avoir immigré aux Etats-Unis en 1952, il a travaillé à partir de 1956 comme assistant à l’Institut de technologie de Californie (Caltech). Lorsqu’un ordinateur Datatron 205 a été installé à l’Institut, il espérait pouvoir réaliser son rêve d’enfant: programmer une machine pour traduire un texte en plusieurs langues. Mais les premières tentatives n’étaient pas concluantes et il quittait le Caltech en 1957. Après quelques expériences auprès de firmes privées, il joignait en mars 1959 l’Université de Georgetown pour participer aux travaux du groupe GAT (General Analysis Technique), rebaptisé dans la suite Georgetown Automatic Translation, sur un ordinateur IBM 705. Le chef de projet était Michael Zarechnak. Il est le coauteur du livre Machine Translation publié en 1979. Peter Toma dirigeait une équipe de programmeurs qui réalisait un projet surnommé SERNA. Quand il quittait l’université en 1961, il présentait SERNA comme son invention, ce qui est contesté par ses pairs de l’époque.
Image extraite du film publicitaire de Systran
Peter Toma a été engagé ensuite par la société Computer Concepts à Los Angeles où il valorisait son savoir-faire pour réaliser les projets AUTOTRAN et TECHNOTRAN qui tournaient sur des ordinateurs IBM 7090. Bien que basée toujours sur des règles algorithmiques, la conception de ces programmes était complètement différente de celle du projet SERNA. En 1964 Peter Toma présentait les systèmes de traduction automatiques à des scientifiques européens à l’Université de Bonn en Allemagne. Le problème était toutefois que l’ordinateur IBM 7090 ne disposait pas de mémoire et de puissance de calcul suffisantes pour traduire plus que des courtes phrases.
Lors du vol vers l’Allemagne, Peter Toma avait lu le manuel d’instruction du nouvel ordinateur 360, annoncé par IBM. D’emblée il était persuadé que cet ordinateur permettait de réaliser vraiment ses rêves et il concevait dans sa tête l’idée comment transformer AUTOTRAN et TECHNOTRAN dans un nouveau produit qu’il nommait SYSTRAN. Comme l’environnement de travail était plus propice en Europe qu’aux Etats-Unis pour progresser avec la traduction automatique, Peter Toma décidait de rester en Allemagne. Il commençait à enseigner la programmation à l’université de Bonn, puis à l’Université de la Sarre. En parallèle, il émulait le fonctionnement de l’ordinateur IBM 360 sur le modèle IBM 7090 pour créer un modèle SYSTRAN embryonnaire. En même temps il s’était inscrit comme étudiant à Bonn où il achevait son doctorat en 1970 avec une thèse sur la traduction automatique.
IBM 360 – Computer History Museum ; Photo : Dave Ross, 2008, CC BY 2.0
Lorsque Heinz Unger, le directeur du département mathématique à l’Université de Bonn, a obtenu les crédits pour l’installation et l’exploitation d’un ordinateur IBM 360 dans son institut, Peter Toma a pu montrer le fonctionnement correct de son système de traduction SYSTRAN. En 1965, la Fondation allemande pour la recherche (DFG: Deutsche Forschungsgesellschaft) avait invité les meilleurs informaticiens et linguistes allemands pour évaluer le projet SYSTRAN. Après une journée de test et de discussions, une bourse de recherche a été accordée à Peter Toma pour parfaire son système.
En 1967, le laboratoire de Rome, le centre de recherche et de développement de la Force aérienne américaine (RADC), lançait un appel d’offre pour la traduction de textes russes en anglais. Le responsable de ce projet était Zbigniew L. Pankowicz (Ziggy), un linguiste polonais et survivant du camp de concentration d’Auschwitz, qui est immigré aux Etat-Unis après la guerre. Il a été admis au temple de la renommé (Hall of Fame) du laboratoire de Rome en 2019. Peter Toma soumettait une offre pour son projet SYSTRAN qui a été retenue par le RADC, parmi des concurrents comme IBM et Thompson Ramo Wooldridge.
Ce succès a incité Peter Toma à créer sa propre société en 1968 pour continuer le développement de SYSTRAN, à La Jolla en Californie, sous le nom de Latsec (Language translation system and electronic communications). D’autres contrats ont été conclus avec des clients américains, par exemple avec la NASA. Avec des hauts et des bas, le projet SYSTRAN a été perfectionné, à Bonn et à La Jolla, jusqu’en 1975 quand Peter Toma a fondé le World Translation Center (WTC) pour gérer les contrats SYSTRAN en dehors des Etats-Unis.
En 1973, le Danemark, l’Irlande et le Royaume-Uni ont adhéré à la Communauté économique européenne. L’introduction de l’anglais comme langue majeure et du danois comme sixième langue officielle posait la Commission Européenne et l’Office des Publications Européennes devant des problèmes monstrueux. Il fallait engager des centaines de traducteurs diplômés additionnels pour gérer le nombre grandissant de documents à publier et à distribuer. C’était le démarrage de l’introduction d’un système de traduction automatique pour les besoins des institutions européennes et le départ pour la mise en service de SYSTRAN au Luxembourg. Il existe deux récits de la manière d’adoption de SYSTRAN. Le premier récit crédite aux institutions européennes le don d’une vue à longue distance en ayant cherché pro-activement un système sur le marché. Le deuxième récit dit que c’était l’initiative de Peter Toma qui cherchait un marché européen pour son produit SYSTRAN. La vérité se trouve probablement au milieu. Il est toutefois établi que Peter Toma présentait en juin 1975 un prototype SYSTRAN anglais-français (développé par sa filiale canadienne WTC-C) à la Commission Européenne à Luxembourg et que celle-ci évaluait un deuxième produit appelé TITUS, conçu par l’Institut Textile de France. Le projet TITUS a été retiré pendant les négociations du fait qu’il ne pouvait pas traduire des textes complets. Comme SYSTRAN pouvait être utilisé sans modification sur un IBM 360, ordinateur que la Commission possédait à cette époque, un premier contrat pour l’utilisation du système SYSTRAN par les institutions européennes a été signé fin 1975 avec WTC. Il portait sur l’adaptation du projet-pilote anglais-français aux besoins de la Commission, et le développement d’un début de système français-anglais. Le chef de projet de la Commission était Loll Rolling, responsable des développements linguistiques et technologiques dans le domaine de l’information à la DG XIII, la direction générale qui gérait également le projet Euronet-Diane à l’époque.
Un des premiers contractants externes de la Commission Européenne pour le projet SYSTRAN était la société Informalux S.A. domiciliée à Rodange. Elle a été constituée en 1977 avec le slogan centre d’énergie informatique. Les actionnaires majoritaires étaient InfoArbed et la Banque Générale, Léonard Siebenaler était le directeur général.
Six traducteurs diplômés des institutions européennes ont été affectés au projet pour assister les informaticiens au développement. Après quelques mois, il ne restait qu’un seul traducteur qui faisait confiance au projet, Ian M. Pigott. Les autres étaient retournés à leurs anciens postes de travail et s’étaient solidarisés avec la majorité des traducteurs et du personnel administratif des institutions européennes qui contestait l’utilité du projet de traduction automatique. Dans la suite Ian M. Pigott a été désigné comme chef de projet SYSTRAN et il contribuait à faire évoluer le système sensiblement. Au début des années 1980 le système permettait de traduire des textes anglais en français et en italien et des textes français en anglais, avec un taux d’erreurs suffisamment bas pour faciliter la tâche des traducteurs humains à produire des traductions avec la qualité voulue. De plus en plus d’employés des institutions européennes commençaient à apprécier cet outil.
Une licence SYSTRAN a été vendu au Japon en 1980, combinée avec la création d’une société locale Systran Corporation. En juin 1982, une société luxembourgeoise Systran International GmbH a été constituée pour commercialiser le système de traduction automatique SYSTRAN. Le registre de commerce et des sociétés luxembourgeois nous renseigne que les 500 parts de la société étaient détenues par le professeur universitaire allemand Helmut Fischer (495 parts) et l’informaticien Cay-Holger Stoll (5 parts), résidant à Gonderange. Ce dernier était membre de l’équipe projet SYSTRAN comme linguiste et figurait comme gérant de la nouvelle société qui a cessé ses activités en 1987.
En 1983, InfoArbed et Informalux ont créé la joint-venture ECAT – European Center for AutomaticTranslation s.à r.l. Chaque actionnaire détenait 2000 parts. En juillet 1984 le capital de cette société a été doublé et les 4000 nouvelles parts ont été souscrites par Systran International GmbH. Après la liquidation de cette société quelques années plus tard, la dénomination sociale de ECAT a été changé en TELECTRONICS s.à r.l. en 1991.
En février 1986, une conférence mondiale SYSTRAN a eu lieu à Luxembourg. Dans l’introduction, Peter Toma racontait pourquoi il avait demandé un faible montant pour la mise à disposition du logiciel SYSTRAN à la Commission Européenne. Il soulignait que son principal objectif était le maintien de la paix et qu’une meilleure communication entre les pays européens, grâce à la traduction automatique, constituait un moyen pour y parvenir. Il annonçait également qu’il avait vendu récemment l’ensemble de ses sociétés et des droits et licences SYSTRAN (à l’exception de la filiale japonaise) à un fabricant de robinets industriels en France, la famille Gachot, qui souhaitait diversifier ses activités. Avec les revenus de cette vente Peter Toma comptait organiser deux projets de taille dans l’intérêt du maintien de la paix. Le premier projet était l’organisation d’un symposium international au sujet de la résolution de conflits prévu le 28 octobre 1986 à l’Université d’Otago en Nouvelle-Zélande. Le deuxième projet était la création de l’université internationale Aorangi privée à Dunedin en Nouvelle-Zélande. Le symposium a effectivement eu lieu, toutefois une année plus tard que révue, du 26.10 au 5.11.1987. Quant à l’université privée, la seule référence que j’ai trouvé est le nom marqué sur le brevet européen accordé à Peter Toma pour son application SYSTRAN. C’est le premier brevet accordé dans le domaine de la traduction automatique. En 1997, on retrouve Peter Toma avec une contribution My First 30 Years with MT où il figure comme président de Voxtran Inc, avec une adresse en Allemagne. Il est décédé en 2010, la même année où la mise hors service de SYSTRAN auprès des institutions européennes a eu lieu.
Il est temps de retourner en Europe. En 1986, le siège sociale de Systran a été transféré à Paris et la gestion de la société mère Systran S.A. a été assurée par Jean Gachot. Son fils Denis Gachot était déménagé en Californie pour diriger les filiales Latsec et WTC à La Jolla. En 1989, Denis Gachot a présenté The SYSTRAN Renaissance avec l’annonce de plusieurs nouveautés, entre autres des versions SYSTRAN pour PC, la location du logiciel SYSTRAN, l’accès à distance par Telenet et même un accès Minitel pour le grand public en France.
Traduction automatique en ligne sur Minitel proposée par Gachot
Malgré ces innovations, la réussite financière n’était pas au rendez-vous pour la famille Gachot. En 1993 les activités SYSTRAN ont été cédées à quelques anciens actionnaires minoritaires, parmi eux Dimitrios Sabatakakis qui dans la suite a dirigé le groupe Systran pendant vingt ans.
En 1996 l’équipe de développement et de maintenance SYSTRAN à Luxembourg, composée de linguistes, traducteurs et informaticiens, était passée de deux personnes à une quarantaine. La Commission Européenne planifiait de confier l’exploitation du système au Centre de traduction des organes de l’Union Européenne (CdT) qui a été établi à Luxembourg en 1994. Le CdT n’est pas attaché à la Direction Générale Traduction de la Commission Européenne, mais il dispose de sa propre personnalité juridique. Dans ce contexte le député européen Ben Fayot avait posé la question écrite E-2286/96 à la Commission au sujet de l’obligation morale d’incorporer l’équipe SYSTRAN dans le CdT. La Commission précisait que le personnel était mis à disposition par des firmes privées depuis vingt ans, sous contrats temporaires renouvelés, et que le recrutement d’agents relevait de la seule compétence du CdT.
En mars 1996, une société TELINGUA s.à r.l. a été constituée par Telindus, probablement dans le contexte du remaniement des contrats par les institutions européennes. En septembre 1997 cette société a été convertie en société anonyme Systran Luxembourg par les actionnaires Systran S.A. France (250 parts), Telindus (175 parts), Norbert von Kunitzki (50 parts) et Piere Musman (25 parts). Le contrat SYSTRAN avec la Commission Européenne a été cédé à Systran Luxembourg.
Au niveau international, le groupe Systran avait réussi à décrocher des contrats auprès de plusieurs clients prestigieux comme la NASA, Ford, Price Waterhouse Coopers, Xerox. En décembre 1997, Digital Equipment Corporation et Systran S.A. avaient lancé le premier service de traduction automatique sur le web, AltaVista Translation Service, au surnom de Babelfish. Les langues française, allemande, italienne, espagnole, portugaise et anglaise ont été supportés. Jusqu’en 2007 le service Google Translate était également basé sur le système SYSTRAN.
Au Luxembourg les sociétés Informalux S.A. et Telectronics s.à r.l. ont fusionné en 2001 la nouvelle entité a été dénommée TELECTRONICS S.A. Elle est restée active pendant presque vingt ans et a été absorbée par Proximus Luxembourg S.A. en 2020.
En 2004 Pierre Musman est sorti du Conseil d’Administration de Systran Luxembourg S.A. et Norbert Kunitzki est décédé en 2005 suite à une chute dans les montagnes. A partir de ce moment Systran Luxembourg a été administré uniquement par Denis Gachot et par Dimitrios Sabatakakis (PDG de Systran S.A France). Guillaume Naigeon de Systran S.A France assurait la fonction de commissaire aux comptes.
En 2013 la société coréenne SLCI a lancé avec succès une offre publique d’achat (OPA) pour acquérir Systran. Avec l’obtention de 85% des actions de Systran par SLCI, l’acquisition a été conclue à Seoul en mai 2014. Les administrateurs français ont quitté la société Systran Luxembourg S.A. et ont été remplacés par les administrateurs coréens Ji Changjin, Kim Dong Pil et Park Ki-Hyun.
Dimitrios Sabatakakis et Park Ki-Hyun à la conférence de presse à Seoul en 2014
Pendant une année Chang-Jin Ji et Guillaume Naigeon assuraient l’intérim de PDG. En juillet 2015, Jean Senelart, un ingénieur et informaticien linguistique de renom, a pris les rênes du groupe Systran. Il avait rejoint Systran en 1999, d’abord comme chef de projet, ensuite comme directeur des équipes R&D, avec lesquelles il avait lancé quatre générations de produits SYSTRAN. En 2008 il est devenu Chief Scientist et en 2014 Global CTO du groupe. Mais le jeu des chaises musicales n’était pas encore fini. En août 2020, la majorité des actions du groupe Systran a été achetée par un consortium d’investisseurs institutionnels coréens: STIC Investments, SoftBank Korea, Korea Investment Partners et Korea Investment Securities. La présidence et direction du groupe ont été confiées en mai 2022 à Vincent Godard. De formation ingénieur, il avait occupé le poste de Directeur Commercial de 2009 à 2013 auprès de Systran, ce qui facilitait sa prise de fonction. Jean Senelart continue de siéger au Conseil d’administration de Systran en tant que conseiller scientifique.
En 2022 Systran Luxembourg S.A. est administrée complètement par Systran S.A. France, le commissaire aux comptes est la société luxembourgeoise F.C.G. S.A. La filiale luxembourgeoise et la maison mère semblent se porter bien. Systran est toujours considéré comme pionnier et leader du marché de la traduction automatique, avec des technologies basées sur l’intelligence artificielle très innovantes.
page d’accueil sur le site web de Systran
Litige Systran – Commission Européenne
Une épisode dans l’histoire farfelue de Systran au Luxembourg s’est déroulée en dehors des activités techniques et commerciales et mérite d’être racontée. Comme les institutions européennes ne pouvaient pas conclure des contrats de longue durée avec des firmes privées pour la mise à disposition de personnel spécialisé en linguistique et en informatique, ces spécialistes ont été transférés tous les quelques années à une autre entreprise qui signait un nouveau contrat. Comme le groupe Systran faisait partie d’une façon ou d’une autre de ces différents contractants, il y avait toujours moyen de régler des problèmes éventuels au niveau des licences SYSTRAN.
Tout changeait lors d’un appel d’offre lancé en octobre 2003 par les institutions européennes sans la prise en compte des intérêts du groupe Systran. L’appel d’offres at été remporté par la société luxembourgeoise Gosselies S.A. qui n’avait aucune expertise en matière de linguistique informatique. La société anonyme Gosselies a été constituée en 1994 et liquidée en 2011. Dans un article du Lëtzebuerger Land du 23.12.2010, la journaliste Sophie Mosca estimait que le fait que le ministre luxembourgeois de l’Économie de l’époque, Henri Grethen, était actionnaire de Gosselies et que son épouse assurait la gestion, avait pesé dans ce choix. Ce contrat a incité la société Systran S.A. France et sa filiale luxembourgeoise à déposer de suite une plainte pour violation des droits d’auteur contre la Commission Européenne. Ce n’est qu’en janvier 2007 que le groupe Systran a réussi à introduire une action en réparation devant la Cour de Justice Européenne. Et il fallait attendre presque 3 ans jusqu’à la réception d’une réponse. Le 16 décembre 2010 le Tribunal de l’union européenne a condamné la Commission à verser au groupe Systran une indemnité forfaitaire de 12 001 000 euros. C’était une première. Le PDG de Systran Dimitrios Sabatakakis s’est félicité et tirait son chapeau à la justice européenne. Mais il s’était réjoui trop tôt. Deux mois plus tard la Commission Européenne a introduit un pourvoi dans ce litige. Et comme les rouages de la justice sont lents, ce n’est que le 18 avril 2013 que la Cours de Justice européenne a annulé son jugement antérieur et qu’elle a renvoyé l’affaire devant les tribunaux nationaux.
Il semble que dans la suite un arrangement à l’amiable a été négocié en 2017 entre les institutions européennes et le groupe Systran et qu’une somme de quelques millions euros a été versée à Systran comme dédommagement. Cette transaction était à l’origine d’un autre procès judiciaire, cette fois entre la société coréenne SLCI et les anciens actionnaires de Systran. Les conditions de l’OPA, finalisée en 2014, stipulaient que SLCI devait reverser aux vendeurs des actions une partie d’une éventuelle indemnisation par la Commission Européenne. Comme SLCI, respectivement ses héritiers, avaient manqué à cette obligation, l’affaire s’est terminée devant les tribunaux. Le complément de prix dû aux anciens actionnaires a été payé en mars 2020.
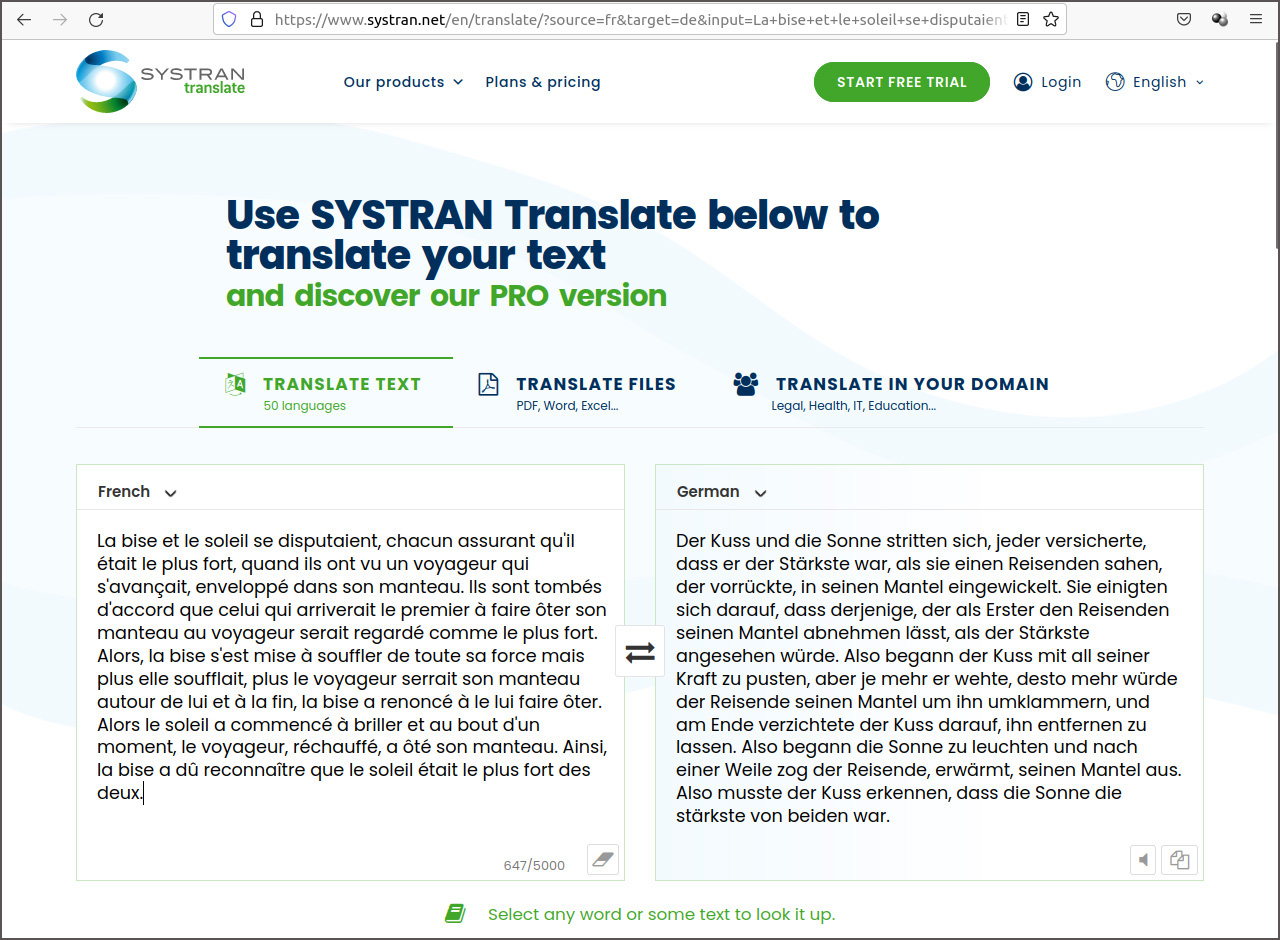
Cette épisode termine mon récit sur l’histoire de Systran durant un demi-siècle. Dans les prochains chapitres nous allons découvrir les autres projets de traduction automatique qui touchent le Luxembourg et qui ont également une histoire passionnante. Il reste à souligner que même en 2022 Systran continue à traduire bise en Kuss au lieu de Nordwind.
Traduction en temps réel sur la plateforme SYSTRAN Translate en 2022
EUROTRA
Lors de la mise en place de SYSTRAN en 1976, il n’y avait pas seulement de la résistance auprès du personne des services de traduction des institutions européennes, mais également beaucoup de critiques de la part de linguistes dans les universités en Europe qui reprochaient à la Commission Européenne d’acheter un produit américain au lieu de promouvoir le savoir-faire européen. Le directeur général de la DG XIII, Raymond Appleyard, et le directeur responsable pour la gestion de l’information à la DG XIII, Georges J. Anderla, étaient sensibles à ces arguments et proposaient le lancement d’un projet européen de traduction automatique, tout en continuant à supporter la solution pragmatique SYSTRAN. Le projet, appelé EUROTRA, n’a été approuvé qu’en 1982 par le Conseil Européen et par le Parlement Européen et il n’a démarré qu’en 1985. Malgré un investissement de 70 millions euros pendant 10 ans, le système n’est jamais devenu opérationnel. Bryan Oakley a expliqué les raisons de cet échec dans sa contributionTo Do the Right Thing for the Wrong Reason; the EUROTRA Experience.
MT@EC
Le nombre de paires de langues supportées par SYSTRAN ne cessait de croître, mais le travail lexicographique sous-jacent rendait difficile l’extension de la couverture aux nouvelles langues résultant des élargissements successifs de l’Union européenne. En décembre 2010 le système SYSTRAN a été arrêté et remplacé en 2013 par MT@EC, un système de traduction automatique basé sur les statistiques et exploitant les énormes corpus bilingues et multilingues des institutions européennes tels qu’Euramis. S’appuyant sur le système à source ouverte Moses, développé à l’Université d’Edimbourg, MT@EC supportait en 2016 plus que 500 paires de langues, avec des degrés divers de fiabilité et de qualité. Mais la durée de vie du projet MT@EC était largement inférieure à celle de SYSTRAN, le système a été rapidement remplacé par eTranslation.
eTranslation
Comme la technologie de l’intelligence artificielle se développait à un rythme stupéfiant, la méthode de traduction automatique fut surpassée par une nouvelle méthode dès 2017. La traduction automatique neuronale était arrivée, rendue possible par les progrès en matière de puissance de calcul faisant sortir l’intelligence artificielle des laboratoires. Cette nouvelle technologie exigeait encore davantage de puissance de calcul, et plus spécifiquement, des processeurs graphiques. Testé depuis 2019, un nouveau service en ligne appelé eTranslation a été ouvert en mars 2020, non seulement pour les institutions européennes, mais également pour les entreprises européennes et pour des professionnels, et ceci à titre gratuit. Markus Foti est le responsable de ce projet.
J’ai testé le service eTranslate avec la traduction française-allemande de la phrase “La bise et le soleil …”. eTranslate propose 3 termes différents pour traduire la bise en fonction du contexte: der Kuss, die Knie et der Bise. Le modèle de traduction utilisé pour eTranslate ne semble donc pas encore être à la hauteur de ses compères Google, Facebook ou IBM. Une copie écran et le texte traduit complet sont affichés ci-après:
Traduction de la fable “La bise et le soleil …” par eTranslation
Der Kuss und die Sonne stritten, und jeder versicherte, er sei der Stärkste, als sie einen Reisenden sahen, der in seinem Mantel vorrückte. Sie waren sich einig, dass derjenige, der es als Erster schafft, dem Reisenden seinen Mantel ausziehen zu lassen, als der Stärkste angesehen wird. So begann der Kuss mit seiner ganzen Kraft zu blasen, aber je mehr sie wehte, desto mehr würde der Reisende seinen Mantel um ihn spannen, und am Ende verzichtete die Knie darauf, ihn zu entfernen. Dann fing die Sonne an zu leuchten und nach einer Weile zog der Reisende, der erwärmte, seinen Mantel aus. So musste der Bise erkennen, dass die Sonne die stärkste von beiden war.
Si vous souhaitez traduire des textes étrangers en luxembourgeois, c’est en vain. La langue luxembourgeosie n’est pas encore supporté. Il faut s’adresser à Google Translate.
Google Translate
Le service de traduction en ligne Google Translate a été lancé en avril 2006. Il était d’abord basé sur la technologie SYSTRAN. En octobre 2007 Google a remplacé SYSTRAN par sa propre technologie de traduction automatique statistique, supportant 25 languages. En janvier 2010 Google a introduit une version mobile pour Android, une année plus tard une application pour iOS.
Une application de réalité virtuelle pour traduire des mots ou textes, photographiés avec un smartphone ou une tablette, appelée Word Lense, a été intégrée dans Google Translate suite à l’acquisition par Google en mai 2014 de la startup américaine Quest Visual qui avait développé ce système.
En février 2016 Google avait ajouté 13 langues additionnelles à son service Google Translate, dont le luxembourgeois, pour supporter alors un total de 103 langues. Au début ce n’était pas parfait, par exemple Lëtzebuerg ass mei Land a été traduit en Irland ist mein Land.
En novembre 2016 Google a introduit la version neuronale Google Neural Machine Translation (GNMT) de son service de traduction automatique pour 40 langues. GNMT fait partie du projet Google Brain, lancé en 2011 par Jeff Dean et Greg Corrado des laboratoires de recherche Google X et par Andrew Yan-Tak Ng de l’université de Stanford. En août 2017 le nouveau système a été étendu aux autres langues et le support du luxembourgeois a été bien amélioré.
La traduction de la fable “La bise et le soleil avec Google Translate” est sans fautes
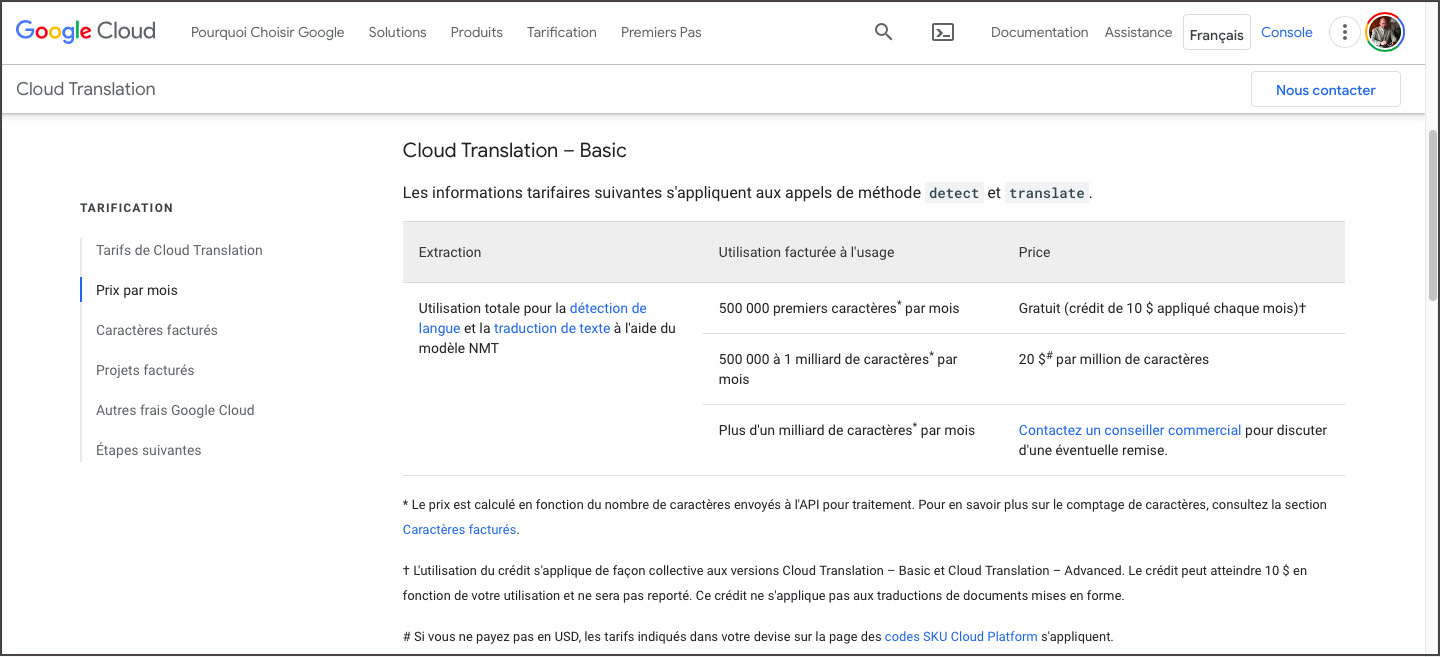
Le service Google Translate est gratuit pour des traductions en ligne de textes courts, mais c’est un service payant qui fait partie des produits Google Cloud pour des traductions de taille.
Prix du service Google Translate Basic
Quelques développeurs indépendants de Google publient sur la plateforme Github des logiciels permettant la traduction gratuite de documents volumineux, en contournant les barrières et restrictions intégrées dans les interfaces publics de Google Translate. Deux exemples sont les projets google-translate-php et google-trans-new.
Mon conseil est de ne pas recourir à de telles solutions qui ne sont pas fiables, illégales et qui portent le risque de voir son adresse IP bloquée par Google pour tous ses services proposés, y inclus la recherche sur le web. Il vaut mieux de passer son temps à explorer des services de traduction amusants comme Fabricius, le service en ligne de Google pour déchiffrer des hiéroglyphes. Cette application fait partie de l’espace dédié à l’Égypte ancienne au sein de sa section Google Arts & Culture, dévoilé le 15 juillet 2020 pour célébrer l’anniversaire de la découverte de la Pierre de Rosette.
Yandex Translate
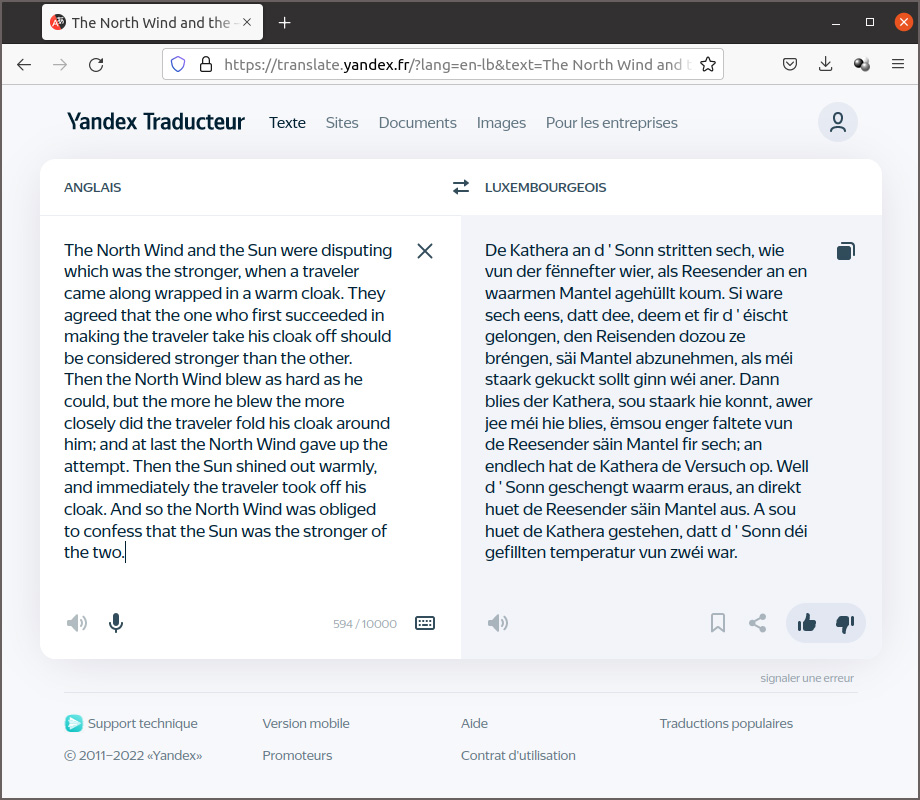
Les internautes en Russie et dans différents autres pays de l’Est préfèrent utiliser Yandex Translate au lieu de Google Translate. Le service est intégré dans le moteur de recherche de même nom créé en 1997 par Arkadi Voloj. Yandex est une socitété russe dont la maison mère est basée à Amsterdam. Yandex Translate utilise un système statistique de traduction automatique par auto-apprentissage. Ce qui surprend c’est que le service supporte la langue luxembourgeoise. Les résultats de la traduction anglais-luxembourgeois de la fable d’Esope, affichés ci-après, montrent que la qualité de la traduction n’est pas très élevée.
Dans les prochains chapitres nous allons découvrir les projets de traduction automatique à source ouverte de Systran (OpenNMT), de Microsoft (MarianNMT, de Facebook (NLLB), d’Amazon (Sockeye) et de Google (T5, mt5) .
OpenNMT
OpenNMT est le projet de traduction automatique à source ouverte le plus ancien. Yoon Kim, membre du groupe NLP de l’université de Harvard, a lancé en juin 2016 le projet seq2seq-attn sur Github qui est à l’origine du projet. Yoon Kim est aujourd’hui maître assistant au MIT. En collaboration avec Systran, un premier modèle OpenNMT a été publié en décembre 2016. L’auteur principal était Guillaume Klein de Systran. Une première version OpenNMT pour PyTorch a été publiée en mars 2017 (OpenNMT-py), en collaboration avec Facebook Research. Une version pour TensorFlow suivait en juin 2017 (OpenNMT-tf). Le projet OpenNMT est actuellement maintenu par Systran et Ubiqus. L’ancien PDG de Systran, Jean Senellart, est un des administrateurs du forum OpenNMT.
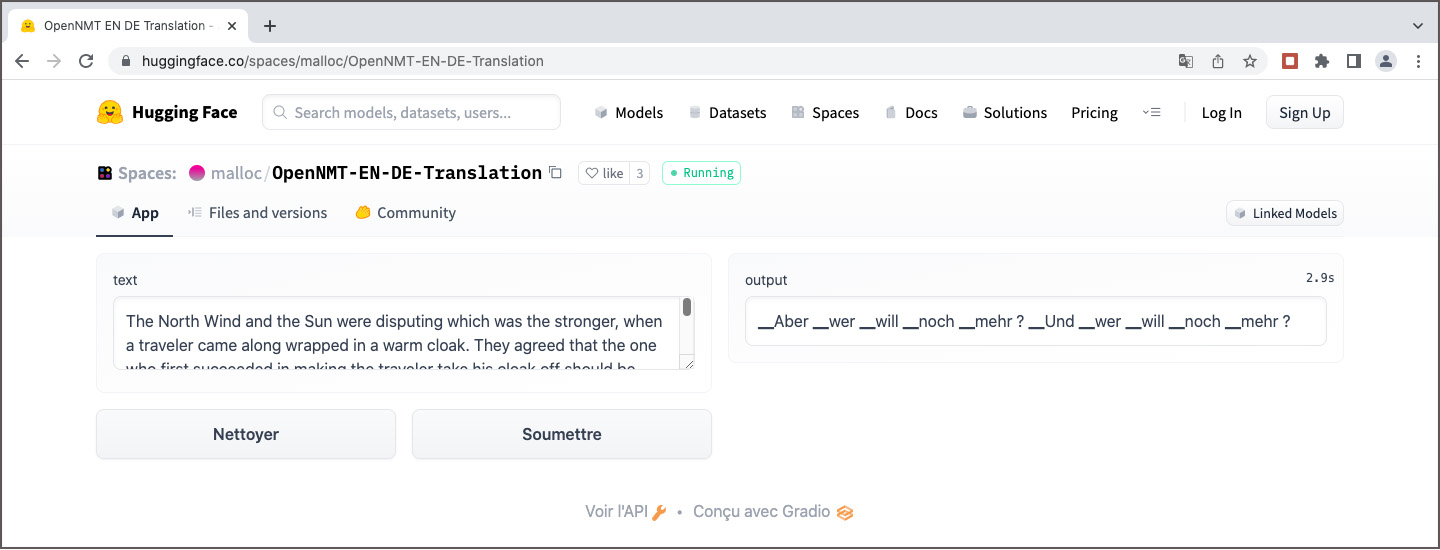
Des modèles de traduction pré-entraînés pour OpenNMT sont rares. Sur le site web OpenNMT on trouve seulement deux modèles : un modèle Transformer anglais-allemand et un modèle BiLSTM allemand-anglais. Le premier est disponible sur la plateforme huggingface.co comme espace de démonstration. J’ai essayé de l’évaluer, mais sans succès. Il semble que le fichier de configuration manque, ce qui peut expliquer la traduction farfelue.
Traduction farfelue anglais-allemand avec OpenNMT sur Huggingface
MarianNMT
MarianNMT est un outil neuronal de traduction automatique entièrement programmé en C++. Pour cette raison il est deux fois plus rapide que OpenNMT si on effectue des tests dans les mêmes conditions. Le projet a été développé à l’Université d’Edimbourg et à l’Université Adam Mickiewicz à Poznań en Pologne, en collaboration avec Microsoft, à partir de 2017.
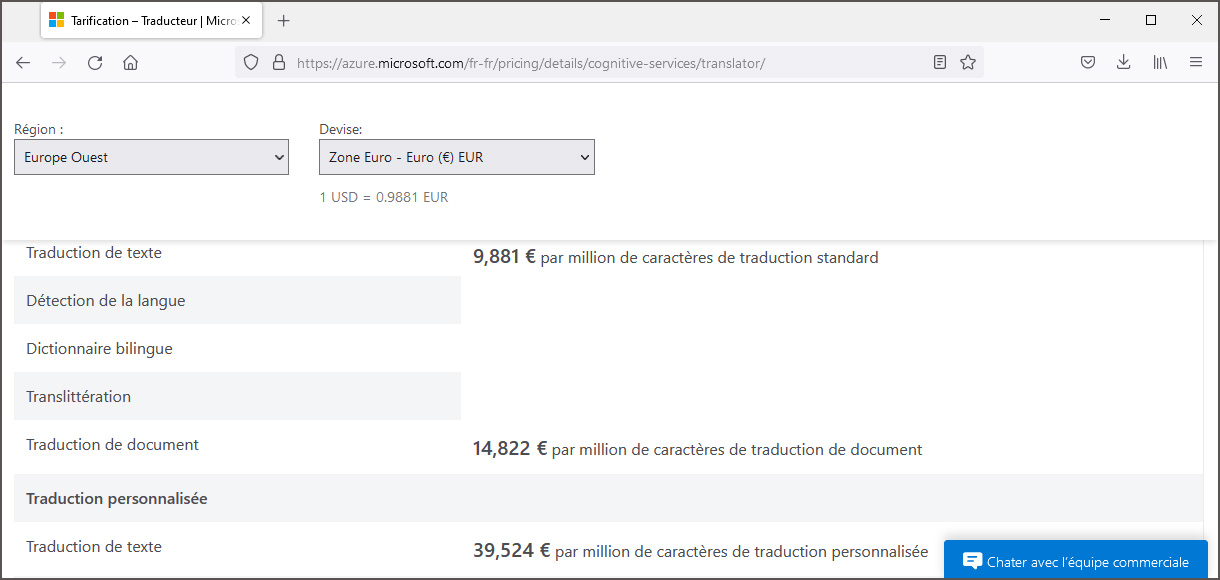
Le chef de projet était Marcin Junczys-Dowmunt, actuellement scientifique NLP principal auprès de Microsoft. Il est né à Bydgoszcz en Pologne, la ville natale de Marian Rejewski, un mathématicien et cryptologue polonais renommé. En hommage à ce scientifique, Marcin Junczys-Dowmunt a utilisé son prénom comme nom de travail du projet et le nom n’a jamais été changé. La technologie Marian est utilisée par Microsoft pour son service de traduction commercial Microsoft-Translator sur la plateforme Azure. A l’exemple de Google, une version légère est intégrée sans le moteur de recherche Bing de Microsoft pour traduire gratuitement des textes courts. Mais la langue luxembourgeoise n’est pas supportée par Microsoft.
prix de Microsoft pour la traduction sur la plateforme Azure
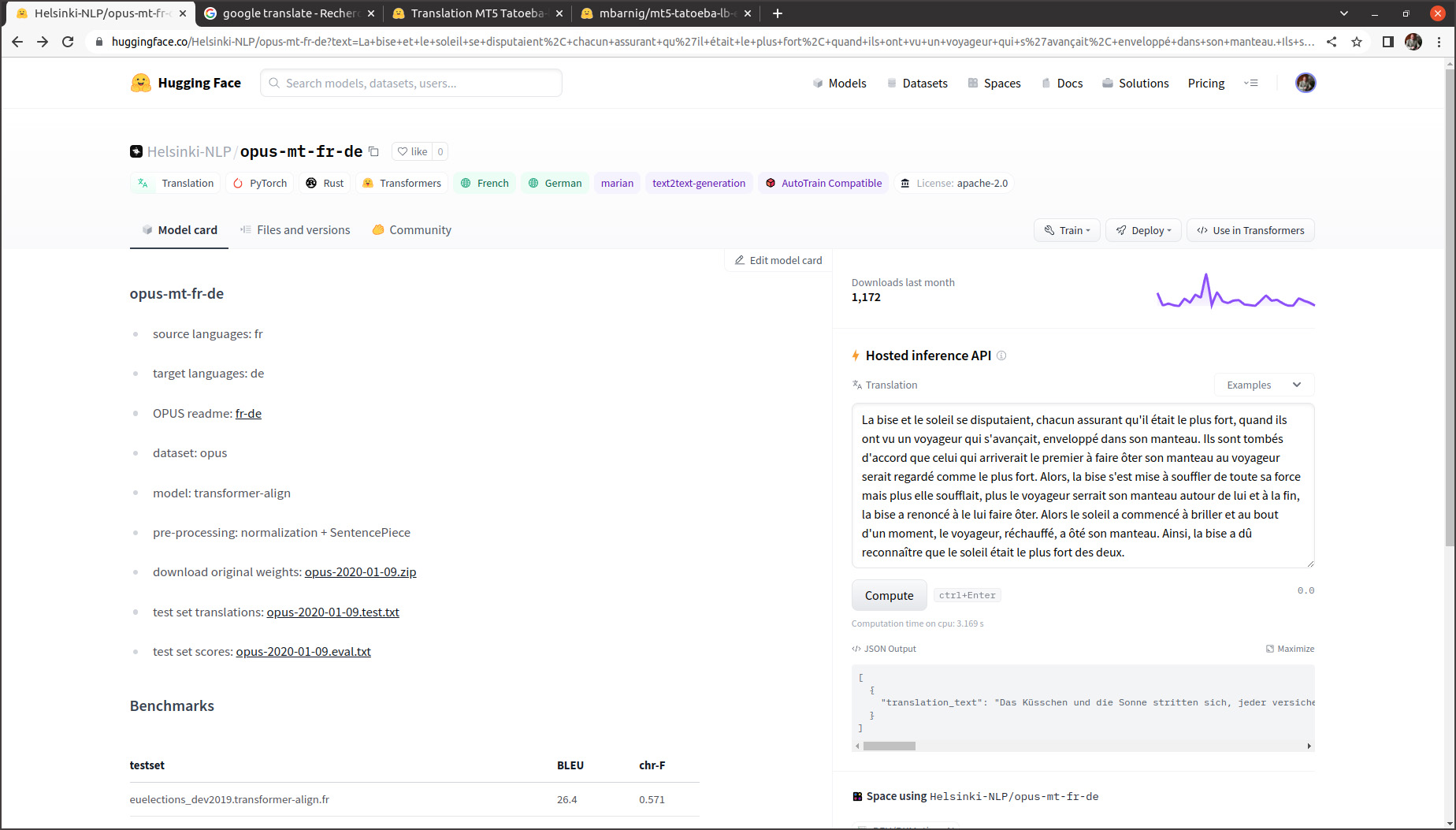
Une multitude de modèles de traduction pour différentes paires de langues a été publiée par l’Université d’Helsinki sous l’initiative de Jörg Tiedemann, professeur des technologies de language au département des humanités numériques (HELDIG). Ces modèles neuronaux sont connus sous les noms de Helsinki-NLP/opus-mt-xx-yy (xx = langue source, yy = langue cible). Ils ont été entraînés avec les données du corpus public ouvert OPUS, respectivement avec les données de la collection Tatoeba. Sur Huggingface 1.466 modèles sont disponibles, parmi eux le modèle opus-mt-fr-de qui est à l’origine du titre de la présente publication.
Présentation des modèles Helsinki-NLP/opus-mt-xx-yy sur Huggingface
Dans la liste des modèles MarianMT entraînés moyennant le corpus Tatoeba luxembourgeois on trouve un modéle anglais-luxembourgeois et un modèle luxembourgeois-anglais. Après conversion en format PyTorch, j’ai téléchargé les fichiers afférents comme bases de données et comme modèles sur la plateforme Huggingface. J’ai programmé en outre une application pour un espace de démonstration. Hélas le corpus Tatoeba luxembourgeois n’a ni la taille ni la qualité pour obtenir des résultats de traduction valables. Dans l’attente de la découverte d’une base de données plus appropriée pour pouvoir entraîner un meilleur modèle de traduction anglais-luxembourgeois, et éventuellement des modèles luxembourgeois avec d’autres langues comme source ou cible, je laisse la présente version en place sur Huggingface comme preuve de concept.
NLLB (No Language Left Behind)
Précédé par son modèle pytorch/translate, Facebook Research a présenté en 2019 son outil de modélisation de séquences fairseq en source ouverte qui permet, entre autres, de faire de la traduction automatique. A l’instar de OpenNMT et de MarianNMT, des modèles de traduction automatique pré-entraînés pour quelques couples de langues ont été mis à la disposition des chercheurs.
En octobre 2021 Facebook Inc., la maison mère des services Facebook, Instagram, WhatsApp et Messenger, a changé son nom en Meta Platforms Inc. et Facebook AI est devenu Meta AI. Récemment, le 6 juillet 2022, Meta AI a annoncé la mise au point du premier modèle d’intelligence artificielle unique qui permet la traduction en 200 langues différentes avec une qualité de pointe. Ce modèle, appelé NLLB-200, fait partie de l’initiative No Language Left Behind de Meta. Une publication détaillée de 190 pages sur le projet est disponible sur arXiv.
Le modèle NLLB-200 est disponible en plusieurs versions, avec des tailles allant de 4,4 GB (600 millionsde paramètres) jusqu’à 404 GB (54,5 milliards de paramètres. Pour tester NLLB, on a plusieurs possibilités :
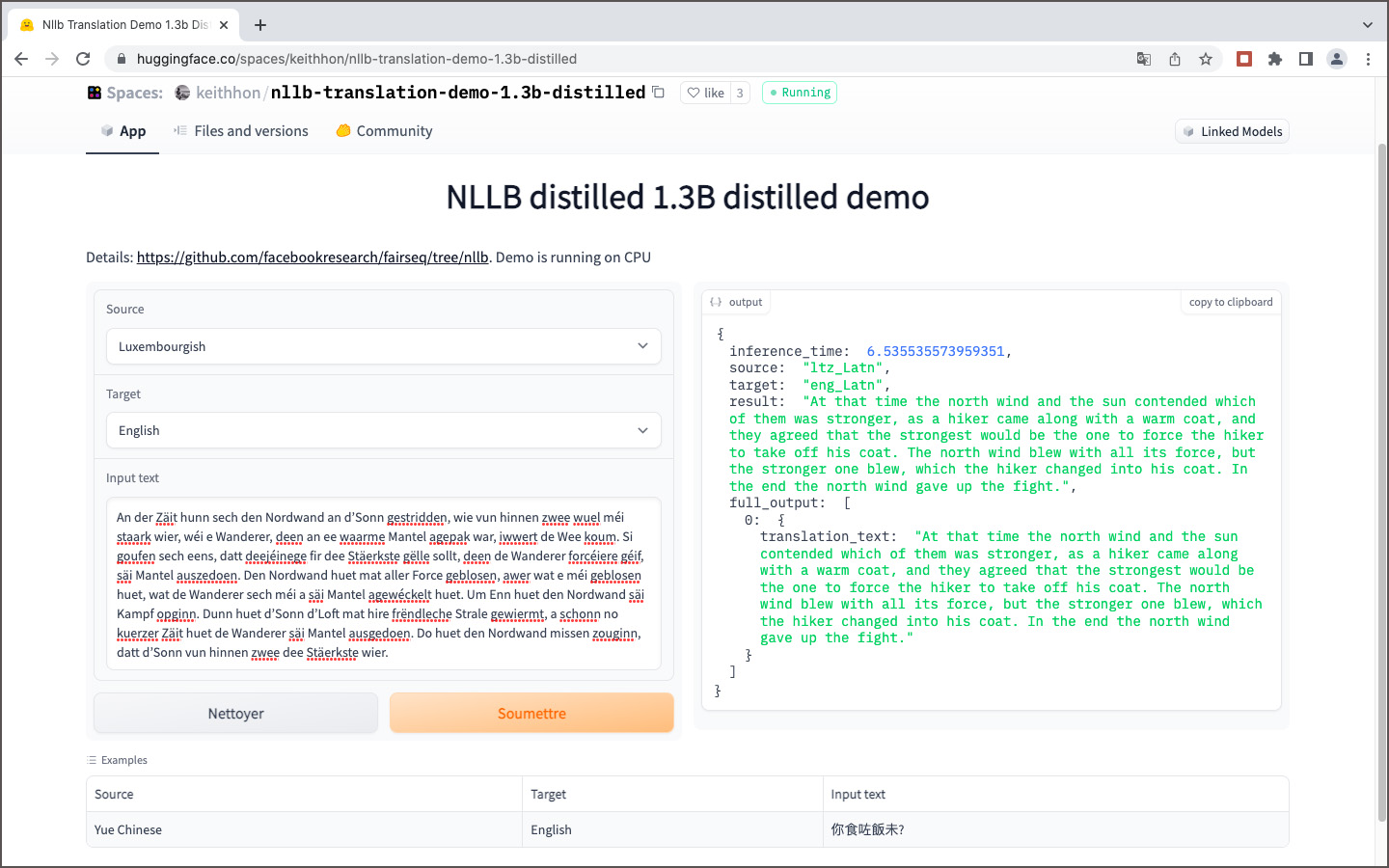
Traduction en temps réel luxembourgeois – anglais avec NLLB sur Huggingface
Le code Python pour traduire un texte anglais en luxembourgeois avec la librairie Transformers de Huggingface est montré ci-après comme exemple:
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-200-distilled-600M", use_auth_token=False, src_lang="eng_Latn")
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-200-distilled-600M", use_auth_token=False)
article = "The North Wind and the Sun were disputing which was the stronger, when a traveler came along wrapped in a warm cloak."
inputs = tokenizer(article, return_tensors="pt")
translated_tokens = model.generate(**inputs, forced_bos_token_id=tokenizer.lang_code_to_id["ltz_Latn"], max_length=100)
tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
Exécution du code Python pour la traduction anglais – luxembourgeois. Cliquez pour agrandir l’image.
Amazon Translate et Sockeye
Le service de traduction automatique commercial de Amazon repose également sur un projet à source ouverte, appelé Sockeye, disponible sur Github. Les origines du projet remontent à 2017; plus que 70 versions ont été publiées depuis, la version la plus récente ( 3.1.14.) date du 5 mai 2022. Si on passe le test de La bise et le soleil se disputaient … au traducteur Amazon Translate, on s’étonne que la traduction allemande Der Nordwind und die Sonne stritten sich … est correcte. Mais à la deuxième vue on découvre que dans les autres phrases la bise devient der Kuss comme dans la majorité des autres systèmes de traduction.
Traduction en temps réel français – allemand avec Amazon Translate
En été 2022 la langue luxembourgeoise n’était pas encore supportée par Amazon Translate.
Google T5 et mt5
Les premiers modèles neuronaux entraînés pour la traduction automatique étaient basés sur une architecture de réseau de neurones récurrents. Tout a changé en juin 2017 lorsque Google a présenté une nouvelle architecture de réseau neuronal, appelée Transformeur, dans sa publication Attention is All You Need. D’un jour à l’autre les transformeurs, qui sont conçus pour gérer des données séquentielles telles que le langage naturel, sont devenus le modèle de choix pour la traduction automatique. Cela a conduit au développement de systèmes pré-entraînés tels que BERT (Bidirectional Encoder Representations from Transformers) par Google et GPT-1 (Generative Pre-Training Transformer) par OpenAI en 2018.
Fin 2019 Google a introduit son transformeur T5, pré-entraîné avec un vaste ensemble de données C4 (Colossal Clean Crawled Corpus), publié ensemble avec le modèle. Le modèle T5 supporte 4 langues (anglais, allemand, français et roumain) et existe en cinq versions:
T5-Small (60 millions de paramètres)
T5-Base (220 millions de paramètres)
T5-Large (770 millions de paramètres)
T5-3B (3 milliards de paramètres)
T5-11B (11 milliards de paramètres)
Même si l’application principale du modèle T5 n’est pas la traduction, celle-ci fonctionne entre les quatre langues supportées. Une démonstration de traduction de textes anglais en allemand ou en français est accessible sur Huggingface.
Traduction en temps réel anglais-allemand et anglais-français avec le modèle T5 sur Huggingface
Un modèle multilingue mt5 supportant 101 langues, dont le luxembourgeois, a été présenté par Goggle une année après le modèle T5, en octobre 2020. Comme le modèle mt5 nécessite un réglage fin (finetuning) avant de pouvoir servir pour des applications de traitement du langage, comme la traduction automatique, Shivanand Roy a développé l’outil simpleT5 qui facilite l’entraînement du modèle pour une langue, ou pour un couple de langues déterminées. Un autre chercheur, Thilina Rajapakse, a développé un outil similaire appelé simpletransformers. L’auteur a mis en place un site web dédié pour SimpleTransformers et a publié la contribution How to Train an mT5 Model for Translation With Simple Transformers qui explique comment entraîner le modèle mt5 pour la traduction automatique du paire des langues anglais – cingalais.
Comme le réglage fin des modèles T5 et mt5 nécessitent des puissance de calcul et des tailles de mémoire très élevées, typiquement une TPU (Tensor Processing Unit) comme accélérateur sur Google Colab, je me suis limité à l’entraînement du modéle mt5-small qui a une taille de 1,2 GB. J’ai utilisé le corpus Tatoeba anglais-luxembourgeois pour la formation avecl le script Python affiché ci-après:
Le graphique enregistré sur la plateforme Weights & Biases qui suit montre l’évolution des scalaires pendant l’entraînement dont l’objectif principal est de minimiser les pertes.
On constate que le coefficient de perte train est au début en baisse pour ensuite inverser sa pente, tandis que le coefficient de perte eval augmente continuellement, ce qui signifie qu’il y a un overfitting du modèle du fait que la taille du fichier d’entraînement est trop petit. Cela se confirme si on examine les résultats de la traduction dans mon espace de démonstration sur Huggingface. J’ai programmé une application commune pour comparer les résultats de la traduction anglais-luxembourgeois et vice-versa avec les trois modèles NLLB, MarianNMT et T5/mt5.
En entrant les mêmes textes dans l’application Goggle Translate, on se rend compte de la performance supérieure de ce modèle dont le code est fermé et propriétaire.
Métriques
Dans les chapitres précédents nous avons procédé à une évaluation subjective de la qualité de traduction des différents modèles basés sur l’intelligence artificielle. Il existe toutefois de nombreuses métriques pour procéder à une évaluation objective. Quelques exemples sont relevés ci-après :
Pour exprimer la qualité d’une traduction automatique, on mesure la différence entre la traduction machine et une, ou plusieurs, traductions de référence créées par l’humain pour une même phrase source. Il faut donc disposer d’un corpus de phrases pour la langue source et pour la langue cible. Facebook a publié récemment sur Github un corpus public de référence appelé Flores-200. Il se compose d’un fichier csv pour chacune des 200 langues supportées par le modèle NLLB. Chaque fichier inclut 998 phrases présentées dans le même ordre, ce qui permet d’automatiser aisément l’évaluation d’un nouveau modèle de traduction machine pour un couple de langues déterminées. Les trois premières phrases en anglais et en luxembourgeois du corpus Flores-200 sont affichées ci-après à titre d’exemple.
On Monday, scientists from the Stanford University School of Medicine announced the invention of a new diagnostic tool that can sort cells by type: a tiny printable chip that can be manufactured using standard inkjet printers for possibly about one U.S. cent each.
Lead researchers say this may bring early detection of cancer, tuberculosis, HIV and malaria to patients in low-income countries, where the survival rates for illnesses such as breast cancer can be half those of richer countries.
The JAS 39C Gripen crashed onto a runway at around 9:30 am local time (0230 UTC) and exploded, closing the airport to commercial flights.
……………..
E Méindeg hu Wëssenschaftler vun der Stanford University School of Medicine d’Erfindung vun engem neien Diagnosgeschier ugekënnegt, dat Zellen no Typ sortéiere kann: e klengen dréckbaren Chip, dee mat Hëllef vun engem Standardtëntestraldrécker fir méiglecherweis ongeféier een US-Cent d’Stéck hiergestallt ka ginn.
Féierend Fuerscher soen, datt dëst d’Fréierkennung vu Kriibs, Tuberkulos, HIV a Malaria bei Patienten a Länner mat nidderegem Akommes brénge kéint, wou d’Iwwerliewenstauxe bei Krankheeten ewéi Broschtkriibs hallef esou héich kënne sinn ewéi a méi räiche Länner.
D’JAS 39C Gripen ass géint 9.30 Auer Lokalzäit (0230 UTC) op eng Rullbunn gestierzt an explodéiert, wouduerch de Flughafe fir kommerziell Flich gespaart gouf.
……………..
Trois premières phrases du corpus Flores-200 anglais et luxembourgeois
Après la comparaison des résultats, un score est attribué pour chaque phrase traduite. Puis une moyenne est calculée sur l’ensemble du corpus afin d’estimer la qualité globale du texte traduit. Parmi la multitude des métriques d’évaluation MT, BLEU constitue la métrique la plus populaire et la moins coûteuse. Elle a été développée en 2002 par Kishore Papineni pour IBM. La formule mathématique pour générer les scores se base sur des unigrammes, bigrammes, trigrammes et quadrigammes (n-grammes), mais je vais vous épargner les explications afférentes qui dépassent le cadre de la présente description. Je me limite à présenter quelques résultats représentatifs extraits des métriques pour la traduction automatique des 200 x 200 couples de langues supportés par les modèles NLLB. Les scores afférents sont exprimés avec la métrique chrf++ qui fournit des évaluations plus pertinentes que la métrique BLEU.
Direction Traduction
Métrique chrf++
en -> de
62,8
en -> fr
69,7
en -> lb
56
de -> en
67,5
de -> fr
61,4
de -> lb
52
fr -> en
68,4
fr -> de
56,3
fr -> lb
49,6
lb -> en
69,6
lb -> de
60,1
lb -> fr
62,4
lb -> zho
12,9
lb -> ja
24,6
Métriques mesurées avec corpus Flores pour modèle de traduction automatqiue NLLB
La meilleure qualité a été calculée pour la traduction luxembourgeois – anglais (chrf++ = 69,6), la plus basse pour la traduction luxembourgeois – chinois (chrf++ = 12,9).
Conclusions
J’utilise la traduction automatique depuis plus de 10 ans dans le cadre de mes projets de recherche dans le domaine de l’intelligence artificielle pour lire des informations publiées sur le web dans des langues exotiques, comme le coréen, le chinois, le russe etc. Même si la qualité de la traduction n’est pas parfaite, elle est suffisante pour comprendre l’essentiel du contenu. J’apprécie la traduction de documents étrangers en luxembourgeois sur Google Translate lors de la rédaction d’articles techniques en luxembourgeois que je partage, de temps en temps, sur les réseaux sociaux. Le support de la langue luxembourgeoise dans les modèles de traduction machine à source ouverte récents, en combinaison avec la mise à disposition d’outils de programmation libres sur les plate-formes Github et Huggingface, facilitera le fin réglage des modèles de traduction luxembourgeois pour des domaines spécifiques, par exemple pour la biologie, la médecine, les finances etc. Si on passe en revue l’histoire de la traduction automatique, on constate une évolution exponentielle. Il y a eu plus d’innovations et de changements au courant des deux dernières années que pendant la période de 50 ans (de 1970 à 2019) précédente.
Une affaire de plagiat qui oppose un jeune artiste luxembourgois et une artiste renommée siné-américaine fait le tour des médias luxembourgeois et internationaux depuis plusieurs semaines. Le 19 septembre prochain, la justice luxembourgeoise entendra les avocats de chaque partie dans le litige qui les oppose. «Le moment sera jouissif», a fait savoir maître Gaston Vogel, l’avocat de l’artiste luxembourgeois.
Comme je suis fasciné par l’évolution fulgurante de l’intelligence artificielle (AI), basée sur des réseaux neuronaux appliqués à l’apprentissage profond des machines, j’ai exploré un modèle AI récent spectaculaire qui permet de créer des images et oeuvres d’art à partir d’une description en langage naturelle. Il s’agit du modèle DALL-E2 présenté en avril 2022 par la société commerciale OpenAI.
Dans l’édition du 14 juillet 2022 du magazine renommé IEEE Spectrum, l’éditrice Eliza Strickland a publié une contribution intitulée DALL-E 2’s Failures Are the Most Interesting Thing About It. Comme une image vaut mieux que qu’un long texte, je me permet d’illustrer les performances de ce modèle AI par deux oeuvres réalisées à la demande de l’IEEE.
L’image en haute résolution ci-dessous est le résultat de la requête soumise au modèle DALL-E2 avec la description “A Picasso-style painting of a parrot flipping pancakes“.
Le deuxième exemple avec la description “New Yorker-style cartoon of an unemployed panda realizing her job eating bamboo has been taken by a robot” est encore plus impressionnant.
New Yorker-style cartoon of an unemployed panda realizing her job eating bamboo has been taken by a robot credit IEEE Spectrum July 2022
Création et exploitation du modèle DALL-E2
Le modèle neuronal DALL-E2 a été entraîné avec environ 650 millions d’images, extraites d’Internet et étiquetées avec une description du contenu. Le modèle n’est pas public et jusqu’à présent seulement quelques chercheurs sélectionnés ont eu accès pour l’évaluer. Mais OpenAI vient d’annoncer le 20 juillet 2022 qu’un million d’usagers, qui s’était inscrit sur une liste d’attente, sera invité dans les prochaines semaines pour tester une version beta publique.
Chaque usager aura un crédit d’accueil gratuit de 50 points pour générer 50 images et chaque mois 15 points gratuits supplémentaires seront ajoutés. En outre des crédits de 115 points pour créer 115 images peuvent être achetés pour 15 dollars. Les images générées peuvent être utilisées à des fins commerciales.
OpenAI a installé certaines barrières pour empêcher la création de contenus violents, racistes ou pornographiques. En outre il n’est pas possible de générer des visages humains réalistes.
Les répercussions de l’utilisation de cette technologie à grande échelle sur les agences de communication et sur des professions d’art visuel seront significatives et vont également toucher l’industrie afférente au Grand-Duché de Luxembourg. Il est probable que l’utilisation de ces images synthétiques soit à l’origine d’autres affaires de plagiat qui vont se plaider devant les tribunaux au Luxembourg. L’appréciation d’un plagiat sera encore plus difficile, car il faut démontrer que des images spécifiques à attribuer à un auteur particulier ont été utilisées pendant l’entraînement du modèle et sont à l’origine d’un trait particulier de l’image générée par l’AI. Je parie que maître Gaston Vogel va vivre d’autres moments jouissifs.
Modèle Imagen de Google
Google a présenté le 23 mai 2022 un modèle similaire, appelé Imagen, dans une publication de recherche sur ArXiv. On peut voir des exemples sur le site web Imagen. Contrairement à OpenAI, Google ne s’est pas encore prononcé au sujet de la commercialisation de son modèle, mais prétend que les performances de son modèle sont supérieures à celui d’OpenAI.
Mes images réalisées avec DALL-E mini
Comme je ne fais pas encore partie des usagers beta invités par OpenAI, je me suis limité à tester le modèle DALL-E mini, développé par Boris Dayma. Publié d’abord sur la plateforme AI communautaire géniale HuggingFace, le modèle public DALL-E mini, devenu viral, vient d’être transféré sur un site propre www.craiyon.com. Ce modèle n’a pas la résolution ni la performance de son tuteur, mais les résultats permettent d’apprécier le pouvoir de disruption de cette nouvelle technologie AI. Tout comme l’original, DALL-E mini ne créé pas de visages réalistes pour éviter des abus.
Lors de la soumission d’une description dans la barre de titre de l’application Craiyon, 16 images en faible résolution sont générées et les 9 meilleurs résultats sont affichés. La galerie ci-après présente quatre requêtes associées au nom de l’artiste Jingna Zhang. À vous de juger s’il s’agit de plagiats.
click to zoomclick to zoomclick to zoom
Testeur beta
Le 15 août 2022 OpenAI m’a informé que ma candidature pour participer aux tests de DALL-E2 a été acceptée.
Je n’ai donc pas hésité à faire de suite les premiers essais. Le titre soumis pour la première image était “cartoon of an elephant and a giraffe riding a bicycle on the beach“. J’ai saisi le texte “a painting of the ark Noe in the style of Renoir” pour créer la deuxième image. Parmi les quatre images générées avec la résolution 1024 x 1024 pixels pour chaque description, j’ai choisi les oeuvres d’art suivants qui me plaisent le mieux.
Image générée par DALL-E2 de OpenAI avec la description “cartoon of an elephant and a giraffe riding a bicycle on the beach“Image générée par DALL-E2 de OpenAI avec la description “a painting of the ark Noe in the style of Renoir“
Je me propose de créer dorénavant au moins une image par jour et de les partager sur les réseaux sociaux. Le 16 août 2022 j’ai publié les neufs premières créations sur mon compte Instagram.
Fake News, Photo Retouching, Deepfake a Voice Clonig sinn Begrëffer, déi een zënter e puer Joren ëmmer méi oft héiert.
Coqui.ai, eng Start-Up aktiv am Beräich vun der Sproochsynthees (TTS) a Sproocherkennung (STT), déi ufanks 2021 vun fréieren Mataarbechter vum Mozilla-Voice-Projet gegrënnt gouf, huet virun e puer Deeg eng flott Voice-Cloning-Applikatioun presentéiert.
Domat kann jiddereen seng eege Stëmm benotzen fir Texter a syntheetesch Sprooch ëmzewandelen.
Audio Datei ophuelen oder oplueden
Et brauch een dozou eng Audio-Datei vun maximal 30 Sekonnen, déi een um Website vun Coqui.ai kann ophuelen oder oplueden. Ech hunn dat haut emol ausprobéiert, mat menger eegener Stëmm an mat där vum Charel, ee vu mengen Enkelkanner.
Nodeems déi kënstlech TTS-Stëmm generéiert gouf, kann een se direkt ausprobéieren. Den Sproochsynthees-Modell schwätzt bis elo nëmmen Englesch, wat et e bësschen méi schwéier mécht fir d’original Stëmmen erëmzekennen.
Text mat Stëmm syntheetesch generéieren
Als Text hunn ech den Ufank vun deem bei Linguisten beléiwten Epos vum “Nordwand and der Sonn” benotzt:
The North Wind and the Sun were disputing which was the stronger, when a traveler came along wrapped in a warm cloak. They agreed that the one who first succeeded in making the traveler take his cloak off should be considered stronger than the other.
Den Tempo vun der generéierter Sprooch kann normal, schnell oder lues gewielt ginn.
Dem Charel seng Stëmm
Hei ënnen drënner kënnen mer dem Charel seng Opnam lauschteren an eis de Signalverlaf mam Audacity Programm ukucken.
Audio source Charel : 29 secondes
An hei ass dem Charel seng TTS-Stëmm an den entspriechenden Signalverlaf. Fantastesch!
Il y a plusieurs années j’avais testé à l’aide de photos de mes petits-enfants les services de reconnaissance de personnes et de motifs, disponibles sur le web, basés sur l’intelligence artificielle. Pour les GAFAM (Google, Apple, Facebook, Amazon et Microsoft) ces services sont devenus aujourd’hui des produits commerciaux lucratifs. Les start-up’s actives à l’époque dans ces domaines ont presque toutes été acquises entretemps par les géants du web, auxquels il faut ajouter IBM (GAFAMI).
La liste de mes anciennes contributions à ce sujet est relevée ci-après:
La reconnaissance faciale est un moyen d’identifier ou de confirmer l’identité d’un individu grâce à son visage. Les systèmes de reconnaissance faciale peuvent servir à l’identification de personnes sur des photos, dans des vidéos ou en temps réel.
La reconnaissance faciale est devenue aujourd’hui un outil de la vie quotidienne : pour débloquer son mobile, pour retrouver des personnes sur les réseaux sociaux, pour gérer sa collection de photos numériques sur son ordinateur, sa station-disque ou dans le nuage (cloud).
J’ai sauvegardé sur ma station-disque Synology des dizaines de milliers de photos que je gère avec les applications PhotoStation et Moments. Il s’agit de photos récentes prises avec des appareils photographiques digitaux ou avec des mobiles, des diapositives ou négatives numérisés, d’anciennes photos scannées (avec un scanner ou avec Google PhotoScan) ou des images synthétiques respectivement des copies-écran.
La majorité des logiciels de gestion d’une collection de photos dispose aujourd’hui d’une application de reconnaissance faciale intégrée performante. Synology ne fait pas d’exception. Les images suivantes montrent les résultats de recherches de quelques anciens collaborateurs, collègues et amis, de mes anciens directeurs, de membres de ma famille.
Cliquez pour agrandir
Il est évident qu’il faut entrer le nom d’une personne la première fois qu’une photo avec un nouveau visage est enregistrée. Mais à partir de ce moment, la reconnaissance des personnes se fait automatiquement lors de chaque nouvelle sauvegarde d’une photo, avec une précision étonnante. Il peut s’agir de portraits, de photos plan buste, de cadrages plein pied et même de photos de groupe avec plusieurs dizaines d’individus. Il est même possible de regrouper automatiquement des mannequins, des sculptures de bustes, des peintures, même s’il s’agit de visages différents.
Si l’application ne réussit pas à identifier un visage, elle présente les photos afférentes avec la question “Who’s This?” On peut alors répondre en indiquant le nom correct et le tour est joué. Les raisons d’une identification non-réussie sont multiples : Des nouveaux-nés dont le visage change en permanence les premiers mois, des personnes costumées (carnaval) ou masquées (Covid) comme Thomas, Charles et Capucine, des personnes avec ou sans lunettes comme Frank, des personnes sans identification manuelle initiale comme Isabelle, des statues de pharaons sans noms.
Reconnaissance de motifs et d’objets
Une application d’intelligence artificielle (AI) intégrée dans les logiciels de gestion de photos, plus spectaculaire encore que la reconnaissance faciale, constitue la reconnaissance automatique des motifs et objets représentés sur les photos d’une collection, accompagnée d’une classification automatique dans des albums virtuels. L’utilisateur n’a pas besoin d’intervenir dans ce processus. L’entraînement des modèles AI se fait par les développeurs des logiciels à partir de bases de données publiques contenant des millions d’images annotées.
La base de données d’images avec étiquettes la plus fameuse est ImageNet. Lancée en 2006 par la chercheuse Fei-Fei-Li, spécialiste de la vision par ordinateur, la base de données ImageNet a été étendue progressivement et comprend actuellement plus que 14 millions d’images.
Au début mes photos ont été classées automatiquement par grandes rubriques : enfants, animaux, paysages, architectures. etc. J’ai considéré cette option comme gag intéressant. Avec chaque nouvelle mise à jour le logiciel est devenu plus performant. Pour les animaux des sous-catégories ont été créées: tortues, escargots, lapins, poissons, chevaux, moutons, chats etc. Actuellement l’AI commence à différencier les races des chiens. Aujourd’hui la classification automatique est un outil précieux pour moi pour rechercher des souvenirs.
Au niveau de l’alimentation, le programme fait la distinction entre pizza, paëlla, menu italien, dessert etc.
Cliquez pour agrandir
Identification de desserts non comestibles
Si on regarde l’image de couverture sélectionnée par l’AI pour la rubrique Dessert, on constate qu’il s’agit en réalité du livre “2. Schoulheft” de Capucine. J’ai constaté que parmi toutes les catégories c’est dans la rubrique “Dessert” que l’AI de Synology se trompe le plus souvent. Les copies-écran suivantes montrent quelques exemples: une oeuvre d’art peinte par un enfant, un tablier de jeu de moulin, deux poussins dans un carton, un jouet FisherPrice, une collection de minéraux, un bonhomme de neige, un caméléon télécommandé.
Je retire toutefois mon chapeau pour la reconnaissance par l’AI que les quatre photos de Capucine, avec des framboises sur les doigts, représentent un dessert.
Cliquez pour agrandir
Mais l’AI de Synology n’est pas la seule à se tromper avec des photos de menus. Il y a deux ans Google avait pris l’initiative automatique de créer un vidéoclip intitulé “Bon appétit” avec mes photos prises en 2019 avec mon iPhone. Parmi les dégustations figuraient des photos de têtards, du moisi dans un pot de confiture, des jouets de dinosaures qui sortent d’un oeuf et de plats garnis par mes petits-enfants avec des coquillages, fleurs et feuilles d’arbustes.
Mot de la fin
Malgré ces quelques erreurs qui font rire, les performances de l’intelligence artificielle progressent à grands pas et les résultats sont de plus en plus impressionnants.
Dans l’attente de l’élimination de quelques bogues dans les modèles de synthèse vocale (TTS) par la communauté Coqui.ai, aux fins de progresser avec mon projet de création d’une voix TTS luxembourgeoise, je me suis focalisé les dernières semaines sur la reconnaissance automatique de la parole luxembourgeoise (STT: Text to Speech ou ASR: Automatic Speech Recognition).
Pour entraîner un modèle STT avec des réseaux neuronaux, il faut disposer d’une base de données audio avec les transcriptions de la parole enregistrée. Au début 2022 j’avais finalisé une base de données avec les enregistrements de quatre oratrices (au total 1005 échantillons) pour l’entraînement d’un modèle TTS luxembourgeois avec quatre voix. Entretemps j’ai complété cette base avec des enregistrements publics de trois orateurs (1.676 échantillons) et je l’ai étoffé avec les enregistrements audio du dictionnaire luxembourgeois LOD (24.678 échantillons).
Ainsi j’ai pu constituer deux ensembles de données avec 2.880, respectivement 27.072, échantillons qui se prêtent pour l’entraînement de modèles TTS et STT. Je vais prochainement publier ces bases de données LB-2880 et LB-27072 sur mon compte Github.
Les deux ensembles sont segmentés en trois volets. Le plus large (train.csv) est utilisé pour l’entraînement du modèle, le deuxième (val.csv) sert à mesurer le progrès de l’entraînement après chaque cycle d’itérations (époque) et le troisième (test.csv) permet de tester la performance du modèle à la fin de l’entraînement. Les détails sont indiqués dans le tableau qui suit:
Base de données
LB-2880
LB-27072
Durée totale
ca 7 heures
ca 13 heures
échantillons train
2560
25600
échantillons val
192
1344
échantillons test
128
128
Transfert d’apprentissage
Convaincu que le seul moyen pour réussir l’entraînement d’un modèle STT luxembourgeois consiste à se baser sur un large modèle pré-entraîné dans une autre langue, je me suis tout de suite concentré sur cette option de transfert d’apprentissage. Les résultats impressionnants que le Pr Peter Gilles a obtenu sur base du modèle wav2vec2-XLS-R-300m créé par Meta AI (Facebook) ont renforcé ma conviction.
Coqui.ai a mis un modèle pré-entraîné en langue anglaise à disposition de la communauté. Comme la langue luxembourgeoise utilise un alphabet plus large que l’Anglais avec les caractères accentués suivants
il faut supprimer la dernière couche de neurones du modèle pré-entraîné anglais pour pourvoir l’entraîner avec une base de données luxembourgeoise. Le hyper-paramètre de configuration ‘--drop_source_layers 1‘ permet de remplacer la dernière couche avec une nouvelle couche, initialisée avec l’alphabet luxembourgeois.
Hélas les premiers résultats ne répondaient pas du tout à mes attentes et les métriques affichées étaient plus mauvaises que celles obtenues lors de mes premiers tests, effectués à partir de zéro au début de l’année.
Modèles HuggingFace
Pour exclure que la qualité de ma base de données soit insuffisante, j’ai essayé de reproduire l’entraînement du premier modèle STT luxembourgeois sur HuggingFace avec mes propres données. Comme l’utilisation du modèle géant wav2vec2-XLS-R-300m, qui a servi de base pour le premier modèle, dépassait avec 300 millions de paramètres la capacité de traitement de mon ordinateur desktop, ainsi que celle de mon compte Pro sur la plateforme Google Colab, j’ai choisi un modèle pré-entraîné plus simple sur HuggingFace, à savoir le modèle Wav2Vec2-XLSR-53.
Avec un résultat WER de 0,17 j’ai réussi à obtenir des valeurs de même niveau que celles rapportées par le Pr Peter Gilles. Je vais prochainement publier mon modèle résultant sur mon compte HuggingFace.
Modèle Coqui-STT
On peut se demander quel est l’intérêt de s’acharner sur d’autres modèles STT que ceux offerts en source ouverte sur la plateforme formidable HuggingFace qui constitue aujourd’hui la référence en matière de l’apprentissage automatique profond et la plus grande communauté d’intelligence artificielle (AI) sur le web.
La réponse n’est pas simple. Une raison est certainement la taille des modèles STT entraînés. Si la taille est de quelques Giga Bytes dans le premier cas, elle est de quelques dizaines de Mega Bytes dans le cas du modèle Coqui-STT, ce qui permet de le porter sur un mobilophone (iOS et Android) ou sur un nano-ordinateur mono-carte comme le Raspberry Pi. Une deuxième raison est l’adaptation plus simple à son propre environnement. La configuration fine du modèle Coqui-STT simplifie son optimisation pour une utilisation spécifique. Personnellement je suis d’avis que la majeure raison constitue toutefois la transparence des processus. Les recettes HuggingFace sont une sorte de boîte noire d’usine à gaz qui fournit des résultats spectaculaires, mais dont le fonctionnement interne est difficile à comprendre, malgré l’ouverture du code. Pour apprendre le fonctionnement interne de réseaux de neurones un modèle comme Coqui-STT est plus approprié. J’ai donc continué à explorer l’apprentissage automatique profond du modèle Coqui-STT à partir de zéro, avec la certitude que ma base de données est de qualité.
Comme le fichier de configuration Coqui-STT comporte 96 hyper-paramètres, j’ai essayé de comprendre le rôle de chaque hyper-paramètre. J’ai vérifié également l’influence de quelques hyper-paramètres clés sur l’entraînement du modèle à l’aide d’une base de données restreinte de 100 échantillons. Les résultats significatifs sont commentés ci-après:
Similarité des entraînements
La taille d’un réseau de neurones est déterminée par le nombre de couches, le nombre de neurones par couche et le nombre de connexions entre neurones. Le total constitue le nombre de paramètres du modèle, à ne pas confondre avec les hyper-paramètres qui spécifient la configuration du modèle. Les paramètres du modèle sont initialisés au hasard au début de l’entraînement. Pour cette raison chaque processus d’entraînement produit des résultats différents. Le graphique qui suit montre en trois différentes vues que les différences sont négligeables.
Nombre de couches
Le nombre de couches par défaut du modèle Coqui-STT est de 2048. Ce nombre est trop élevé pour une petite base de données. La figure suivante montre en deux vues l’évolution de l’entraînement en fonction du nombre de couches.
Nombre de lots
Les échantillons de la base de données pour entraîner le modèle STT sont répertoriés dans un fichier csv dans le format suivant:
wav_filename,wav_filesize,transcript
wavs/guy/walresultat-04.wav,232854,awer och net op eng spektakulär manéier obwuel a prozenter ausgedréckt ass de minus dach méi staark wéi a sëtz ausgedréckt
wavs/sara/Braun_042.wav,113942,ech hunn am bësch eng heemeleg kaz fonnt
wavs/jemp/WD-2007-jemp-07.wav,197962,wou en dag fir dag e puer vun deene fäll klasséiert
wavs/judith/marylux_lb-wiki-0138.wav,132754,florange ass eng franséisch uertschaft a gemeng am departement moselle a loutrengen
...........
Chaque ligne du fichier csv correspond à un échantillon et comporte le chemin et le nom d’un fichier audio, la taille de ce fichier et la transcription de l’enregistrement audio, en lettres minuscules et sans signes de ponctuation. Les échantillons sont regroupés par lots lors de l’entraînement. Une itération d’entraînement comprend le traitement d’un seul lot. Une époque comprend le total des itérations pour traiter tous les échantillons. Si la taille d’un lot est égal à un, le nombre des itérations est égal au nombre des échantillons. Dans le cas d’un lot de 10, le nombre des itérations est seulement un dixième du nombre des échantillons. Comme le temps de calcul d’une itération n’augmente presque pas avec l’accroissement de la taille d’un lot, le temps d’entraînement se réduit de la même manière. On a donc intérêt à spécifier une taille élevée des lots. Hélas, la taille des lots est fonction de la mémoire disponible du processeur graphique (GPU). Une taille trop élevée génère des erreurs “memory overflow” .
J’ai réalisé tous mes entraînements sur mon ordinateur desktop avec GPU NVIDIA RTX2070 avec des lots de 32, respectivement de 16 dans certains cas spécifiques.
Rapport entre entraînement et validation
Le graphique qui suit montre l’évolution de l’entraînement pour une base de données déterminée en fonction de la répartition des échantillons pour l’entraînement et pour la validation.
La segmentation de 93:7 que j’ai chois semble être appropriée.
Taux Dropout
Le mécanisme de “dropout” permet de réguler l’apprentissage d’un réseau de neurones et de réduire le “overfitting“. Il consiste à la suppression au hasard de connexions entre neurones pendant chaque itération à un taux spécifié dans la configuration. Le graphique suivant montre l’influence de ce taux sur l’entraînement. La valeur par défaut est de 0.05 et produit les meilleurs résultats.
Taux d’apprentissage
Le taux d’apprentissage (learning rate) est un hyper-paramètre important dans la configuration d’un modèle STT ou TTS. La valeur par défaut du modèle Coqui-STT est de 0.001. La figure qui suit montre l’influence de ce taux sur l’entraînement.
Une option de configuration intéressante proposée par le modèle Coqui-STT est la suite des hyperparamètres suivants:
Elle permet de modifier le taux d’apprentissage si la performance de l’entraînement ne progresse plus pendant trois époques. On parle de plateau dans la métrique affichée. J’ai utilisé cette option dans tous mes entraînements.
Augmentation des données
En général les modèles d’apprentissage automatique en profondeur sont très gourmands en données. Que faire si on ne dispose pas d’un nombre important de données pour alimenter un modèle ? On augmente les données existantes en ajoutant des copies modifiées des échantillons ! Dans le cas du modèle Coqui-STT on créé par exemple des fichiers audio modifiés avec les mêmes transcriptions. En changeant le volume, le ton, la cadence ou le spectre des enregistrements, on peut créer des échantillons supplémentaires.
L’outil data_augmentation_for_asr de Frederic S. Oliveira permet de générer aisément des nouveaux fichiers .wav et .cvs à ajouter à la base de données existante. J’ai réalisé des tests afférents en désignant ce processus comme augmentation externe. Le modèle Coqui-STT inclut une telle option sans recourir à un outil externe et sans augmenter le temps d’entraînement. L’hyper-paramètre suivant, ajouté au script d’entraînement,
permet par exemple de tripler le nombre des échantillons.
Suivant mes tests l’augmentation des donnés ne présente plus d’intérêt si le nombre des échantillons originaux dépasse quelques milliers.
Un type d’augmentation pour l’entraînement STT que je n’ai pas encore testé est la création d’échantillons synthétiques moyennant un modèle TTS luxembourgeois. C’est une piste que je vais encore explorer.
Résultats des entraînements avec les deux bases de données
LB-2880
La base de données LB-2880 comprend 2530 échantillons enregistrés par 4 oratrices et par 3 orateurs, ainsi que 350 mots du dictionnaire LOD. Le tableau qui suit relève les résultats pour des entraînements avec différents paramètres, pendant 30 époques chacun:
couches
lot
augmentation
meilleur modèle acoustique
WER
CER
LOSS
1024
16
sans
best_dev_1760
0.705
0.221
73,9
1024
16
interne
best_dev_2720
0,717
0.222
69,0
2048
16
sans
best_dev-1440
0.723
0.224
78.5
2048
16
externe
best_dev-2395
0.776
0.271
78.4
2048
16
interne
best_dev-3520
0.710
0.231
70,8
LB-27072
La base de données LB-72072 est identique à la base LB-2880, mais avec l’addition de 24.192 échantillons (mots) du dictionnaire LOD. Les résultats sont affichés ci-après:
couches
lot
augmentation
meilleur modèle acoustique
WER
CER
LOSS
1024
16
sans
best_dev-25600
0.729
0.253
94.2
2048
16
sans
best_dev-19200
0.732
0.247
97.2
2048
16
interne
best_dev-41600
0.870
0.338
92.8
Comparaison
Contrairement à mes attentes, l’inclusion de tous les mots du dictionnaire LOD ne produit pas un meilleur modèle STT, au contraire. Les métriques des modèles LB-27072 sont globalement moins performants que celles des modèles entraînés avec la base de données LB-2880. Je vais prochainement explorer si la base de données LB-27072 présente des avantages pour l’entraînement d’un modèle TTS.
Les performances des cinq modèles entraînés avec la base de données LB-2880 ne diffèrent pas sensiblement. Je me propose de retenir le modèle à 1024 couches et entraîné sans augmentation de données comme meilleur modèle acoustique.
Tensorflow Lite
Il est recommandé de convertir le meilleur modèle en format Tensorflow Lite (.tflite) pour pouvoir le déployer sur des systèmes à ressources restreintes comme des mobilophones. Le script pour exporter le modèle est le suivant:
Le modèle exporté a une taille de 12.2 MB. Je signale qu’il existe un standard ouvert pour les modèles AI, appelé ONNX (Open Neural Network Exchange), qui n’est pas encore supporté par Coqui-STT.
Modèle de langage
Un système de reconnaissance de la parole ne comporte pas seulement un modèle acoustique comme nous l’avons vu jusqu’à présent, mais également un modèle de langage qui permet de corriger et de parfaire les résultats du modèle acoustique. L’outil KenML représente actuellement l’état d’art dans la création d’un modèle de langage. HuggingFace et Coqui-STT supportent tous les deux cet outil, en combinaison avec le modèle acoustique.
Dans le cas du projet Coqui-STT, dont le code est exécuté dans un conteneur Docker, sans intégration de l’outil KenML, la réalisation du modèle de langage luxembourgeois demande quelques bricolages informatiques. J’ai toutefois réussi à créer un modèle de langage à l’aide de la base de données LB-27072. Ce modèle se présente comme suit et comprend un vocabulaire de 25.000 mots uniques.
A la fin de cet exposé il convient de comparer les performances de mon meilleur modèle acoustique Coqui-STT, combiné avec mon modèle de langage KenML, avec celles du modèle pgilles/wavevec2-large-xls-r-LUXEMBOURGISH-with-LM.
A ces fins j’ai sélectionné au hasard cinq échantillons qui ne font pas partie des entraînements effectués sur les deux modèles:
wavs/Braun_066.wav,233912,hues de do nach wierder et koum en donnerwieder an et huet emol net gereent
wavs/alles_besser-31.wav,168348,déngschtleeschtungen a wueren ginn automatesch och ëm zwee komma fënnef prozent adaptéiert
wavs/lb-northwind-0002.wav,82756,an der zäit hunn sech den nordwand an d’sonn gestridden
wavs/mbarnig-gsm-75.wav,104952,a wou den deemolege president et war e finnlänner
wavs/dictate_dict9-18.wav,182188,dobäi muss de bierger imperativ op allen niveaue méi am mëttelpunkt stoen
Les résultats sont présentés dans le tableau qui suit:
transcription source
reconnaissance HuggingFace
WER
reconnaissance Coqui-STT
WER
hues de do nach wierder et koum en donnerwieder an et huet emol net gereent
hues de do nach wierder et koum en donnerwieder an etude monet gereent
0.267
hues de do nach wierder et koum en donnerwieder an et huet mol net gereent
0.067
déngschtleeschtungen a wueren ginn automatesch och ëm zwee komma fënnef prozent adaptéiert
déng schlecht jungenawouren ginautomatech or zweker a déiert
1.0
angscht leescht engen a wueren ginn automatesch och am zwee komma fanne prozent adapter
0.500
an der zäit hunn sech den nordwand an d’sonn gestridden
an der zäit hunn sech de nocturnen zon gestridden
0.4
an der zeitung sech e nach finanzen lescht rieden
0.700
a wou den deemolege president et war e finnlänner
wou den deemolege president war e finnlänner
0.222
a wou den deemolege president et war finn aner
0.222
dobäi muss de bierger imperativ op allen niveaue méi am mëttelpunkt stoen
dobäi muss de bierger imperativ op alle nivo méi a mëttepunkt stoen
0.333
do bei muss de bierger imperativ op allen niveaue ma am et e punkt stoen
0.500
Conclusions
Il semble que le modèle HuggingFace fait moins d’erreurs, mais je pense qu’il faut faire plus de tests pour évaluer correctement la performance des deux modèles. Les résultats me réconfortent de continuer l’exploration du modèle Coqui-STT avec un apprentissage à partir de zéro. Je me propose de suivre les pistes suivantes:
étendre ma base de données LB-2880 avec la création d’échantillons supplémentaires à partir d’enregistrements audio de RTL Radio pour parfaire mes modèles Coqui-STT et Coqui-TTS
porter le modèle Coqui-STT sur iPhone
examiner la possibilité d’extension de ma base de données STT moyennant des échantillons synthétiques créés à l’aide de modèles TTS luxembourgeois
explorer l’utilisation de l’augmentation des données et d’échantillons synthétiques sur mon modèle HuggingFace
Application interactive de démonstration
J’ai publié le 31 juillet 2022 une application interactive lb-de-en-fr-pt-COQUI-STT de mon modèle sur la plateforme d’intelligence artificielle Huggingface. Veuillez utiliser un navigateur Chrome pour explorer la démo.
La présente contribution est un sous-chapitre de mon projet de livre au sujet de l’histoire des technologies de l’information et de la communication (TIC) au Luxembourg.
Introduction
Les jeux électroniques ne constituent non seulement des loisirs numériques, mais des vraies activités sportives, qui ne tarderont pas d’être intégrées dans les jeux olympiques, probablement dès 2028 à Los Angeles. eSport est l’abréviation de sport électronique et désigne la pratique sur Internet ou en LAN-Party d’un jeu vidéo, seul ou en équipe, par le biais d’un ordinateur, d’une console de jeux vidéo ou d’un smartphone. Certes l’eSport demande d’autres efforts physiques que la natation, le football, le marathon ou l’équitation, mais il comporte tous les ingrédients que le sport traditionnel : l’entraînement, l’hygiène de vie, les équipes, les compétitions, les fédérations, les ligues, les sponsors, les médailles, les joueurs professionnels, les spectateurs, les maillots etc.
Le premier tournoi eSport a eu lieu en 1997 et regroupait environ 300 concurrents autour d’un jeu unique : Quake. Le tournoi a été organisé par CPL (Cyberathlete Professional League), fondée par Angel Munoz.
Le Luxembourg a une riche histoire en sport électronique, mais peu connue par le grand public. En 2022, l’intéressé au sport électronique peut s’informer aisément sur l’évolution des compétitions qui se déroulent actuellement au Luxembourg. Le moyen le plus pratique est de regarder la vidéo hebdomadaire Panorama, produite par la société 11F depuis le début 2022.
Une autre source constitue la rubrique Gaming sur le site web de RTL, introduite en mars 2016. Finalement on peut faire une recherche avec les mots clé eSport ou Gaming sur les sites web de la presse écrite : Paperjam, Wort, Tageblatt, Quotidien, Essentiel, etc. Il existe en outre des sites web événementiels qui renseignent sur la scène des sports électroniques, comme mental.lu, moien.lu, supermiro.lu, etc.
Pour retracer l’histoire de l’eSport au Luxembourg, dès ses débuts, c’est moins évident. Grâce à mes archives privées et à la machine wayback sur Internet j’ai réussi à établir une chronologie des événements les plus importants et à identifier les pionniers de l’eSport au Luxembourg. J’ai segmenté l’histoire afférente en quatre parties qui se chevauchent toutefois dans la pratique :
1980 – 1999 : la préhistoire de l’eSport
2000 – 2009 : l’eSport se pratique hors ligne en réseau local
2010 – 2019 : l’eSport passe sur Internet à haute vitesse
> 2020 : l’eSport devient une nouvelle industrie à part entière
1980 – 1999 : la préhistoire de l’eSport
Abstraction faite de quelques séances de tennis jouées sur une console Atari au début des années 1980, mes vrais souvenirs sur l’eSport, qui remontent à la surface, se situent dix ans plus tard. Au début des années 1990 mes enfants invitaient régulièrement leurs amis autour d’un jeu mono-joueur, comme PacMan ou Tetris, exécuté sur mon ordinateur personnel Atari ST. Le plus rapide, ou celui qui obtenait le plus de points, était le vainqueur du jour.
Mono-jeux vidéo sur Atari 1040 en 1993
A l’époque certains pédagogues pensaient que le jeu vidéo constituait un facteur d’isolement pour les enfants. J’ai observé le contraire. Les parties comnunes de jeux vidéo favorisaient les contacts sociaux.
En 1992, Dan Steinmetz et Yves Thommes, originaires de la région d’Echternach, ont chassé ensemble les nazis dans le fameux jeu vidéo Wolfenstein 3D. En décembre 1993 le premier grand jeu multi-joueur DOOM a été lancé. Les deux copains ont passé de plus en plus de temps à jouer DOOM sur leurs ordinateurs, interconnectés avec un câble null-modem. Dans la suite deux autres copains, Patrick Morette et Jérôme Peeters, ont rejoint la communauté. Fin 1994 ils étaient donc quatre: badblood, doc holliday, mow et wotan, qui se retrouvaient chaque week-end pour jouer DOOM 2 et Warcraft 2.
En 1995 ils se sont nommés THE Wicked NET et ils décidaient d’étendre leurs activités, en dehors des jeux vidéo : musique, graphiques, films, programmes. Le collectif s’est élargi avec Frank Lazzarini (latz) et François Campill (scav).
Le 22 juin 1996 le fameux jeu vidéo de tir à la première personne (FPS), Quake, a été publié en version shareware par id Software, et un mois plus tard, en version commerciale par GT Interactive. A cette occasion les 6 copains ont organisé la première LAN-Party d’envergure au Luxembourg qui durait 10 jours.
Comme cet événement a connu un grand succès, THE Wicked NET à continué à organiser des LAN-Parties d’une durée de une à deux semaines, toutes les six semaines environ. A fur et à mesure des événements les meilleurs joueurs ont été admis comme nouveaux membres de la communauté.
En 1998 l’équipe a été renforçée davantage par l’adhésion du team “Show no Pain” de Mamer. Mais à la même époque les premiers fondateurs et membres du collectif quittaient le pays pour des raisons d’études.
Au mileu des années 1990, une autre communauté, les fans de la fédération des planètes unies, a fondé en 1994 l’académie Starfleet du Luxembourg (SFAL).
2000 – 2009 : l’eSport se pratique hors ligne en réseau local
A la fin des années 1990 et au début du nouveau millénaire, une LAN-Party se déroulait typiquement comme suit : l’organisateur invitait des participants potentiels à le rejoindre, à une date précise, pour jouer ensemble un (ou plusieurs) jeu vidéo et pour célébrer à la fin le meilleur joueur. Les participants amenaient leur ordinateur, ou leur console de jeu vidéo, ainsi que tout accessoire disponible, pour interconnecter les équipements dans un réseau local (LAN). En général l’organisateur disposait d’un minimum de matériel informatique, comme un concentrateur et des câbles réseau, aux fins d’assurer le bon fonctionnement du LAN. Comme une LAN-Party se déroulait en général pendant quelques jours sans interruption, souvent du vendredi soir jusqu’au dimanche après-midi, il fallait également apporter son sac de couchage et du ravitaillement pour boire et manger. L’événement se terminait souvent par une activité physique, par exemple le lancement d’un vieux clavier le plus loin possible. Les photos ci-après, prises lors de la LAN-Party HESE-1 à Kopstal en 2008 par les participants, racontent le déroulement en images.
Si les premiers LAN-Parties ont eu lieu dans la cave ou le garage des parents de l’organisateur, avec l’accroissement du nombre de participants elles se sont progressivement déplacées vers des locaux plus spacieux : écoles, centres culturels, auberges de jeunesse, halls d’exposition.
Jean-Claude Zeimet a présenté le 7 juin 2013 sa dissertation au sujet des élites de la scène culturelle de la jeunesse au Luxembourg, entre autres dans le domaine des LAN-Parties, pour l’obtention du degré de docteur de l’Université du Luxembourg en sciences sociales. Comme son étude traite les aspects qualitatifs des LAN-Parties, je vais me limiter à décrire les aspects factuels et quantitatifs de ces événements pour la période de 2000 à 2009.
Dans le chapitre sur la préhistoire de l’eSport nous avons fait connaissance du collectif THE Wicked NET qui est d’avis qu’il mérite le titre de vétéran des LAN-Parties au Luxembourg. Je partage cet avis. Au début des années 2000 cette communauté a continué à organiser des LAN-Parties jusqu’en 2006, mais à un rythme moins élevé : deux à trois événements par année. En 2020 quelques membres avaient mis en place le site web foobar.lu pour parler de tout et de rien, suivi en 2001 du site web gaming.lu, destiné à la communauté des joueurs vidéo au Luxembourg.
gaming.lu 2002gaming.lu 2004gaming.lu 2008Layouts du site web gaming.lu créé par THE Wicked NET
Le serveur qui était hébergé par Visual Online proposait au début plusieurs jeux en ligne comme Counterstrike, Quake III,Rocket Arena, Unreal Tournament etc. Les services offerts ont été étendus progressivement, le layout a été modifié plusieurs fois et le site est resté opérationnel jusqu’en 2014. Depuis 2019 le nom de domaine gaming.lu est redirigé vers videogames.lu.
Entre 2002 et 2003 le site web www.scene.lu fournissait des informations au sujet des LAN-Parties, l’année suivante les annonces ont également été insérées dans le site web allemand lansurfer.com. L’ équipe THE Wicked NET gérait temporairement le site web lanparty.lu à partir de 2005.
Site web lanparty.lu en 2005
Sur la machine wayback on trouve la liste de tous les membres du collectif THE Wicked NET au début des années 2000. Les six fondateurs sont appelés The Litch Kings, les suiveurs sont désignés par Our Minions :
The Litch Kings du collectif THE Wicked NET
Dan Steimetz (badblood)
Yves Thommes (doc holliday)
Patrick Morette (mov)
Jérôme Peeters (wotan)
Frank Lazzarini (latz)
François Campill (scav)
The Minions du collectif THE Wicked NET
Marco Moretto (moreno)
Claude Linden (yggi)
Alain Stoos (fixspoun)
Marc Letsch (fox)
Dan Scheer (blubber)
Martin May (hiro)
Claude Dondelinger (dondel)
Ben Kremer (jungle)
Pascal Klares (humanoid)
Nicole Morette (nic)
Albert Michel (exhuma)
Jean-Paul Daleiden (galen)
Collectif THE Wicked NET en 2014
A partir de 1998 Claude Pick (SuperJemp) et Serge Guth (MonStar) ont organisé les premières LAN-Parties FragCities à Stegen. Ils ont été assistés dans la suite par Patrick Schweig (Landaro) et Michel Meyers (Steltek), les créateurs de la première Luxembourg Computer Gaming League (LCGL).
L’organisation de la sixième édition de la LAN-Party FragCity à Stegen le 28 octobre 2000 est à l’origine d’un tournant dans l’organisation de ces événements. FragCity 6 était prévue pour 45 participants, mais fiinalement 65 joueurs arrivaient sur place, avec leur ordinateur sous le bras. Malgré le chaos et la température dépassant 30 degrés dans le local, l’événement était un succès. Les organisateurs décidaient alors de créer une organisation commune pour mieux gérer de tels défis. Le 28 décembre 2000 la ligue LCGL a été transformé en asbl, avec les membres suivants du premier comité :
Patrick Schweig (Landaro) : président
Jerry Kohn (Pegasus) : vice-président
Serge Draut (Ikki) : secrétaire
Claude Pick (Superjemp) : trésorier
Robert Grehten (Luther) : membre
lcgl.lu 2002lcgl.lu 2004Site web de la Luxembourg Computer Gaming Ligue
En dehors des LAN-Parties FragCity, le club LCGL avait organisé le 3 août 2001 la première édition de de_Lux.LAN à Clervaux, qui a été supportée par le Service National de la Jeunesse, Hewlett Packard et Cisco. Cet événement a été voté “best LAN-Party of the year”. L’expérience a été répétée dans les trois années suivantes. En 2006 le LCGL planifiait un événement mega, de_lux.LAN on the Rocks, avec 800 participants, du 17 au 19 septembre à la Rockhal à Esch-Belval, avec le support de nombreux sponsors. Un site web spécifique www.lanontherocks.lu avait été créé pour cette manifestation. Comme les inscriptions des joueurs restaient faibles, l’événement a été annulé fin juillet 2006 et le LCGL a arrêté ses activités.
Site web lanontherocks.lu août 2006
Les 20-21 octobre 2001, dans le cadre du Jamboree on the Air & Internet, les scouts de Monnerich avaient organisé une LAN-Party avec le matériel mis en place pour cet événement. L’expérience a été répétée dans les années suivantes et les Lan-Parties à Monnerich, organisées par le Minett LAN Fellowship (MLF), ont connu un grand succès, en accueillant également des participants sans adhésion au scoutisme.
En septembre 2002 Jerry Kohn (Pegaus), Guy Simon (locutus), Luc Fischer et Serge Rosen ont constitué l’association Computer Lan Club Minett (asbl CLCM : F984). Ce club a été actif jusqu’en 2006.
Georges Engelmann (georges), Francis Engelmann (Happy-Divi) et Christophe Anthon (BlackHat) ont créé en décembre 2002 la structure de développement web XLiners.org. En août 2003 ils ont lancé le projet lanzone.lu pour aider les organisateurs de LAN-parties dans leurs tâches.
Site web lanzone.lu en 2004
A côté de THE Wicked NET deux autres communautés avaient été créées à l’époque de la préhistoire eSport et sont entrées dans la scène des jeux vidéo en 2003.
Il s’agit d’abord du Master Computer Club Lëtzebuerg (MCCL : asbl F2793) qui a été fondée le 19 février 1998 par Gilbert Franzetti, Justin Stephany, Monique Schmitz-Schiltz et Patrick Schneider. Les premières pierres du MCCL avaient déjà été posées en janvier 1987 par Alain Theisen et Serge Linckels, en créant le Schneider Master Club. En 2003 et 2004 le MCCL a organisé trois éditions des NetGames à Hagen et à Steinfort.
Le deuxième acteur est l’association LiLux (asbl F2721), le Linux User Group Luxembourg. LiLux a été fondée le 25 juin 1998 par Thierry Coutelier, Pascal Guirsch, Alain Knaff, Alain Rassel, Jean-Paul Gedgen, René Schmit, Charles Lopez, Marcel Hofmann et Frank Segner. Entre 2003 et 2008 LiLux a organisé chaque année un festival Linux luxembourgeois au Lycée de Garçons à Luxembourg, pendant deux jours, qui comportait également une LAN-Party.
Marc Hansen, Patrick Lanners et Jean Chelius ont constitué le 22.12.2003 l’asbl Luxembourg Lan Community (LLC – F342 – www.llc.lu).
llc.lu 2003llc.lu 2004Site web llc.lu de la Luxembourg Lan Community
Dans certains lycées, notamment au Lycée Aline Mayrich (LAML) et à l’Athenée de Luxembourg (AL), des étudiants ont commencé à organiser des LAN-Parties à partir de 2004. Au LAML c’était le Schülerhelpdesk, au AL c’était le computer club ORCA qui étaient à l’initiative.
Site web ORCA en 2005
A partir de 2005 la scène d’organisation des LAN-Parties est devenue plus professionelle. Jeff Wernimont, Petz Melchior et Marc Gerard ont converti le team MLF (Minett LAN Fellowship) en collectif officiel pour organiser plusieurs LAN-Parties par an et pour offrir leur matériel de réseau à d’autres organisateurs.
En décembre 2005, Jerry Kohn (Pegasus), Sven Clement (iSnipeU) et Luc Oth (Th3 LuN4tIc) ont fondé la première fédération de sport électronique (LESF) sous forme d’une asbl (F1345). Elle a été active jusqu’en 2009 et a été radiée au registre de commerce en mars 2020.
Site web du LESF en 2006
Au milieu des années 2000 la scène des LAN-Parties a changé. L’augmentation des raccordements Internet à haute vitesse et la création de la LFES favorisaient les jeux en ligne et la naissance de l’eSport au Luxembourg. Quelques nostalgiques des LAN-Parties classiques ont créé de nouvelles associations et se sont regroupés dans le collectif The3rd pour organiser des événements dans l’atmosphère du passé. Notamment les éditions des LAN-Parties X-MAS et HESE (Hei elei. spill elei) gagnaient une certaine notoriété, mais le nombre des participants n’atteignait plus la barre des événements FragCity et de_lux.LAN.
L’asbl crew2k (F6084) a été fondée le 18 octobre 2006 par Laurent Mander, Olivier Huberty, Robert Hudeck, Yves Schmit, Kevin Otten, Max Wolter, Dany Haas, Chris Biersbach, Ben Schosseler et Rick Hammond. L’association a été radiée au registre de commerce en 2017 suite à une liquidation volontaire.
Site web crew2k.org en 2006
Une année plus tard c’était le tour de MTF Gaming. L’asbl (F7335) a été constituée le 18.6.2007 par Christian Frantz, Yannick Gilson et Christophe Gravé.
Le 14 avril 2010 Alain Bintener, Michel Reuter, Christian Biever, Claude Wolff et Jérome Schiltz ont fondé l’asbl (F8307) Computer Club Gemeng Koplescht (CCGK) qui est encore active aujourd’hui.
Tous ces acteurs passionnés, présentés ci-avant, ont organisé un nombre impressionant de LAN-Parties pendant la période de 1998 à 2010. A l’aide de la machine wayback sur Internet j’ai dressé le tableau ci-après, avec les événements les plus représentatifs :
Liste non-exhaustive des LAN-Parties organisées au Luxembourg entre 1998 et 2010
Quelques organisateurs et participants de la LAN-Party HESE 2 à Kopstal en 2009
Collage de photos prises par les participants des LAN-Parties HESE 2 et HESE 3 à Kopstal
2010 – 2019 : l’eSport passe sur Internet à haute vitesse
Tandis que le collectif The3rd continuait à organiser des LAN-Parties comme Hei elei, spill elei jusqu’en mars 2013 , les efforts entrepris par le gouvernement pour attirer des sociétés actives dans le développement et la commercialisation de jeux en ligne au Luxembourg portaient leurs fruits. Un des premiers était Jimmy Fischer qui a lancé en 2009 sa propre société de production 3WG (B149262) à Altwies. En 2012 il avait développé le jeu Santa Rush pour mobiles Android.
La liste qui suit montre, à côté du studio 3WG, d’autres sociétés qui ont installé une partie plus ou moins importante de leurs activités au Grand-Duché :
Le 13 décembre 2011 LU-CIX avait invité les professionnels du secteur ICT au premier Online Gaming Forum au Luxembourg. Cet événement fut un succès à tout point de vue. Ils étaient finalement plus de 250 à se rassembler lors de ce forum dans les locaux de RTL Group au Kirchberg. Une deuxième édition a eu lieu le 14 novembre 2012 à la LuxExpo.
Ces manifestations se sont adressées aux professionnels du secteur, mais il y avait le souhait des passionnés du sport électronique au Luxembourg de sensibiliser le grand public pour ces activités.
Le 19 avril 2015 Cédric Feyereisen, Sacha Ewen et Sven Molitor ont constitué l’asbl videogames.lu (F10498) ä Kopstal. La composition du comité a été modifiée plusieurs fois. A l’heure actuelle videogames.lu est géré par une équipe d’une trentaine de personnes.
Equipe videogames.lu en 2020
L’asbl Sweetspot (F10487) a été fondée le 12 août 2015 par Thommy Meyer, Darryl Poiré et Alexander Konior. Elle a notammment lancé la Central Smash Series au Luxembourg.
Quelques mois plus tard, Fabio De Aguiar et Dany Fernandes ont fondé en janvier 2016 lune agence spécialisée dans l’organisation de tournois de jeux vidéo, la société 11F qui a été renommée Deralu S.à.r.l. en juin 2021. Une première action était l’organisation du salon luxembourgeois Gaming Experience (LGX) en mars 2016 à Mondorf-les-Bains au Casino 2000 pendant deux jours. Il s’agissait d’un événement qui combinait une exposition avec des activités autour de tout ce qui se réfère aux jeux vidéo, planifié en collaboration avec Eli Lubambu, à l’époque responsable multimédia chez Saturn. C’était le début des festivals eSport. Pour sa première édition LGX avait réuni plus de 2500 visiteurs.
La même année 11F a organisé un salon gaming au centre commercial Belle Etoile pendant la période du 22 au 27 novembre 2016. Le highlight était une grande finale du jeu FIFA 2017 le dimanche dès 10 heures. En 2017 le salon a eu lieu du 21 au 25 novembre au nom de Orange Gaming Week.
Lors de la première édition de la foire SpringBreaks qui remplacait l’ancienne Foire de printemps, le premier salon SprinGames a eu lieu dans ce cadre du 22 au 26 mars 2017 à la LuxExpo the Box. Il s’agissait d’une zone 100% dédié au Gaming avec des jeux vidéo, du Cosplay et des tournois eSport sur scène, donc tout ce qui pouvait rendre les geeks et gamers heureux. Organisé entre autres par Sweetspot, 11F Gaming et l’agence de communication ID, les éditions 2 et 3 se sont déroulées du 21 au 25 mars 2018 et du 14 au 17 mars 2019. Après une absence à cause du Covid les dernières années, la SprinGames était de retour cette année du 10 au 13 mars 2022. Les trois vidéos référencées ci-après reflètent l’atmosphère de ces événements.
SprinGames 2017SprinGames 2018SprinGames 2019
La seconde édition et la troisième édition de LGX ont également eu lieu au Casino 2000, en mai 2017, respectivement en septembre 2018. L’artiste luxembourgeois De fette Petz um Netz, spécialiste du gaming-streaming, a réalisé la vidéo suivante au sujet du salon Gaming Experience 2017.
La grande nouveauté en 2018 était un concours de cosplay, une discipline qui consiste à se déguiser pour se transformer en un personnage de l’univers des séries d’animation japonaise ou du gaming. La session 2018 a été précédée en juin par un marathon de 24 heures sur le jeu Fortnite avec 220 participants.
En 2019 l’événement LGX a eu lieu à LuxExpoTheBox et rassemblait plus de 14.000 personnes lors des deux jours de l’événement.
LGX avait pris de l’ampleur. La surface d’exposition a été quadruplée et le salon s’ouvrait à trois nouveaux univers: la culture japonaise (anime, manga, figurines), la culture pop (cinéma, bandes dessinées) et les mondes imaginaires (science fiction, fantasy, cosplay). L’organisateur, la société 11F, avait organisé à cette occasion également 15 tournois eSport avec des prix pouvant atteindre 15.000 euros. Dans les compétitions on trouvait des jeux populaires comme FIFA 20, Fortnite, Street Fighter V, Mortal Kombat 11, Tekken 7 et Dragon Ball FighterZ, Mario Kart 8 Deluxe et Rocket League.
Lancement du Creative Industries Cluster Luxembourg en 2017 (photo Paperjam)
En 2018 Jérôme Becker était à l’initiative de la pétition No 1077, déposée le 18.7.2018 à la Chambre des Députés, qui avait comme objectif la reconnaissance officielle du sport électronique au Luxembourg par le Gouvernement. Au lieu des 4.500 signatures requises, le nombre de signatures électroniques comptées ne s’élevait qu’à 377, avant et après validation.
> 2020 : l’eSport devient une nouvelle industrie à part entière
Depuis 2020 le Luxembourg est pris de passion pour les grandes compétitions de sport électronique. Comme dans le sport classique, ces compétitions se déroulent pendant une saison en plusieurs étapes, avec des sélections, qualifications, éliminations, finales etc. En général les premiers matchs se font individuellement en ligne sur Internet, tandis que la finale est jouée dans un lieu public devant de nombreux spectateurs. Les images vidéo des compétitions sont diffusées sur Internet par streaming, le plus souvent sur la plateforme Twitch TV (acheté en 2014 par Amazon), accompagnées de commentaires exprimés par des passionnés compétents de l’eSport. Les compétitions sont organisées par des professionnels du secteur, en collaboration avec un partenaire de renom et avec le support de plusieurs sponsors. La sélection des jeux vidéo et des équipements de jeu (console, PC, mobile) se fait en fonction des actualités et des cibles de joeuers. Les prix attribués aux gagnants sont de taille. Pour s’inscrire et pour suivre le statut des compétitions, des sites web spécifiques sont mis en place, souvent en combinaison avec des serveurs Discord, conçus initialement pour les communautés de joueurs de jeux vidéo. A noter qu’il existe également des plateformes complètes de gestion de tournois eSport, comme Toornament, ou des plateformes pour la gestion de clubs, comme CluBee, qui offrent les bons outils aux organisateurs. Ces compétitions ont également favorisé la création de services associés comme des cafés, magasins et équipes de joueurs professionnels, spécialisés dans les jeux vidéo. La culture geek séduit les commerces est le titre d’un article publié en octobre 2021 au Paperjam. A noter qu’un pionnier de cette industrie de création d’accessoires des jeux vidéo, la société Tsume (B151925) implantée à Sandweiler qui fabrique des figurines en polyrésine, inspirées des jeux vidéo, est en train de devenir un des leaders mondiaux dans ce secteur. Les événements récents SprinGames 2022 au Kirchberg et LUXCON/EUROCON 2022 à Dudelange viennent de témoigner de la richesse de cette culture geek.
photo : Vincent Lescautphoto : Vincent Lescautphoto : Vincent Lescaut
Ci-après je vais résumer en ordre chronologique l’évolution de la scène eSport au cours des dernières années.
Au début 2019, les frères Joe et Kevin Hoffmann ont constitué la société à responsabilité limitée simplifiée FWRD S.à r.l.-S (B230850), active dans le domaine du sport et des loisirs, y compris l’eSport.
En février 2020, Nicolas Bouscarat a co-fondé la société Respawn (B242110) qui exploite le Gaming Café (respawn.lu), situé dans la rue du Fort Neipperg. Respawn est organisé en plusieurs styles, avec des tables sur mesure pour les jeux de société ou de rôle, un espace canapé-consoles dernière génération pour être à l’aise comme à la maison, des bornes d’arcade pour des jeux rétros ou encore une pièce pour les jeux de guerre avec figurine et une table pour les PC au premier étage.
En mars 2020, POST Luxembourg avait lancé la première ligue dédiée aux jeux vidéo dans le pays: la POST eSports League. Pour l’occasion, Post s’était associée à la société 11F. Un montant de 20.000 euros était partagé entre les gagnants qui s’affrontaient via trois jeux: League of Legends, FIFA 20 et Clash Royale. La première saison, qui s’était conclue au Kinepolis du Kirchberg en septembre 2020, avait attiré plus de 400 participants et 15.000 visiteurs virtuels sur Twitch lors des finales.
Quelques mois plus tard, une nouvelle fédération luxembourgeoise des sports électroniques (LESF) a été constituée comme asbl (F12890) en juin 2020. Elle est présidée par Joe Hoffmann, les autres fondateurs sont Kevin Hoffmann, Maxime Feretti, Kevin Quintela Morais, Gary Schuller et Yannick Raach. Dans les statuts de l’asbl on peut lire que les membres fondateurs, parmi eux la société FWRD SARL-S gérée par le président, ne sont pas révocables.
En septembre 2020 la LESF a été admise comme membre de la Fédération Internationale d’eSport (IeSF), une organisation mondiale basée en Corée du Sud, qui a été créée en 2008. Outre la promotion et la réglementation du eSport, l’IeSF organise depuis 2009 chaque année un championnat du monde. En 2021 le championnat mondial IeSF a eu lieu à Eilat en Israél. C’était la première fois qu’un athlète luxembourgeois à participé à un championnat eSport.
Nouveaux membres de l’IeSF admis en septembre 2020
En janvier 2022 la LESF a été admise en outre comme membre de la Fédération Européenne d’eSport (EEF), constituée en février 2020 à Bruxelles. Elle fait également partie de la Global Esports Federation, fondée en décembre 2019 à Singapore, qui a une orientation plus commerciale.
Fin 2020, Cliff Konsbruck, directeur de POST Telecom, a annoncé un partenariat avec le fournisseur de jeux vidéo français Blacknut. Dans l’article Cloud Gaming, le rush mondial, écrit par Thierry Labro dans le magazine Paperjam de novembre 2020, les atouts du partenariat avec Blacknut ont été mis en évidence.
En ce qui concerne la cinquième édition de LGX, elle a été annulée à cause du Covid et remplacée par LGX Online, un format 100% numérique qui s’est déroulé du 18 au 20 décembre 2020. Environ 5000 personnes ont participé à cette compétition. En 2021 un circuit esports 100% en ligne et gratuit, ouvert à tous les joueurs européens, avec un Cash Prize total de 10.000€, a été lancé sous le nom LGX Arena. De 1 à 2 tournois sont organisés tous les mois et toutes les compétitions sont streamées et commentées sur Twitch. Pour la deuxième saison, les tournois se focalisent sur les jeux de tir : Apex Legends, Counter Strike: Global Offensive (CS:GO), Valorant, et Call of Duty: Warzone.
Lors de pourparlers entre POST Telecom et LESF au sujet d’une collaboration éventuelle, aucun accord n’a été trouvé. La Fédération eSport s’est tournée alors vers Orange Luxembourg, un des concurrents de POST Telecom. Par communiqué de presse du 16 décembre 2020, Orange et LESF ont annoncé leur partenariat. En février 2021 les deux partenaires ont annoncé le lancement de la première e-ligue FIFA officielle au Luxembourg, en collaboration avec la Fédération luxembourgeoise de football.
Le troisième opérateur luxembourgeois, Tango, ne souhaitait pas être écarté du sport électronique au Luxembourg. Le 27 mars 2001, la compétition Tango High School Cup a démarré. Il s’agissait d’un tournoi, sous forme de huit coupes, qui s’adressait à tous les lycéens scolarisés au Luxembourg. Organisé par l’équipe professionelle d’eSport 4Elements (une filiale de la société FWRD (B230815 ; fwrd.gg), liquidée en septembre 2001), la compétition s’est terminée par une grande finale le 10 juillet 2021, avec l’équivalent de 10.000 euros de récompenses.
Comme il y avait un certain malaise au sein de la communauté eSport au Luxembourg à cause des activités commerciales de la fédération LESF, une deuxième fédération pour l’eSport, appelée Fédération Luxembourgeoise d’Esport (FLES ; F13180), a été fondée le 21 février 2021. Les membres se disent indépendants et affirment être des passionnés actifs des jeux vidéo depuis longtemps qui souhaitent fédérer et les amateurs et les professionnels du sport électronique au Luxembourg. Le comité actuel se compose des membres suivants :
Jeremy Chiampan (président), project manager de LGX
Lizi Meyers (vice-présidente)
Nathan Back (trésorier)
Noah Canais (secrétaire)
Max de Ridder (membre)
Thommy Meyer (membre)
Les membres participent aux organisations des événements LGX, Central Smash Series et SprinGames qui ont été pésentés ci-avant. Ils viennent de lancer le League of Legends Luxembourg Tour. La FLES a entamé une collaboration avec POST Telecom qui figure maintenant comme partenaire principal.
Au début 2021, la compétition eSport de POST Telecom a changé de format et a été renommée Post eSports Masters. Il y avait de nouveau 400 participants et plus que 25.000 spectateurs en ligne. La troisième saison a démarré en décembre 2021. Le jeu League of Legends a été remplacé par Rocket League. Depuis fin janvier 2022 les intéressés peuvent suivre chaque samedi dès 17h00 les meilleurs jeux sur la plate-forme Twitch.
La deuxième saison de la ligue Orange a débuté fin janvier 2022. Si pour la première ligue en 2021 seulement les 32 clubs de la division nationale et de la promotion d’honneur ont été admis, l’ensemble des membres de la FLF, soit 103 clubs, pourront prendre part au deuxième championnat.
Quant a Tango, la deuxième édition du High School Cup a commencé le 26 mars 2022, en partenariat avec FWRD, et avec le support de nombreux sponsors.
L’organisation des compétitions eSport par les trois opérateurs de télécommunications luxembourgeois est à l’origine d’une avalanche de fondation d’associations sans but lucratif dans le domaine des jeux électroniques par des teams de joueurs. Une liste représentative est fournie ci-après :
Brotherhood of the Red Lion (botrl ; F12261 ; 1.1.2019) Alexandre Godefroid, Richard Godefroid, Luis Miguel Belchior Miranda, Manuel Antonio De Cruz Barreiro, Lee Scholtes, Patrick Baumgartner, Toufik Loughlimi, André Feliciano Da Silva Rodrigues, Carlos Alberto Campos Moreira
Duxedom E-Sports (F12800 ; 16.3.2020) liquidation volontaire le 6.12.2021
Nocturnal E-Sports (F13101 ; 25.11.2020) : Sam Burquel, Sacha Doemer, Christophe Garcia, Sam Hochmuth, Kevin Kries, Liz Meyers, Sam Michels, Laetitia Santos Felix, Charles Albert Wolter
C1 Esports (F13313 ; 14.7.2021) : Sven Bill, Romain Rossi, Patrick Domnanovits, Jennifer Domnanovits
RelyOn Esports (F13332 ; 5.8.2021) : Metty Kapgen, Felix Schoellen, Pol Greischer, PolFrank Kremer, Christophe André Lech
Sentient Esports (F13416 ; 11.10.2021) : Sacha Weichel, Tamara Santos-Nobre Weichel, Patrick Bührer, Maja Rathmann
Royal Family Esports (F13431 ; 29.10.2021) : Nikola Bogdanovic, Shawn Gindt, Kenneth Roeser
Le mot de la fin
Lors d’une exploration du site web du réseau social professionnel LinkedIn, on découvre que de nombreux pionniers du sport électronique au Grand-Duché occupent aujourd’hui des fonctions de haut niveau dans l’industrie, les services et la recherche, dans le pays ou à l’étranger.
Luxembourg est probablement le seul pays qui disposait déjà d’une fédération de sport électronique au milieu des années 2000 et qui dispose à l’heure actuelle de deux fédérations eSport. Si on considère en outre que Daniel Araujo (Diffside45), de nationalité luxembourgeoise, a remporté la cinquième place au championnat mondial eFootball, qui a eu lieu à Eilat en Israel du 16 au 18 novembre 2021, il ne faut plus dire que l’eSport est en plein essor, sauf au Luxembourg.
En explorant l’histoire de l’évolution des nouvelles technologies, on découvre parfois des phénomènes qui se répètent, avec des similitudes stupéfiantes. C’est par exemple l’évolution des ordinateurs personnels à partir de 1980 et des téléphones mobiles vingt ans plus tard.
Dans les deux cas on avait au début une panoplie de différents constructeurs, avec des produits innovants, qui se partageaient le marché. Ensuite un nouveau entrant perturbait le marché de manière à évincer tous les anciens leaders et à couronner un deuxième acteur comme grand gagnant.
Dans le cas des ordinateurs personnels le nouvel entrant était IBM avec le lancement du PC en 1981. Mais comme de nombreux constructeurs ont développé dans la suite des compatibles PC, le grand gagnant était Microsoft, comme fournisseur des licences Windows, et IBM est sortie perdant. Parmi les constructeurs de la première heure seul Apple a survécu. Les autres comme Atari, Commodore, Sinclair etc ont tous disparu.
Dans le cas des téléphones mobiles le nouvel entrant était Apple avec le lancement de l’iPhone en 2007. Mais comme la majorité des fournisseurs de téléphones mobiles a adhéré ensuite au consortium OHA (Open Handset Alliance), le grand gagnant était Google qui était à l’initiative de cette alliance. Presque tous les constructeurs de téléphones mobiles de l’époque comme Nokia, Ericsson, Blackberry, Microsoft ont abandonné leurs propres systèmes d’exploitation (Symbian, Windows Mobile, …) ou ont cessé leurs activités de fabrication de mobiles.
Dans les deux cas Apple a réussi à sortir son épingle du jeu, toutefois avec des hauts et des bas dans l’histoire de la société. Mais la part de marché de Apple reste faible dans les deux domaines, sauf au Luxembourg. Au niveau mondial le Luxembourg range en deuxième position pour les ordinateurs Mac, après la Suisse, et au premier rang pour la pénétration des iPhones. En 2018 le nombre des appareils Apple dépassait même le nombre des appareils Android au Luxembourg, mais la part de marché a baissé dans la suite à 44%.
Le tableau qui suit donne un aperçu de la comparaison :
critère
ordinateurs
téléphones mobiles
architecture
Motorola RISC 68K
Intel CISC x64
OS propriétaire
OS commun
qualification
innovant & efficace
universel & complexe
innovant & varié
source ouverte
système
fermé
ouvert
fermé
ouvert
grands perdants
Atari, Commodore, Sinclair, …
IBM
Nokia, Ericsson, Blackberry, …
Microsoft
grands gagnants
Apple
Microsoft
Apple
Google
produit phare
Mac
Windows
iPhone
Android
part de marché global 2022
8%
92%
14%
86%
part de marché Luxembourg 2022
16%
84%
44%
56%
Quelles leçons tirer de cette analyse historique ?
Les produits les plus innovants n’ont pas nécessairement le plus grand succès.
L’union fait la force : il est difficile de se battre contre une alliance.
Suite à mes premières expériences avec l’apprentissage profond (deep machine learning) pour réaliser un système de synthèse vocale pour la langue luxembourgeoise, dont les résultats ont été publiés sur mon blog “Mäi Computer schwätzt Lëtzebuergesch“, j’ai constaté que le recours au seul corpus de données Marylux-648 ne permet pas d’entraîner un meilleur système que le modèle VITS, présenté le 6 janvier 2022. Il fallait donc étendre la base de données TTS (text-to-speech) luxembourgeoise pour améliorer les résultats.
Le ZLS (Zentrum fir d’Lëtzebuerger Sprooch) m’a offert sa collaboration pour enregistrer un texte d’envergure par deux orateurs, l’un féminin, l’autre masculin, dans son studio d’enregistrement. Comme un tel projet demande de grands efforts, j’ai proposé d’explorer d’abord tous les enregistrements audio, avec transcriptions, qui sont disponibles sur le web. Une telle approche est typique pour le Grand-Duché de Luxembourg : réaliser des grands exploits avec un minimum de moyens.
Une première source pour l’extension du corpus TTS constitue les dictées luxembourgeoises publiées sur le site web infolux de l’Institut de linguistique et de littératures luxembourgeoises de l’Université du Luxembourg, dirigé par Pr Peter Gilles. Avec l’accord aimable de tous les ayants droit, j’ai converti les fichiers audio et texte de ces dictées dans un format qui convient pour l’apprentissage profond, avec les mêmes procédures que celles décrites dans mon dépôt Github Marylux-648.
Pour faciliter l’apprentissage du corpus TTS luxembourgeois étendu, j’ai seulement retenu les dictées lues par des orateurs féminins. Heureusement c’est le cas pour la majorité des dictées. Les oratrices sont Caroline Doehmer, Nathalie Entringer et Sara Martin.
Les résultats sont les suivants:
10 Übungsdictéeën : 179 échantillons, 2.522 mots, ca 26 minutes
100 Sätz : 100 échantillons, 1.117 mots, ca 9 minutes
Walfer-Dictéeën : 78 échantillons, 1.177 mots, ca 9 minutes
Ensemble avec Marylux-648, la nouvelle base de données TTS comprend 1005 échantillons, avec quatre voix. J’appelle ce corpus “Luxembourgish-TTS-Corpus-4-1005”. Dans une première étape j’ai utilisé ces données pour entraîner le modèle COQUI-TTS-VITS-multispeaker à partir de zéro.
Entraînement TTS avec quatre voix à partir de zéro
Après 32.200 itérations, les métriques des performances du modèle, affichés régulièrement dans les logs lors de l’entraînement, n’ont plus progressé. Mais comme lebest_model.pth.tar, sauvegardé à cette occasion, n’est pas nécessairement le plus performant pour la synthèse de textes luxembourgeois inconnus, j’ai continué l’entraînement jusqu’à 76.000 itérations. Le checkpoint le plus avancé est dénommé checkpoint_76000.pth.tar.
Lors de la synthèse vocale, il faut spécifier non seulement le texte à parler, le fichier de configuration, le fichier du modèle TTS et le nom du ficher audio à sauvegarder, mais également la voix à utiliser pour la synthèse. Comme dans mes expériences précédentes, j’ai utilisé la fable “De Nordwand an d’Sonn” comme texte à synthétiser. A titre d’information j’indique un exemple de commande entrée dans le terminal linux pour procéder à la synthèse.
tts --text "An der Zäit hunn sech den Nordwand an d’Sonn gestridden, wie vun hinnen zwee wuel méi staark wier, wéi e Wanderer, deen an ee waarme Mantel agepak war, iwwert de Wee koum. Si goufen sech eens, datt deejéinege fir dee Stäerkste gëlle sollt, deen de Wanderer forséiere géif, säi Mantel auszedoen. Den Nordwand huet mat aller Force geblosen, awer wat e méi geblosen huet, wat de Wanderer sech méi a säi Mantel agewéckelt huet. Um Enn huet den Nordwand säi Kampf opginn. Dunn huet d’Sonn d’Loft mat hire frëndleche Strale gewiermt, a schonn no kuerzer Zäit huet de Wanderer säi Mantel ausgedoen. Do huet den Nordwand missen zouginn, datt d’Sonn vun hinnen zwee dee Stäerkste wier." --use_cuda True --config_path /media/mbarnig/T7/lb-vits-multispeaker/vits_vctk-January-21-2022_07+56AM-c63bb481/config.json --model_path /media/mbarnig/T7/lb-vits-multispeaker/vits_vctk-January-21-2022_07+56AM-c63bb481/checkpoint_76000.pth.tar --out_path /media/mbarnig/T7/lb-vits/vits_vctk-January-21-2022_07+56AM-c63bb481/walfer_checkpoint_76000.wav --speakers_file_path /media/mbarnig/T7/lb-vits-multispeaker/vits_vctk-January-21-2022_07+56AM-c63bb481/speakers.json --speaker_idx "VCTK_walfer"
Je vais présenter ci-après les auditions pour les différents cas de figure :
Voix “Judith”
Voix “Judith” : best_model à 32200 itérations (648 échantillons pour l’entraînement)Voix “Judith” : checkpoint à 76000 itérations (648 échantillons pour l’entraînement)
Voix “Caroline”
Voix “Caroline” : best_model à 32200 itérations (179 échantillons pour l’entraînement)Voix “Caroline” : best_model à 76000 itérations (179 échantillons pour l’entraînement)
Voix “Sara”
Voix “Sara” : best_model à 32200 itérations : (100 échantillons pour l’entraÎnement)Voix “Sara” : checkpoint à 76000 itérations : (100 échantillons pour l’entraÎnement)
Voix “Nathalie”
Voix “Nathalie” : best_model à 32200 itérations (78 échantillons pour l’entraînement)Voix “Nathalie” : checkpoint à 76000 itérations (78 échantillons pour l’entraînement)
Même si les résultats sont impressionnants à la première écoute, il ne s’agit pas encore de l’état d’art en matière d’apprentissage profond pour la création d’un modèle de synthèse vocale.
Entraînement TTS avec quatre voix et apprentissage par transfert
Un des atouts des réseaux neuronaux qui sont à la base de l’apprentissage profond des machines est l’apprentissage par transfert (transfer learning). Wikipedia le décrit comme suit :
L’apprentissage par transfert est l’un des champs de recherche de l’apprentissage automatique qui vise à transférer des connaissances d’une ou plusieurs tâches sources vers une ou plusieurs tâches cibles. Il peut être vu comme la capacité d’un système à reconnaître et appliquer des connaissances et des compétences, apprises à partir de tâches antérieures, sur de nouvelles tâches ou domaines partageant des similitudes.
Dans le cas de la synthèse vocale, l’apprentissage par transfert consiste à utiliser un modèle TTS, entraîné avec une large base de données dans une langue à ressources riches, pour l’entraîner dans la suite avec une petite base de données dans une langue à faibles ressources, comme le Luxembourgeois.
La communauté COQUI-TTS partage un modèle TTS-VITS anglais, entraîné avec le corpus VCTK pendant un million d’itérations et avec un large jeu de phonèmes IPA, y compris ceux que j’ai retenu pour mes modules de phonémisation luxembourgeoise gruut et espeak-ng. La base de données de référence VCTK comprend environ 44.000 échantillons, prononcés par 46 orateurs et 63 oratrices.
J’ai téléchargé ce modèle tts_models–en–ljspeech–vits et j’ai continué son entraînement avec ma base de données “Luxembourgish-TTS-Corpus-4-1005”. Le best_model.pth.tar a été sauvegardé à 1.016.100 itérations. Après mon interruption de l’entraînement, le dernier checkpoint a été enregistré à 1.034.000 itérations. Je présente ci-après seulement les auditions des synthèses réalisées avec ce checkpoint.
Voix “Judith”
Voix “Judith” : : checkpoint à 1.034.000 itérations (648 échantillons pour l’entraînement)
Voix “Caroline”
Voix “Caroline” : checkpoint à 1.034.000 itérations (179 échantillons pour l’entraînement)
Voix “Sara”
Voix “Sara” : checkpoint à 1.034.000 itérations : (100 échantillons pour l’entraÎnement)
Voix “Nathalie”
Voix “Nathalie” : checkpoint à 1.034.000 itérations (78 échantillons pour l’entraînement)
Spécifications techniques
Contrairement à ma première contribution “Mäi Computer schwätzt Lëtzebuergesch“, je n’ai pas présenté des détails techniques dans le présent rapport pour faciliter la lecture. Je vais toutefois publier prochainement les graphiques, métriques et autres caractéristiques techniques en relation avec les entraînements sur mon dépôt Github Luxembourgish-TTS-Corpus-4-1005. Avis aux amateurs des technologies de l’intelligence artificielle.
Conclusions
Les résultats obtenus avec l’apprentissage par transfert donnent envie à parfaire le modèle de synthèse vocale luxembourgeois. Plusieurs pistes restent à creuser :
création d’une base de données TTS luxembourgeoise multi-voix plus large avec les contenus audio et texte disponible sur le site web de RTL-Radio. Un grand Merci aux responsables de RTL qui m’ont autorisé à utiliser les ressources afférentes pour constituer un tel corpus.
utilisation d’un modèle TTS pré-entraîné avec une large base de données allemande, au lieu du modèle TTS anglais, pour l’apprentissage par transfert
utilisation d’un modèle TTS pré-entraîné multi-voix et multilingue pour l’apprentissage par transfert
perfectionnement du modèle de phonémisation luxembourgeoise
réalisation de tests avec d’autres architectures de modèles TTS
En parallèle à mes expériences de création d’un système de synthèse vocale luxembourgeoise, j’ai démarré les premiers essais avec un système de reconnaissance de la langue luxembourgeoise (STT : speech to text) avec transcription automatique, en utilisant mes bases de données TTS luxembourgeoises, converties dans un format approprié. Les premiers résultats sont encourageants.
Application interactive de démonstration
J’ai publié le 12 juillet 2022 une application interactive étendue multilingue et multivoix lb-de-en-fr-pt-COQUI-STT de mon modèle sur la plateforme d’intelligence artificielle Huggingface.