
Ech hunn an de leschten Deeg déi éischt Applikatioun déi et jidder Mënsch erlaabt geschwate lëtzebuergesch Sprooch an en Text ëmzewandelen op Häerz an Nieren gepréift. Ech kann et am Virfeld schonns soen : schreifmaschinn.lu kritt 5 Stären. Fir dass eis auslännesch Frënn, déi nach keen Lëtzebuergesch schwätzen, och verstinn wéi eng Meeschterleeschtung hei geschaaft gouf, fueren ech elo mat menger Beschreiwung op Franséisch weider.
Présentation du projet schreifmaschinn.lu
Le vendredi 9 décembre 2022 le Zenter fir d’Lëtzebuerger Sprooch (ZLS) a présenté dans la salle de conférence à Clausen une application web qui permet de dicter du texte en luxembourgeois, en présence de Claude Meisch, ministre de l’Éducation Nationale, de l’Enfance et de la Jeunesse. Luc Marteling, directeur du ZLS, a souhaité la bienvenue aux nombreux invités.
L’application de reconnaissance vocale, appellée schreifmaschinn.lu, est basée sur un modèle neuronal d’intelligence artificielle (AI) et a été développée par Sven Collette et Le Minh Nguyen. Elle constitue une vraie prouesse technologique si on considère que le luxembourgeois est une langue à faible ressources et que le modèle AI a été entraîné avec une quantité de données limitée.

Le duo de développement
Sven Collette est linguiste informatique au ZLS. Après sa formation en neurosciences à Munich (Université Louis-et-Maximilien) et Lausanne (Ecole polytechnique Fédérale), il a obtenu un doctorat de philosophie en neurosciences à l’université Pierre et Marie Curie à Paris. Il a travaillé de 2012 à 2016 comme chercheur postdoctoral à l’institut de technologie de Californie (CALTECH) à Pasadena. Dans la suite il a été consultant et chercheur dans le domaine de l’intelligence artificielle, avant de joindre le ZLS au début de 2021.
Le Minh Nguyen vient d’obtenir son master en sciences des technologies vocales à l’université de Groningen avec distinction cum laude. En 2021 il a réussi son bachelor à l’université du Luxembourg avec la mention très bien. Dans le cadre du programme Erasmus il a passé un semestre à l’université technique de Vienne. Il a démarré le développement du projet de reconnaissance vocale du luxembourgeois dans le cadre de ses études. Actuellement Le Minh Nguyen travaille à distance comme chercheur/programmeur pour la société Deepgram à San Francisco, spécialisée dans les plateformes vocales intelligentes.
Des informations supplémentaires au sujet du développement sont fournies sur la page d’accueil du site web schreifmaschinn.lu.
Les outils de reconnaissance vocale
En jargon technique les outils de reconnaissance de la voix sont appelés STT (Speech-to-Text) ou ASR (Automatic Speech Recognition). Un vétéran parmi les outils ASR est le projet KALDI qui a démarré en 2009 à l’université Johns-Hopkins. Aujourd’hui des géants du web comme Google, Microsoft, AWS, etc, proposent des services commerciaux de reconnaissance de la voix en ligne pour de nombreux langages. Ils ne sont toutefois pas intéressés aux langues à faibles ressources comme le luxembourgeois. D’autres géants comme Meta (Facebook) et des startup’s comme OpenAI et Coqui.ai ont développé des modèles à source ouverte qu’ils mettent à disposition de la communauté des chercheurs. L’état d’art actuel consiste à entraîner des larges réseaux neuronaux avec plusieurs langues et avec des millions de paramètres pour faire ensuite un réglage fin (fine-tuning) de ces modèles avec un entraînement supplémentaire pour une langue spécifique. Parmi les modèles à source ouverte il convient de relever les plus importants que je vais présenter plus en détail dans les prochains chapitres :
- Wav2Vec de Meta (Facebook Research) (juin 2019)
- Coqui-STT de Coqui.ai (mars 2021)
- Whisper de OpenAI (septembre 2022)
Modèle Wav2Vec2
Le modèle wav2vec, développé par le laboratoire de recherche de Facebook (meta.ai), est le plus ancien et le plus connu des modèles ASR. Rien que sur la plateforme AI Huggingface on trouve 4.430 versions pré-entraînées de ce modèle, comme témoigne l’image ci-après:
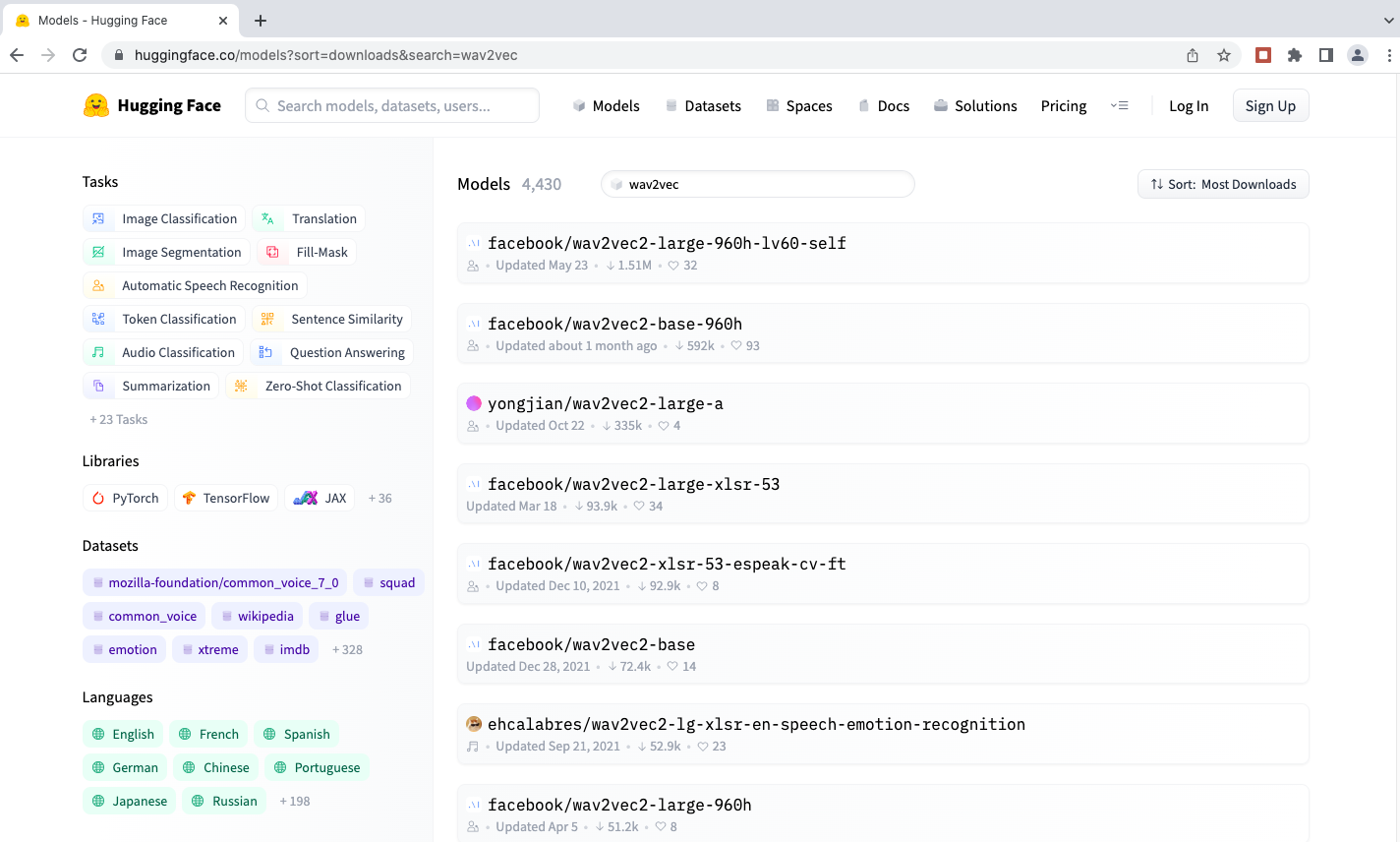
La version Wav2Vec2-XLSR-53 de ce modèle, publiée en décembre 2020, a été utilisée par Le Minh Nguyen. Elle a été pré-entraînée par Meta avec 56.000 heures d’enregistrements audio sans transcriptions en 53 langues, mais sans le luxembourgeois. Dans sa thèse de fin d’études Le Minh Nguyen présente les détails de son développement. Il a entraîné le modèle Wav2Vec2-XLSR-53 avec 842 heures d’enregistrements audio luxembourgeois sans transcriptions (unlabeled speech) et avec 14 heures d’enregistrements audio avec textes synchronisés (labeled speech). Un modèle de langage 5-gram, entraîné avec des textes luxembourgeois totalisant 20 millions de mots, a été ajouté au décodeur vocal. Les enregistrements audio et les textes ont été fournis par la Chambre des Députés et par RTL.
Une version plus récente du modèle, XLS-R, pré-entraîné avec 436.000 heures d’enregistrements audio en 128 langues, incluant le luxembourgeois, a été présentée par Facebook (meta.ai) en décembre 2021. A partir du début 2022, Peter Gilles, professeur de langage et linguistique et directeur du département Humanités à la faculté des Sciences Humaines, des Sciences de l’Éducation et des Sciences Sociales (FHSE) de l’université du Luxembourg, a développé le premier prototype d’une application de reconnaissance vocale luxembourgeois basée sur ce modèle. Il a présenté ses résultats en mai 2022 sur le site web Infolux de l’université du Luxembourg avec l’attribut “A very first model“. En février 2022 il avait déjà publié un premier espace de démonstration de ce modèle sur la plateforme Huggingface qui pouvait être testé par des initiés.
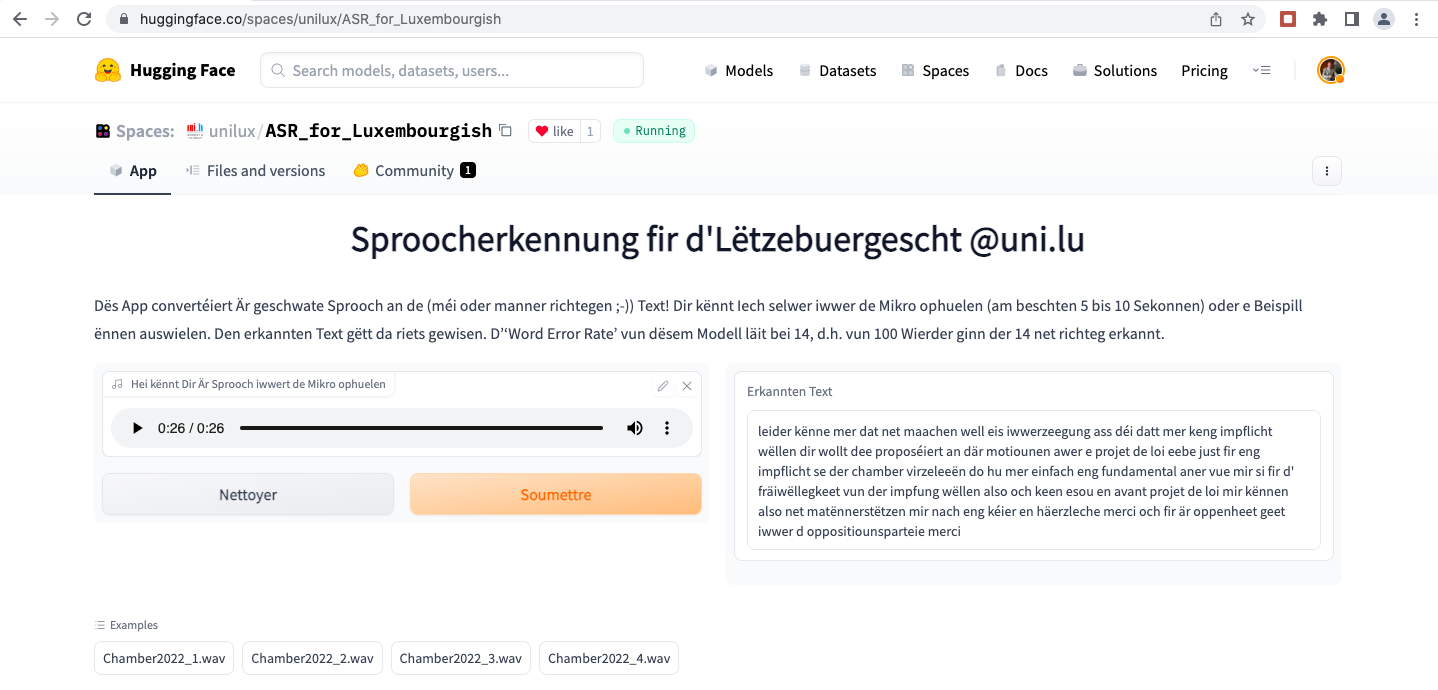
Cette application incluait également un modèle de langage n-gram, mais ne supportait pas encore l”usage des lettres majuscules pour les substantifs. Elle n’atteignait pas le niveau des résultats qu’on obtient avec l’application schreifmaschinn.lu actuelle, mais c’était un jalon dans le développement des technologies de la voix au Luxembourg.
Pour l’application schreifmaschinn.lu, le modèle XLS-R a également servi de base. Pour l’entraînement du luxembourgeois, la durée des enregistrements audio avec transcriptions a été étendue à 16 heures. Elle sera portée prochainement à 100 heures.
Modèle Coqui-STT
La fondation Mozilla, qui est surtout connue pour son navigateur Firefox, est également un pionnier de la synthèse (Mozilla TTS) et de la reconnaissance (Mozilla-Deepspeech) de la parole. Mozilla a lancé en juillet 2017 le projet Common Voice pour collecter de vastes échantillons de données vocales. Hélas le luxembourgeois ne fait pas encore partie des langues supportées. En août 2021 la CEO de Mozilla informait son personnel que les activités de technologie de la voix seraient abandonnées au profit d’une focalisation sur Firefox. 250 personnes ont été licenciées. Dans la suite quelques anciens employés de Mozilla ont fondé en mars 2021 la start-up Coqui.ai sur les ruines des anciens projets vocaux de Mozilla. Les idées avancées par les fondateurs m’avaient incité à reprendre mes anciens travaux de développement d’une voix synthétique luxembourgeoise. J’ai résumé cette histoire en juin 2021 dans mes contributions “Text-to-Speech sound samples from Coqui-TTS” et “The best of two breeds” sur mon site web.
Les premiers résultats tangibles étaient prêts en janvier 2022 et ont été publiés sur mon site web dans les articles “Mäi Computer schwätzt Lëtzebuergesch” et “Mäi Computer schwätzt Lëtzebuergesch mat 4 Stëmmen“. En juillet 2022 j’ai publié sur Huggingface un espace de démonstration TTS multilingue et multi-orateur, incluant le luxembourgeois, qui a été très apprécié par la communauté Coqui.ai.
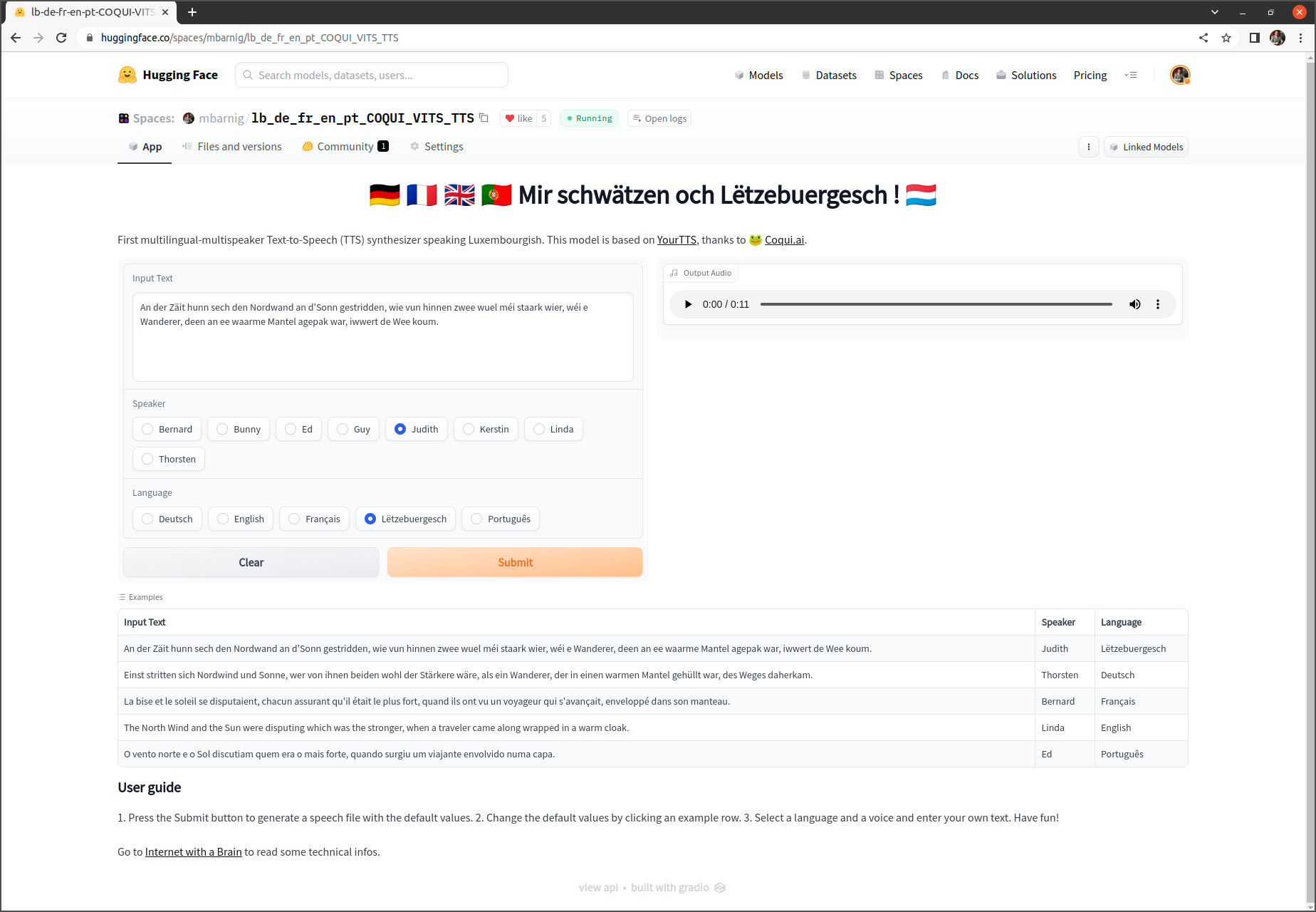
Au printemps 2022, dans l’attente d’une correction de quelques bogues dans les modèles Coqui-TTS, je me suis focalisé sur la reconnaissance vocale du luxembourgeois moyennant le modèle Coqui-STT. J’ai décrit en juin 2022 mes expériences dans mon récit “Mäi Computer versicht Lëtzebuergesch ze verstoen” et j’ai publié fin juillet 2022 un modèle STT multilingue “Mir verstinn och Lëtzebuergesch !” sur la plateforme d’intelligence artificielle Huggingface. Je viens toutefois me rendre compte que cette application ne fonctionne plus correctement après une mise à jour de la plateforme.
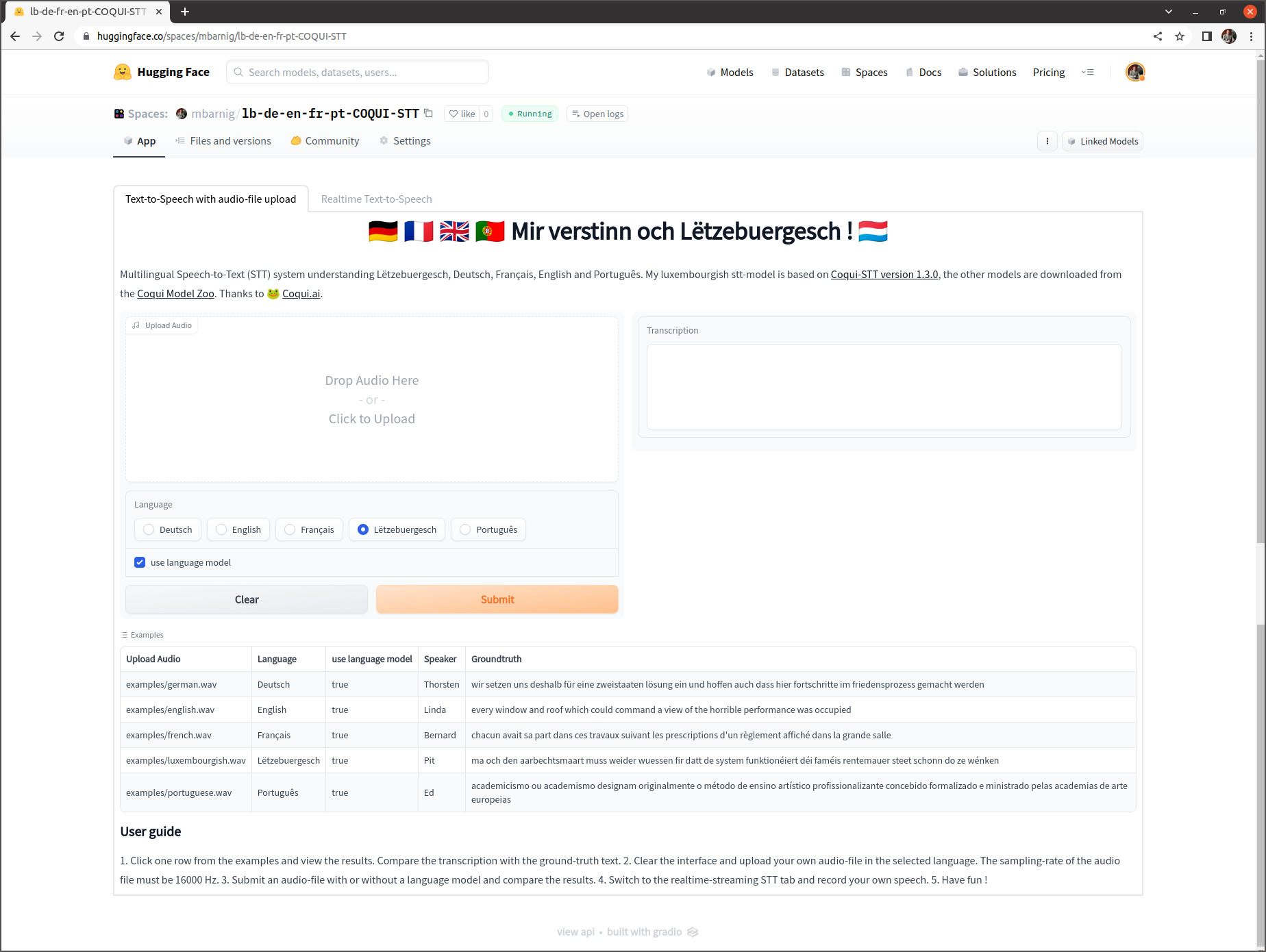
Vu les performances du modèle schreifmaschinn.lu et le potentiel du modèle Whisper présenté dans le prochain chapitre, la poursuite du développement d’un modèle Coqui-STT luxembourgeois ne fait plus de sens. Je vais me concentrer de nouveau sur le perfectionnement d’une voix luxembourgeoise avec la synthèse vocale Coqui-TTS.
Modèle Whisper
Le modèle de reconnaissance vocale pré-entraîné le plus récent s’appelle Whisper et a été présenté par la société OpenAI le 21 septembre 2022 et amélioré en décembre 2022 (version 2). OpenAI a été fondée en décembre 2015 comme organisation à but non lucratif avec l’objectif de promouvoir et de développer une intelligence artificielle à visage humain qui bénéficiera à toute l’humanité. Parmi les fondateurs se trouve Elon Musk, entrepreneur et milliardaire emblématique. L’organisation a été convertie en entreprise à but lucratif plafonné en mars 2019. OpenAI est surtout connue pour ses applications récentes Dall-E2 et ChatGPT qui font ravage sur le web.
Whisper a été entraîné avec 680,000 heures d’enregistrements audio avec transcriptions, dont 83% en anglais et 17% avec 96 langues différentes. Lors de la présentation du projet schreifmaschinn.lu Peter Gilles m’a informé qu’il s’est lancé dans l’adaptation de Whisper au luxembourgeois. Il y a quelques jours j’avais découvert les premières traces afférentes sur la plateforme Huggingface.
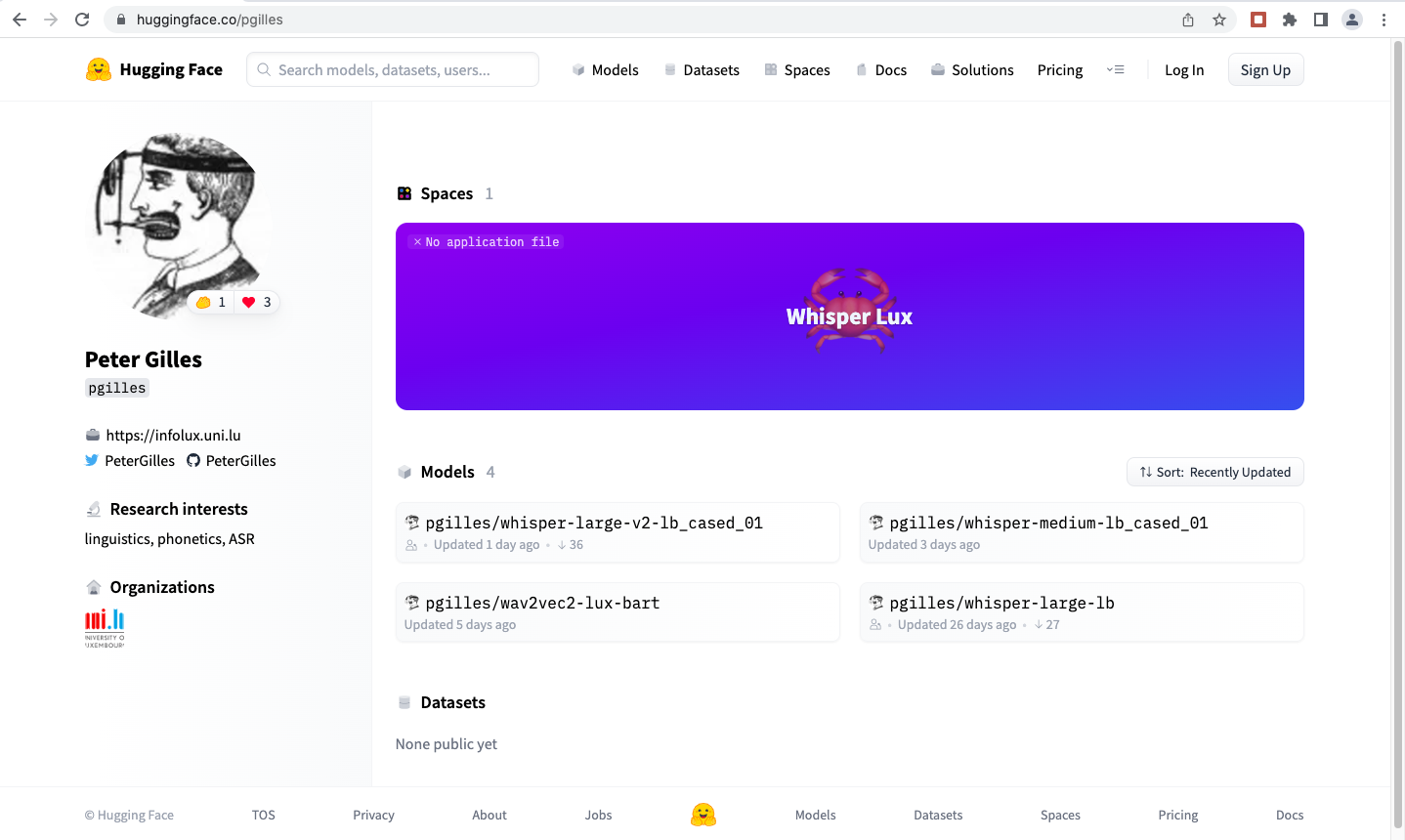
Aujourd’hui j’ai constaté que cette application est maintenant opérationnelle sur Huggingface et tourne sur une infrastructure GPU T4. A première vue les performances de ce modèle sont géniales.
Je vais tester cette version plus en détail dans les prochains jours, avec les mêmes jeux de tests que j’ai utilisé pour le projet schreifmaschinn.lu, et rapporter sur mes expériences.
Au rythme effréné actuel de l’évolution de l’intelligence artificielle, on va bientôt savoir si Whisper a le potentiel de détrôner le modèle Wav2Vec-XLS-R dans l’application schreifmaschinn.lu. De toute façon, se sont les données luxembourgeoises audio, avec les transcriptions soigneusement corrigées et assemblées, ainsi que l’expérience gagnée jusqu’à présent, qui constituent la vraie valeur d’un projet de reconnaissance vocale, et non l’architecture du réseau neuronal à la base.
Mise à l’épreuve de l’application schreifmaschinn.lu
Pour tester la qualité de reconnaissance de l’application schreifmaschinn.lu d’une façon reproductible j’ai utilisé trois jeux d’enregistrements pour mesurer la qualité de reconnaissance des mots transcrits :
- Fichiers audio enregistrés en studio
- Fichiers audio enregistrés en salle de réunion
- Fichiers audio enregistrés à la maison
Enregistrements en studio
J’ai sélectionné au hasard des enregistrements luxembourgeois dans mon corps de paroles multilingues TTS-12800, publié en juillet 2022 sur Huggingface. Ces enregistrements proviennent de dictées et d’histoires disponibles sur le site web de l’université du Luxembourg et d’émissions radio disponibles sur le site web de RTL. Ces enregistrements se distinguent par une très bonne qualité. Pour garder un équilibre entre hommes et femmes, j’ai choisi les fichiers audio de test parmi les contributions de 4 oratrices et de 4 orateurs, avec les transcriptions originales. Les enregistrements ont tous une durée inférieure à 10 secondes et sont échantillonnés avec une fréquence de 16 KHz. Les transcriptions ont été corrigées manuellement.
Enregistrements en salle de réunion
Il s’agit de six enregistrements de discours à la Chambre des Députés que Peter Gilles a utilisé pour le test de son premier modèle ASR luxembourgeois XLS-R. J’ai édité ces fichiers pour créer des enregistrements d’une durée maximale de 30 secondes. J’ai créé moi-même des transcriptions de référence. Il faut dire que même pour un humain c’est un exercice difficile car dans ces enregistrements on trouve des termes exotiques et des défauts d’élocution et il faut parfois deviner ce que le député voulait dire. J’ai généré des fichiers avec différentes fréquences d’échantillonnage et constaté que la reconnaissance des mots diffère en fonction de ce paramètre. Dans certains cas la version originale produit les meilleurs résultats, dans d’autres cas c’est la version avec un échantillonnage réduit à 8KHz qui est la plus compréhensible. Je n’ai toutefois pas pu déceler une dépendance systématique entre résultats et fréquence d’échantillonnage et j’ai finalement utilisé les versions originales, échantillonnées à 44,1 KHz respectivement à 16 KHz.
Enregistrements à la maison
J’ai enregistré et édité moi-même les fichiers audio pour le troisième jeu de test avec l’application Voice Memos sur mon iPhone. Comme référence, j’ai lu la fable d’Esope De Nordwand an d’Sonn dans un environnement calme. Ensuite j’ai édité ce fichier audio pour le couper en deux morceaux ayant des durées inférieures à 30 secondes. Ensuite j’ai ajouté du bruit de fond avec différentes intensités. Dans un premier cas on entend comme bruit de fond mes petits-enfants qui s’amusent avec des jeux vidéo sur iPAD. Dans le deuxième cas un sèche-cheveux perturbe l’enregistrement.
Evaluation des résultats de mes tests
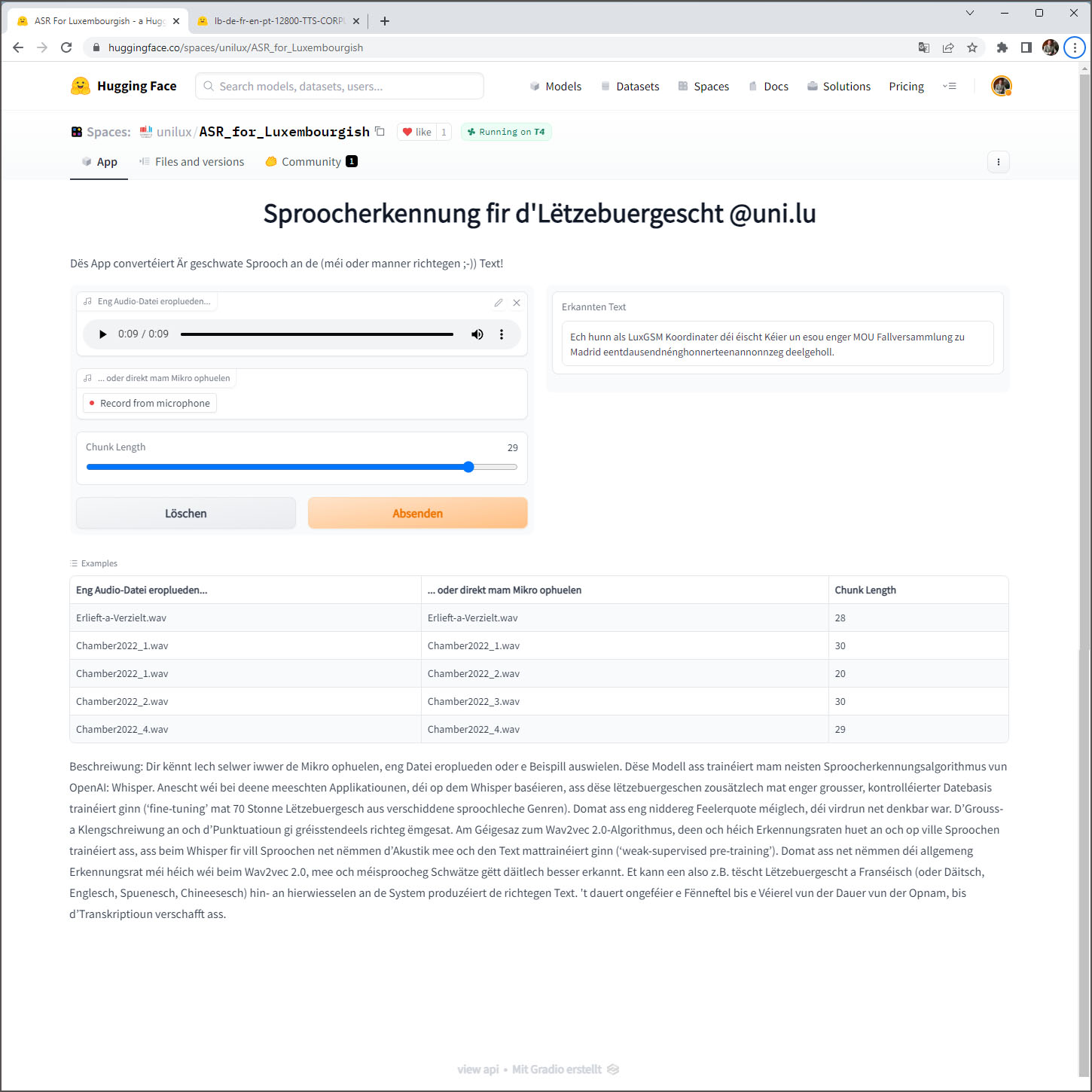
Pour tester l’application schreifmaschinn.lu, j’ai téléchargé (upload) les différents enregistrements, un après l’autre, sur la page web listen. Ensuite j’ai copié la transcription affichée sur cette page, avec le bouton copier/coller, dans un éditeur de texte, pour le comparer avec la transcription de référence.
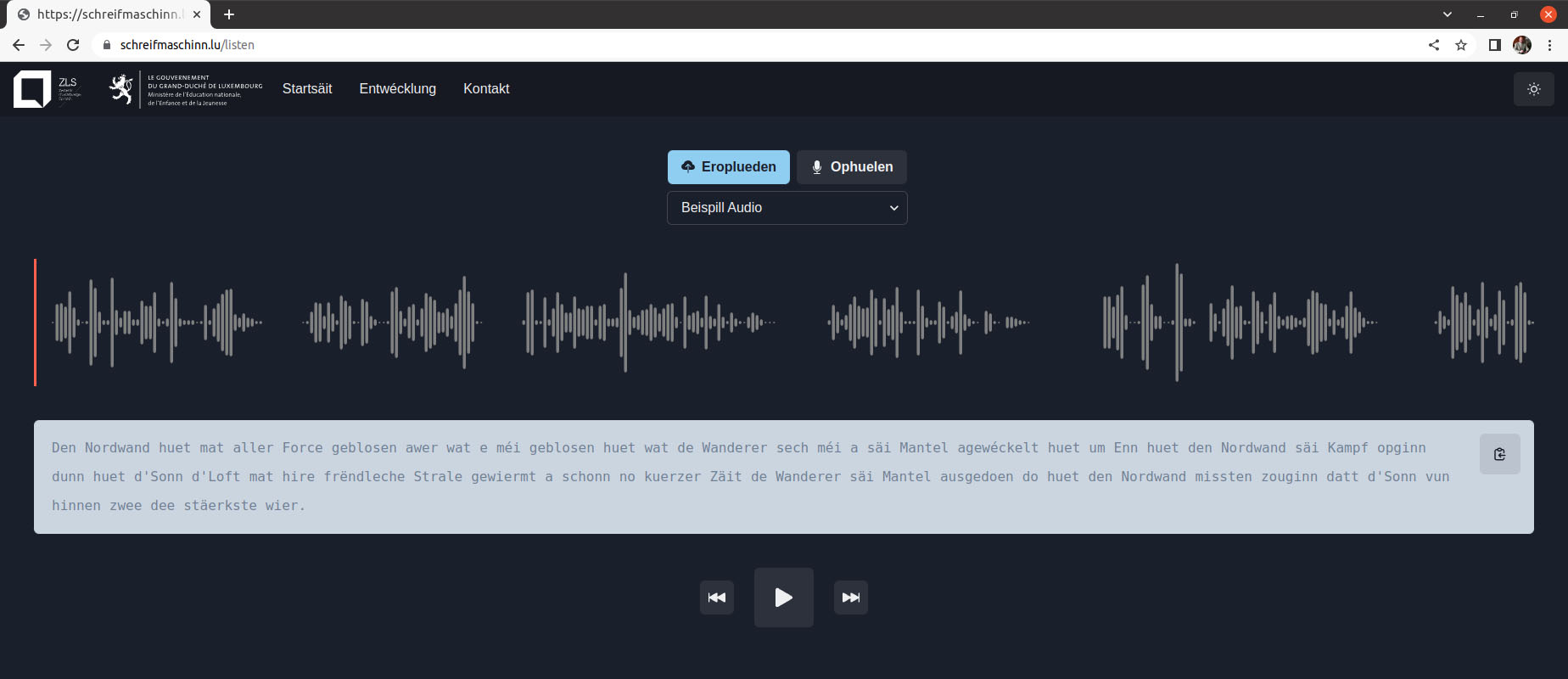
Pour évaluer les résultats des comparaisons, j’ai demandé conseil auprès d’un nouveau programme d’intelligence artificielle (AI) qui impressionne aussi bien les profanes techniques que les spécialistes AI, à savoir le robot ChatGPT, lancé récemment (version du 15 décembre 2022) par la société OpenAI. Ma première question était “How to evaluate the performance of an ASR system ?“. La réponse est détaillée et correcte :
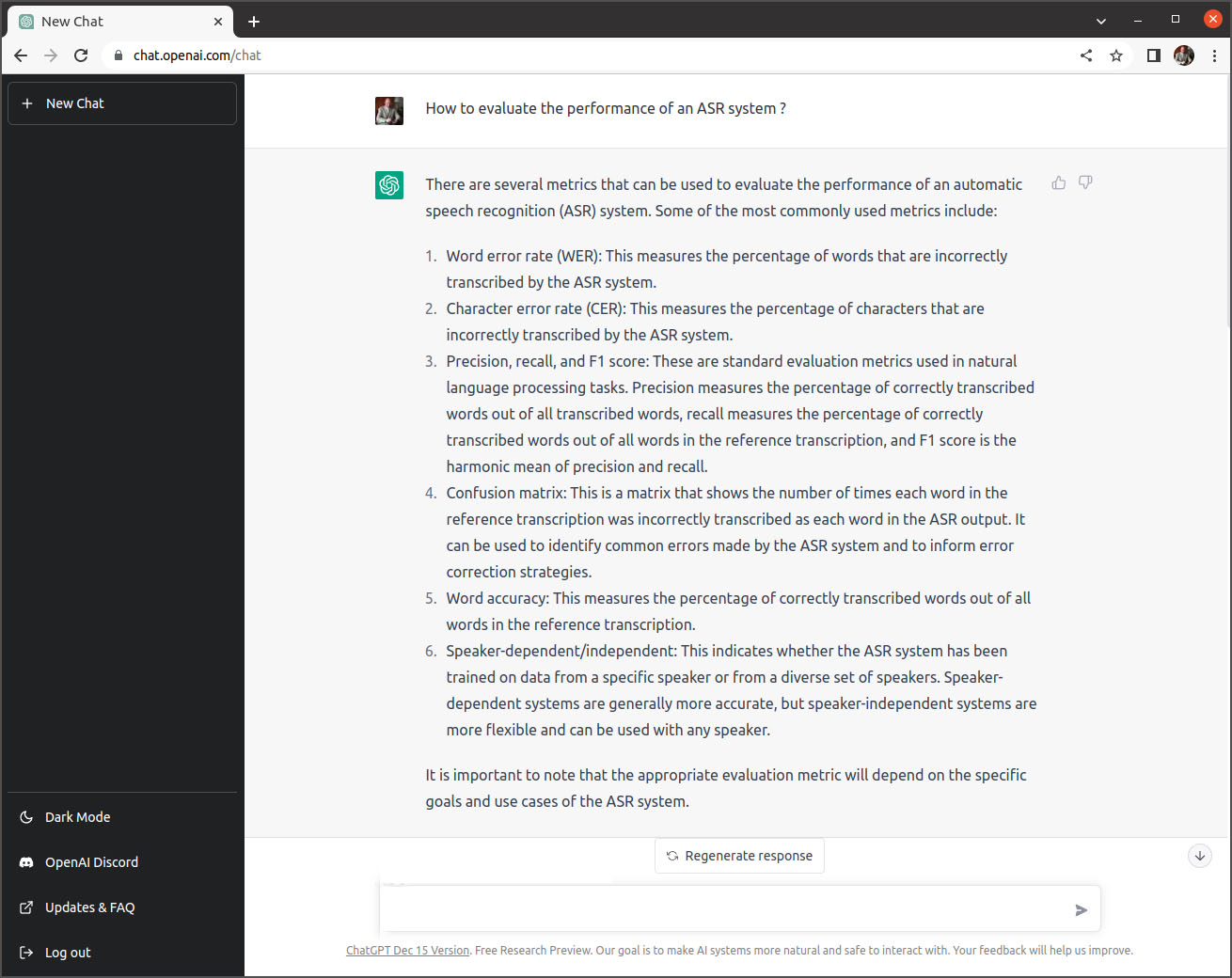
Comme deuxième question j’ai demandé des précisions sur la mesure du WER dans la même session: “How to measure the WER ?“. La réponse est explicite et comprend un exemple de calcul :
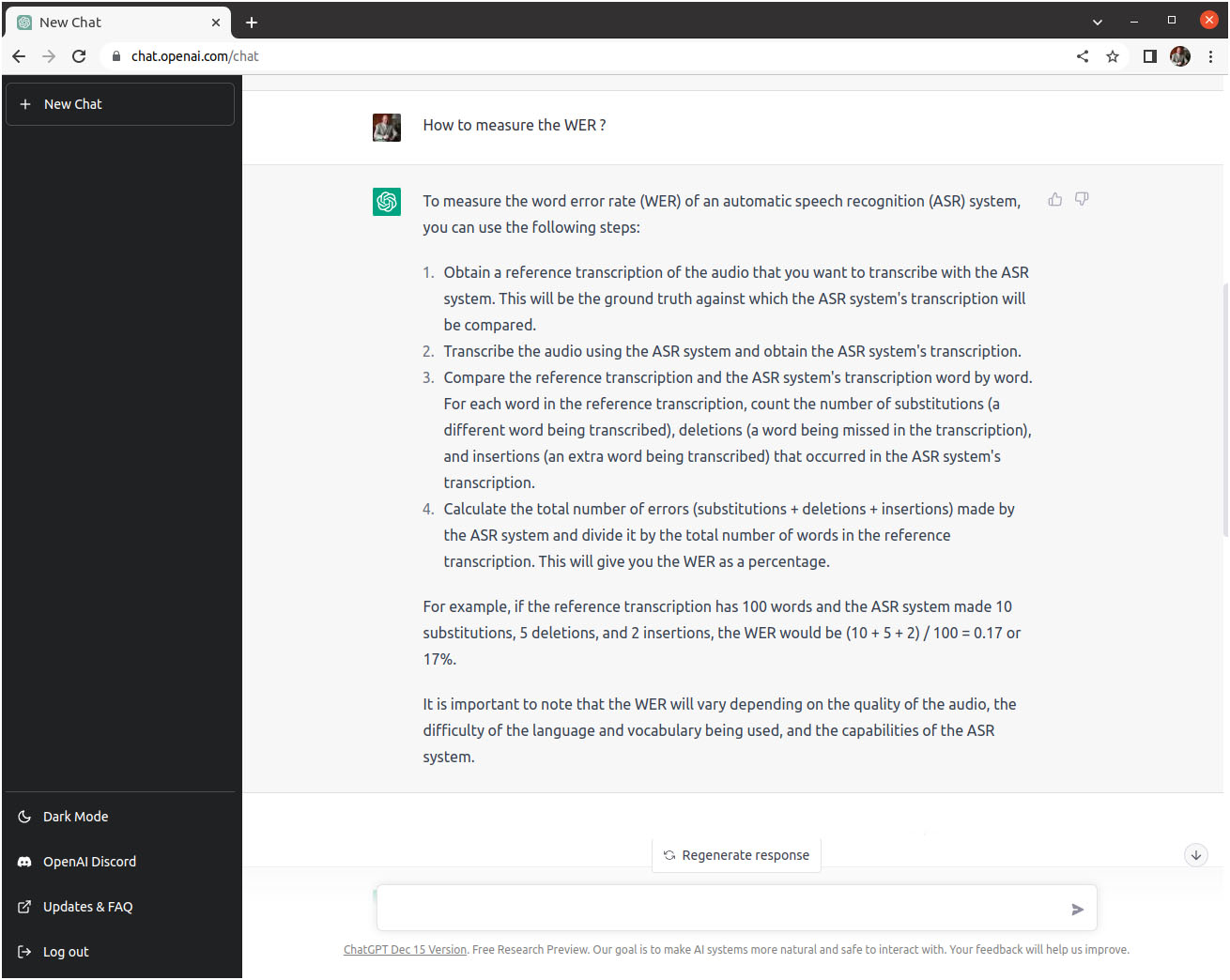
Je suis impressionné par cette application d’OpenAI. Pour obtenir ce genre d’informations dans le passé, j’étais obligé de faire des recherches sur Google, de visiter quelques sites web parmi les liens proposés et de formuler moi-même une synthèse des informations recueillies. ChatGPT facilite cette tâchreurs et offre un gain de temps appréciable.
Avec la confirmation que WER constitue un outil de mesure simple et valable, j’ai comparé les résultats fournis par schreifmaschinn.lu avec les transcriptions de référence des trois jeux de fichiers audio présentés ci-avant. Pour relever les erreurs, j’étais indulgent. Par exemple je n’ai pas compté des erreurs répétitives dans un même enregistrement plusieurs fois et j’ai compté une séquence de plusieurs fautes combinées comme une seule erreur. Comme je présente ci-après en détail les textes produits par schreifmaschinn.lu, avec les erreurs prises en compte marquées en rouge, ainsi que les transcriptions de référence, chacun est libre de faire ses propres interprétations et calculs.
Présentation des résultats détaillés
Les résultats détaillés des 3 jeux de fichiers audio sont relevés dans des tableaux ci-après dans 4 colonnes avec les contenus suivants:
- Identification de l’enregistrement
- Transcription de référence
- Texte reconnu par schreifmaschinn.lu
- Nombre d’erreurs / nombre de mots dans transcription de référence = taux d’erreurs en %
Premier jeu : enregistrements de dictées et d’émissions radio
| Spriecher | gebraddelten Text | geschriwwenen Text | WER |
| Caroline | A villen Industrielänner brénge Regierungen et net fäerdeg, Komma, hire Bierger plausibel ze erklären, | A villen Industrielänner brénge Regierungen et net fäerdeg kommen hire Bierger plausibel ze erklären. | 1 / 14 = 7,1% |
| Judith | D’Hieselter sinn a ganz Europa doheem, bis op den aacht-an-siechzegste Breedegrad, an a Klengasien. | D’ Hieselter sinn a ganz Europa doheem bis op den aachtasechzegste breede Grad an a kleng Asien. | 2 / 14 = 14,3% |
| Nathalie | Vläicht steet den Dag vun haut, wou eng ganz Natioun sech d’Fangere beim Diktat wond geschriwwen huet, och eng Kéier an de Geschichtsbicher, | Vläicht steet den Dag vun haut wou eng ganz Natioun sech d’Fangere beim Diktat Wont geschriwwen huet och eng Kéier an de Geschichtsbicher. | 1 / 23 = 4,3% |
| Sara | Mäi Bäcker geet mer op de Wecker, vu senge Bréidercher ass ee Bréitchen sou haart wéi dat anert. | Mäi Bäcker geet ma op de Becker vu senge Bréidercher ass ee Bréitchen esou haart wéi dat anert. | 2 / 18 = 11% |
| Guy | Et besteet also e groussen Ënnerscheed, wéi esou dacks, tëscht dem Wonschdenken an dem realisteschen Aschätze vun der politescher Situatioun; | Et besteet also e groussen Ënnerscheed wéi sou dacks tëscht dem Wonschdenken an dem realisteschen Aschätze vun der politescher Situatioun. | 0 / 20 = 0% |
| Jemp | E schafft, oder besser gesot, en ass am Ministère vun den ongeléiste Problemer. | E schafft oder besser gesot, en ass am Ministère vun den ongeléiste Problemer. | 0 / 13 = 0% |
| Luc | D’Manipulatioun zeechent sech jo doduerch aus, datt een déi Beaflossung net an Uecht hëlt. | Manipulatioun zeechent sech jo doduerch aus, datt een déi Beaflossung net an Nuecht hëlt. | 1 / 14 = 7,1% |
| Marco | D’Aféierung vum GSM ufanks de nonzeger Joren war fir d’Postverwaltung deen ambitiéiste Projet deen se bis dohin ënnerholl huet. | D’ Aféierung vum Gsm ufanks den nonzeger Joren war fir d’Post Verwaltung deen ambitiéise Projet se bis dohinner ënnerholl huet. | 3 / 19 = 15,8% |
Le taux de reconaissance des mots du premier jeu s’élève à 10 / 135 = 7,4%
Deuxième jeu : enregistrements de la Chambre des Députés
| Identification | gebraddelten Text | geschriwwenen Text | WER |
| Chambre-1 | Villmools merci, Här President, den Avis vun den Experten huet kloer gewisen, datt de Covid Kris nach net eriwwer ass, datt de Risk nach ëmmer do ass an datt d’Expektative fir September, zumindestens wat d’Experten ugeet, déi sinn, datt mer eventuell virun enger neier Well kënne stoen, wëlleg, op wëllegem Datum wëlleg Variante mat wëlleger Virulenz, wëlleger Ustiechlechkeet, dat wësse mer an dësem Moment selbstverständlech… | Deemools merci, Här President, den Avis vun den Experten huet kloer gewisen, datt de Covid Kris nach net eriwwer ass, dass de Risk nach ëmmer do ass an datt d’Expektative fir September, zumindestens wat d’Experten ugeet, déi sinn, datt mer eventuell virun enger neier Welt kënne stoen, wellech op wellechem Datum, Wellegvariant mat Wëllegevirulenze Wellecher ustiechlech geet, dat wësse mer an dësem Moment selbstverständlech. | 4 / 65 = 6,1% |
| Chambre-2 | Mir hunn eng Regierung an och an deene Rieden, déi bis elo gehal goufen, ass eigentlech, mengen ech keen op Impfniewewierkungen agaangen, mee dat ass e reelle Problem, wann Der mat villen Doktere schwätzt, soen déi Iech, datt se dee Problem, de Problematik vun den Impfniewenierkungen an hirer Praxis als e reelle Problem gesinn a mir mussen och de Leit, an sinn der ganz vill déi sech dorëm Suerge maachen, einfach dat Gefill ginn, dat mer dat eescht huelen, et musse Prozedure ginn, net bürokratesch Prozeduren … | Mir hunn eng Regierung an och mir an deene Rieden, déi bis elo gehal goufen, ass een, mengen ech, keen op d’Impf Niewewierkungen agaangen, mee dat ass e reelle Problem, wann Der mat villen Doktere schwätzt, soen déi Iech, datt se dee Problem, déi Problematik vun den imnieweniewe Wierkungen an hirer Praxis als e reelle Problem gesinn a mir mussen och de Leit an, sinn der ganz vill, déi sech dorëm Suerge maachen, einfach dat Gefill ginn, dat mat dat Eescht huelen? Et musse Prozedure ginn, net bürokratesch Prozeduren. | 5 / 86 = 5,8% |
| Chambre-3 | Ech denken, dass de Recul ons do wäert gutt doen an dass déi Evaluatioun, déi mer matmaachen, déi wärt eis mobiliséieren, mee dass déi eis Opschlëss gëtt, fir dann fir d’Zukunft eng gutt Gesetz en Place kënnen ze kréien, wou mer och aus den Erfarunge vun deenen anere Länner kënnen léieren, mmmh, ech wollt och nach agoen op déi Convin-Studie, déi ass ugeschwat ginn, jo, déi ass iwwerholl ginn, vun der Orchestra, dat leeft nach ëmmer, d’Resultater vun de Januar, Februar sinn eran, sinn nach net statistesch ausgewäert, mee dat leeft u sech riit weider. | Ech denken, dass en de Recul ons do wäert gutt doen an dass déi Evaluatioun, wou mer matmaachen, iwwert eis mobiliséieren, mee dass déi eis opschlëssgëtt, fir da fir d’Zukunft eng gutt Gesetze en place kënnen ze kréien, wou mer och eis Erfarunge vun deenen anere Länner kënnen léieren a ech wollt och nach agoen op Dekonvinsstudien, déi ass ugeschwat ginn, jo, di ass iwwerholl ginn, vun der Okestrachtut, dat leeft nach ëmmer d’Resultater vun de Januar, Februar sinneratean net statistesch ausgewäert, mee dat leeft u sech Riad weider. | 12 / 95 = 12.7% |
| Chambre-4 | Leider kënne mer dat net maachen, well eis Iwwerzeegung ass déi, datt mer keng Impfflicht wëllen, Dir wollt de proposéiert an de Mentiounen avant projet de loi ebe just fir eng Impflicht der Chamber virzeleeën, do hu mer einfach eng fundamental aner Vue mir sin fir d’Fräiwëllegkeet vun der Impfung, wëllen also och keen esou en avant projet de loi, mir kënnen also net mat ënnerstëtzen, mee nach eng Kéier en häerzlechen Merci och fir Är Oppenheet gëintiwwert den Oppositiounsparteien. Merci. | Leider kënne mer dat net maachen, well eis Iwwerzeegung ass déi, datt mer keng Impfflicht wëllen, Dir wollt dee proposéiert an de Motiounen a ven Projet de loi ebe just fir eng Impflicht der Chamber virzeleeën, do hu mer e fir eng fundamental aner Vue mir sin fir d’Fräiwëllegkeet vun der Impfung wëllen also och keen esou en Aven Projet de loi, mir kënne se also net mat ënnerstëtzen, mir neien Kieren Hercleche merci och fir Är Oppenheet geet iwwert de Oppositiounspartei Merci. | 5 / 81 = 6,2% |
| Chambre-5 | Do ass vun Exzellenz Zenteren geschwat ginn, nun Branche an der Ekonomie, déi gutt forméiert Leit brauchen a mir verstinn net wéi mer probéieren op där enger Säit Secteuren ze developpéieren, wou héich qualifizéiert Leit sollen herno eng Aarbecht fannen, op där anerer Säit probéiere mer dat Mëttelméissegkeet an eiser Schoul zum Standard, zum Standard gëtt, dat passt op jidde Fall net iwwerteneen, esou kréie mer weeder déi richteg Leit forméiert, fir an deene Secteuren täteg ze sinn an esou kréie mer weeder … | Do ass vun Exzellenz Zentere geschwat ginn, nu Branche an der Ekonomie, déi gutt forméiert Leit brauchen a mir verstinn net wéi mer probéieren op där enger Säit Secteuren ze developpéieren, wou héich qualifizéiert Leit sollen herno eng Aarbecht fannen op där anerer Säit probéiere mer dat Mëttelméissegkeet an eiser Schoul et zum Standard, zum Standargëtt, dat passt op jidde Fall en net iwwerteneen, esou kréie mer weeder déi richteg Leit forméiert, fir an deene Secteuren täteg ze sinn an esou kréie mer weeder. | 4 / 83 = 4,8% |
| Chambre-6 | Här President, d’Ried vum Premierminister huet den Tour vun enger Partie vu wichtege Problemer vum moderne Lëtzebuerg gemaacht, et war jo och kloer gesot ginn, dass dëst en Astig war an eng Debatt, déi Mëtt November weidergeet mat deem wat mer han dann hei an der Chamber iwwert den nationale Plang am Kader vun der Lissabonstrategie … | E President, d’Ried vum Premierminister huet den Tour vun enger Partie vu wichtege Problemer vum moderne Lëtzebuerg gemaacht, etwar jo och kloer gesot ginn, dass dëst en Astig war an eng Debatt, déi Mëtt November weidergeet mat deem wat mer a dann hei an der Chamber iwwert den nationale Plang am Kader vun der Lissabonstrategie. | 3 / 56 = 5,4% |
Le taux de reconnaisance des mots du deuxième jeu s’élève à 33 / 466 = 7,1%
Troisième jeu : enregistrements à domicile avec bruit de fond
Nordwand-1 : texte de référence:
An der Zäit hunn sech den Nordwand an d’Sonn gestridden, wie vun hinnen zwee wuel méi staark wier, wéi e Wanderer, deen an ee waarme Mantel agepak war, iwwert de Wee koum. Si goufen sech eens, datt deejéinege fir dee Stäerkste gëlle sollt, deen de Wanderer forcéiere géif, säi Mantel auszedoen.
| Identification | geschriwwenen Text | WER |
| Nordwand 1: sans bruit de fond | An der Zäit hunn sech den Nordwand an d’Sonn gestridden wie vun hunnen zwee wuel méi staark wier wéi e Wanderer deen an ee waarme Mantel agepaakt war iwwert de Wee koum si goufe sech eens datt deejéinege fir dee stäerkste gëlle sollt deen de Wanderer forcéiere géif säi Mantel auszedoen. | 2 / 51 = 3,9% |
| Nordwand 1: bruit enfants 0db peak | An der Zäit hu sech den Loft Wand an Son gestridden wie vun hinnen zwee wuel méi staark wier wéi e Wanderer deen an de waarme Wandel agepakt war iwwert de Wee koum si goufe sech eens datt deejéinege fir dee stäerkste gëlle sollt deen de Wanderer forcéiere géif säi Mantel auszedoen. | |
| Nordwand 1: bruit enfants -10db peak | An der Zäit hu sech den Noftwand an d’Sonn gestridden wie vun hunnen zwee wuel méi staark wier wéi e Wanderer deen an ee waarme Mantel agepaakt war iwwert de Wee koum si goufe sech eens datt deejéinege fir dee stäerkste gëlle sollt deen de Wanderer forcéiere géif säi Mantel auszedoen. | |
| Nordwand 1: bruit enfants -20db peak | An der Zäit hunn sech den Nordwand an d’Sonn gestridden wie vun hunnen zwee wuel méi staark wier wéi e Wanderer deen an ee waarme Mantel agepaakt war iwwert de Wee koum si goufe sech eens datt deejéinege fir dee stäerkste gëlle sollt deen de Wanderer forcéiere géif säi Mantel auszedoen. | 2 / 51 = 3,9% |
Nordwand-2 : texte de référence:
Den Nordwand huet mat aller Force geblosen, awer wat e méi geblosen huet, wat de Wanderer sech méi a säi Mantel agewéckelt huet. Um Enn huet den Nordwand säi Kampf opginn. Dunn huet d’Sonn d’Loft mat hire frëndleche Strale gewiermt, a schonn no kuerzer Zäit huet de Wanderer säi Mantel ausgedoen. Do huet den Nordwand missen zouginn, datt d’Sonn vun hinnen zwee dee Stäerkste wier.
| Identification | geschriwwenen Text | WER |
| Nordwand 2: sans bruit de fond | Den Nordwand huet mat aller Force geblosen awer wat e méi geblosen huet wat de Wanderer sech méi a säi Mantel agewéckelt huet um Enn huet den Nordwand säi Kampf opginn dunn huet d’Sonn d’Loft mat hire frëndleche Strale gewiermt a schonn no kuerzer Zäit de Wanderer säi Mantel ausgedoen do huet den Nordwand missten zouginn datt d’Sonn vun hinnen zwee dee stäerkste wier. | 2 / 65 = 3,1% |
| Nordwand 2: bruit sèche-cheveux 0db peak | Neeee Eeelere eenee. | |
| Nordwand 2: bruit sèche-cheveux -10db peak | Den Nord dann gëtt en aller a Eiese a Eegeninteresse geheien Eau huet d’Sonn oft mat hire frendleche Strale Gewienaschonn e Dezembere Anne ausgedoe huet den No Tandis zou ginn dat ëneen zwee beschte wier. | |
| Nordwand 2: bruit sèche-cheveux -20db peak | Den Nordwand huet mat aller Force geblosen awer wat e méi geblosen huet wat de Wanderer sech méi a säin Mandel agewéckelt hierum Enn huet den Nord a säi Kand dunn huet d’Sond d’Loft mat hire frëndleche Strale gewiert a schonn no kuerzer Zäit de Wanderer säi Mantel ausgedoen do huet den Nordwand missten zouginn datt d’Sonn vun hinnen zwee dee stäerkste wier. | |
| Nordwand 2: bruit sèche-cheveux -30db peak | Den Nordwand huet mat aller Force geblosen awer wat e méi geblosen huet wat de Wanderer sech méi a säi Mantel agewéckelt huet um Enn huet den Nordwand säi Kampf opginn dunn huet d’Sonn d’Loft mat hire frëndleche Strale gewiermt a schonn no kuerzer Zäit de Wanderer säi Mantel ausgedoen do huet den Nordwand missten zouginn datt d’Sonn vun hinnen zwee dee stäerkste wier. | 2 / 65 = 3,1% |
Conclusions
Pour l’évaluation globale je n’ai pas considéré les résultats des enregistrements avec un bruit de fond élevé. Pour le calcul du WER moyen pour mon test complet je me suis de nouveau adressé au modèle AI ChatGPT, avec la question suivante: “What is the WER if I found 51 errors for 833 words in the reference transcriptions ?“.
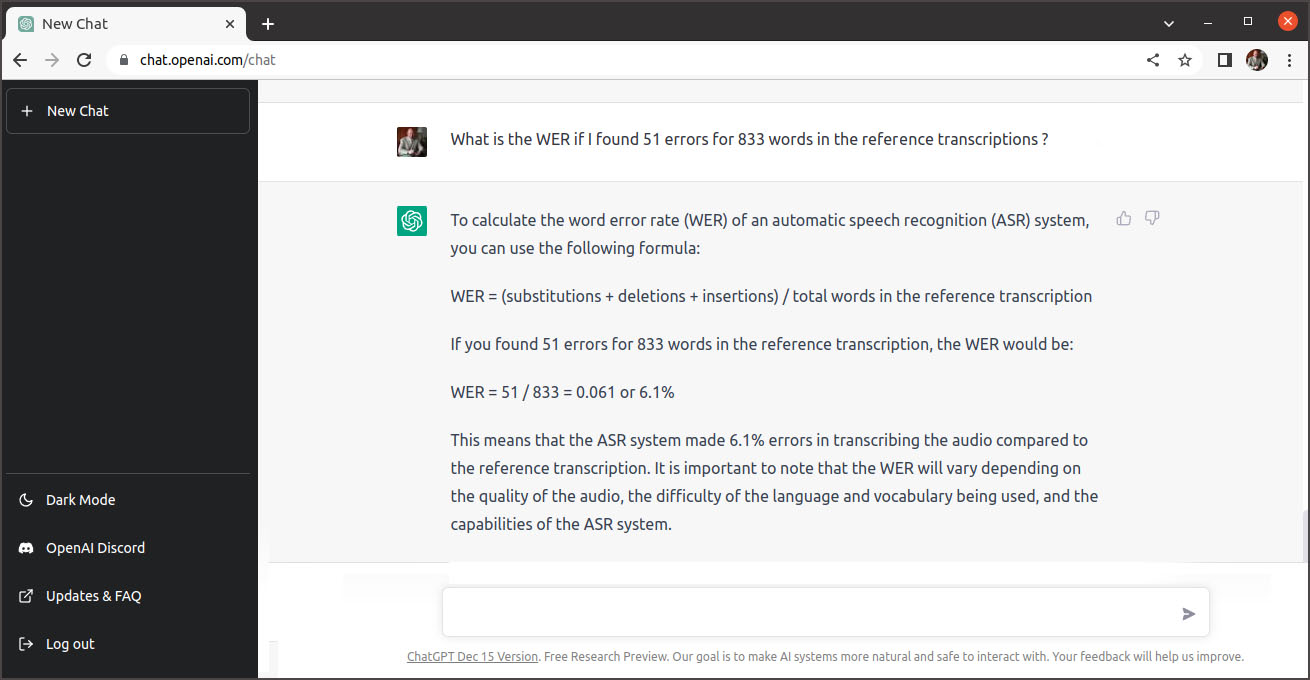
ChatGPT va remplacer ma calculatrice. J’ai demandé l’avis du ChatGPT au sujet du résultat avec la question “Is this WER value good or bad for a low resource language ASR system ?“.
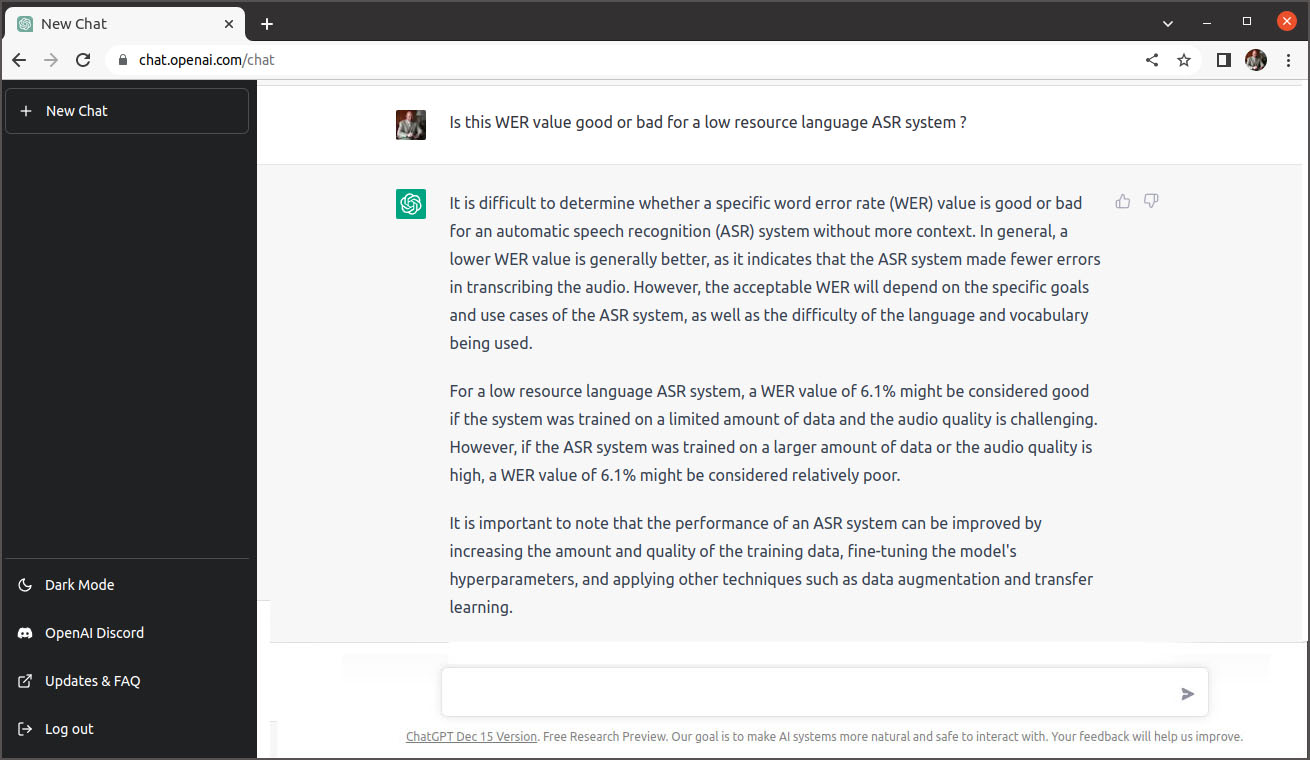
Je me rallie à cet avis et j’attribue cinq étoiles à l’application actuelle schreifmaschinn.lu. Pour terminer, j’ai demandé l’opinion personnelle de ChatGPT concernant le résultat. Voici sa réponse:
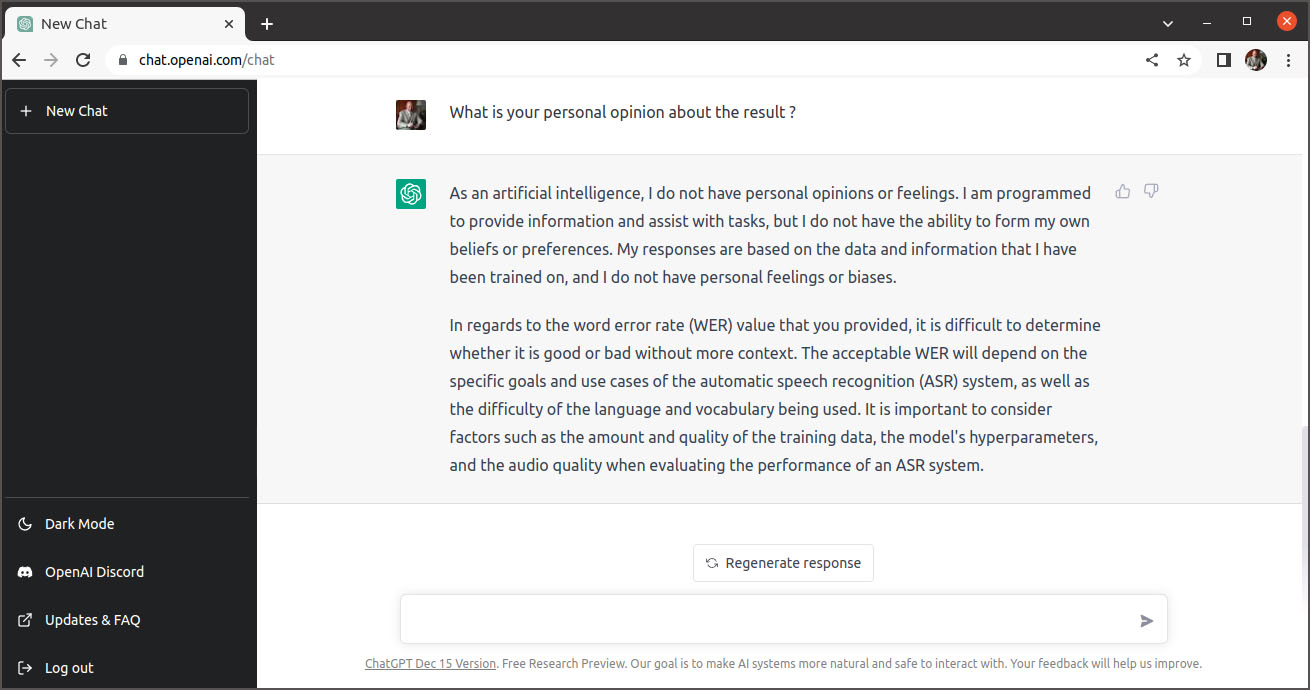
Il n’y a rien à ajouter!
Bibliographie
- Aus Wörtern Text machen, Télécran, 17.12.2022
- Lëtzebuerger Sproocherkennung mat Schreifmaschinn.lu, RTL.lu, 15.12.2022
- Was hat der neue, digitale „Sproochmates“ drauf?, Luxemburger Wort, 15.12.2022
- La reconnaissance vocale du luxembourgeois en démonstration vidéo, l’Essentiel 14.12.2022
- Reconnaissance vocale – pour le luxembourgeois aussi !, MEN, 9.12.2022
- Improving Luxembourgish Speech Recognition with Cross-Lingual Speech Representations, Le Minh Nguyen, 9.9.2022
- Leminh Nguyen: Improving Luxembourgish speech recognition performance, rug.nl, 20.4.2022